本文翻译自 Sebastian Raschka 的文章 A Visual Guide to Attention Variants in Modern LLMs,原文发布于 2026 年 3 月 22 日。文中图片均引自原文及其参考资料,专业名词保留原文英文。
本文整理了近年来在主流开放权重模型中实际使用的各类 Attention 变体,既作为参考资料,也作为轻量级学习材料。
1. Multi-Head Attention(MHA)
Self-attention 让序列中每个 token 都能看到其他可见 token,为它们分配权重,并用这些权重构建新的上下文感知表示。
Multi-Head Attention(MHA)是标准 Transformer 版本:并行运行多个 self-attention head,每个 head 使用不同的可学习投影矩阵,最终将所有 head 的输出合并为一个更丰富的表示。
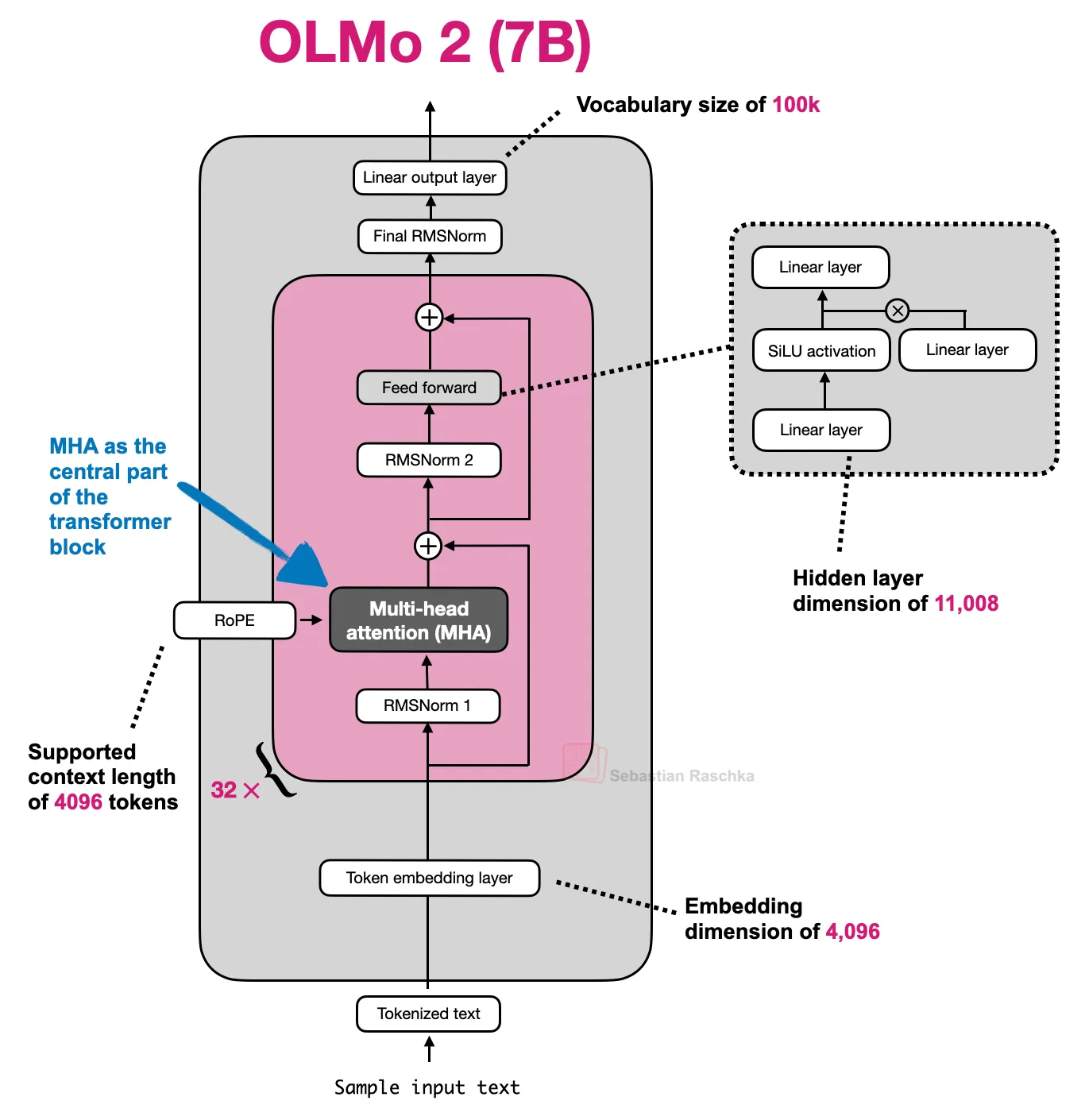
典型使用模型:GPT-2、OLMo 2 7B、OLMo 3 7B
1.1 Attention 的历史背景
Attention 机制早于 Transformer 和 MHA 出现,最初应用于翻译任务的 encoder-decoder RNN。
在早期系统中,encoder RNN 逐 token 读入源句子,将其压缩为一系列 hidden state,最简单的情况下压缩为一个最终 state。然后 decoder RNN 需要从这个有限的摘要中生成目标句子。对于短句这样还行,但当下一个词所需的相关信息位于输入句子的其他位置时,瓶颈就显现了。
核心局限在于:hidden state 无法存储无限量的信息和上下文,有时候能直接回查完整输入序列会更有帮助。
下图的翻译示例展示了这种思路的局限性:即使很多局部词汇选择看起来合理,模型仍可能因为过于按词对词映射而错过句子级结构。图中的上半部分是一个刻意夸张的逐词翻译示例,用来说明问题;真实 RNN 不一定会如此机械,但在更长序列或需要检索更远信息时,单一 hidden state 的瓶颈仍会暴露出来。
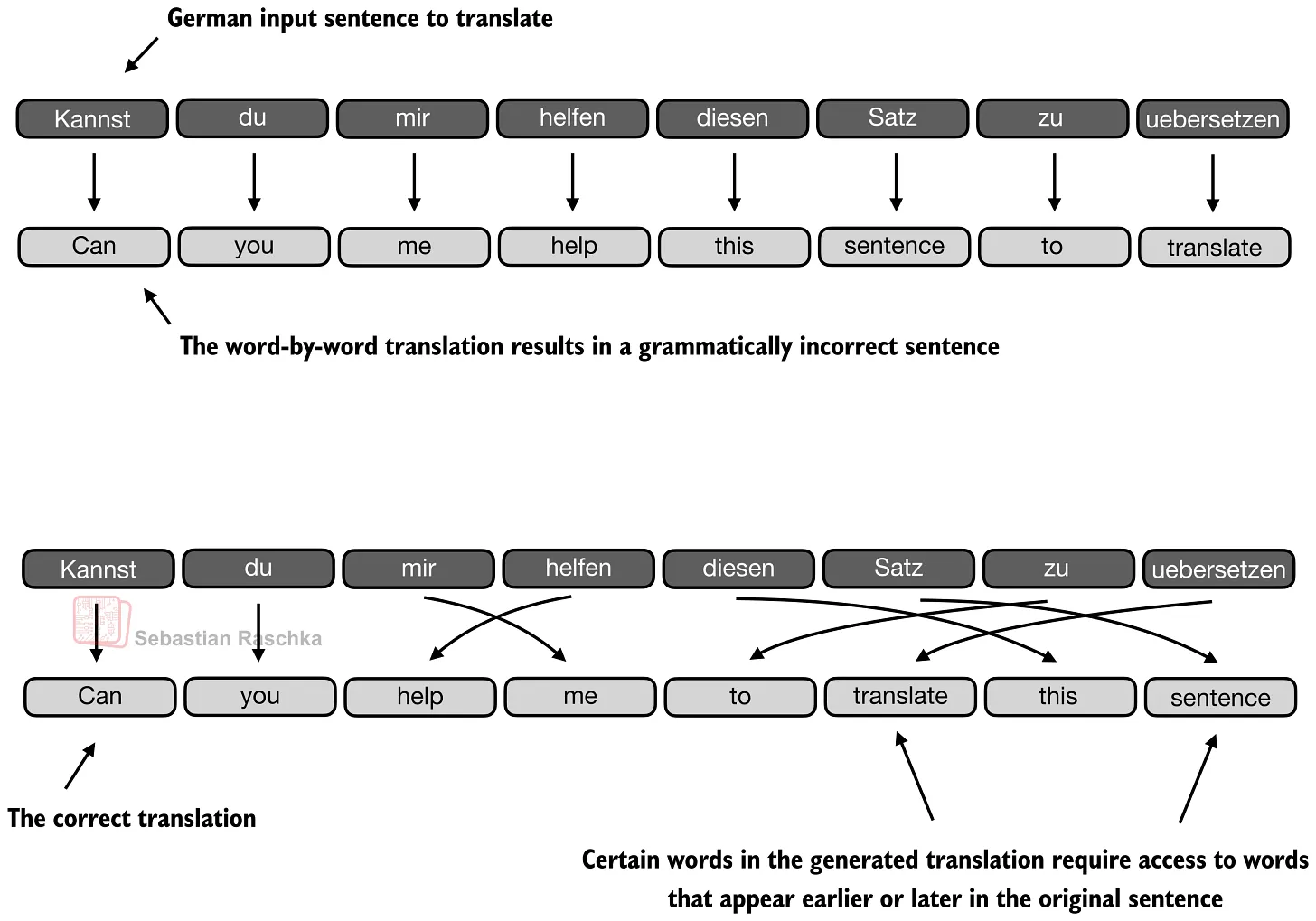
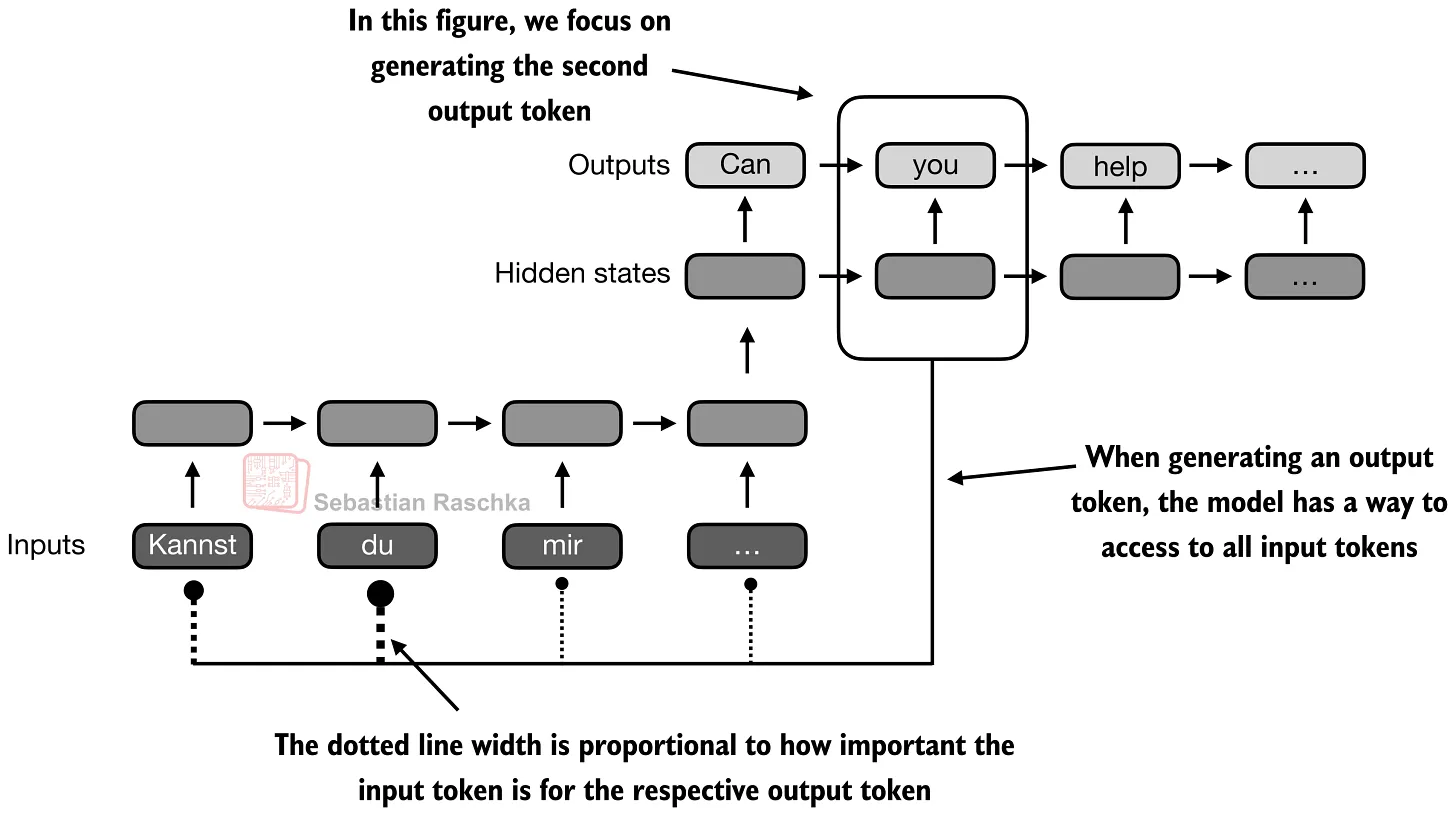
Transformer 保留了上述 Attention-RNN 的核心思想,但去除了循环结构。在经典论文 Attention Is All You Need 中,Attention 本身成为主要的序列处理机制(而不只是 RNN encoder-decoder 的一部分)。
在 Transformer 中,这个机制被称为 self-attention:序列中每个 token 对所有其他 token 计算权重,并用这些权重将来自其他 token 的信息混合到新表示中。Multi-head attention 就是将这一机制并行运行多次。
1.2 Masked Attention 矩阵
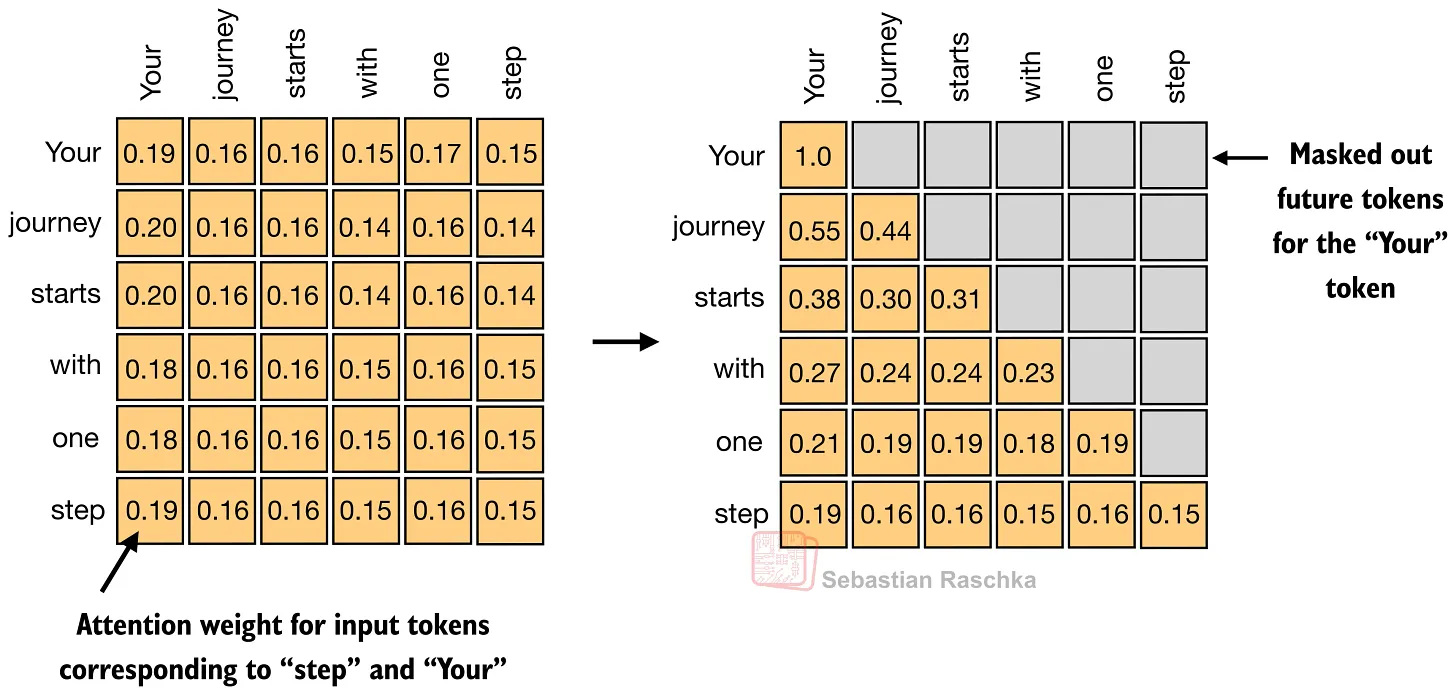
对于长度为 T 的序列,attention 需要为每个 token 生成一行权重,因此整体上得到一个 T × T 的矩阵。
每一行回答一个简单问题:在更新当前 token 时,每个可见 token 应该有多重要?在 decoder-only LLM 中,未来位置会被 mask 掉,因此矩阵右上角是灰色的。
Self-attention 的本质是在因果 mask 下学习这些 token-to-token 权重模式,并用它们构建上下文感知的 token 表示。
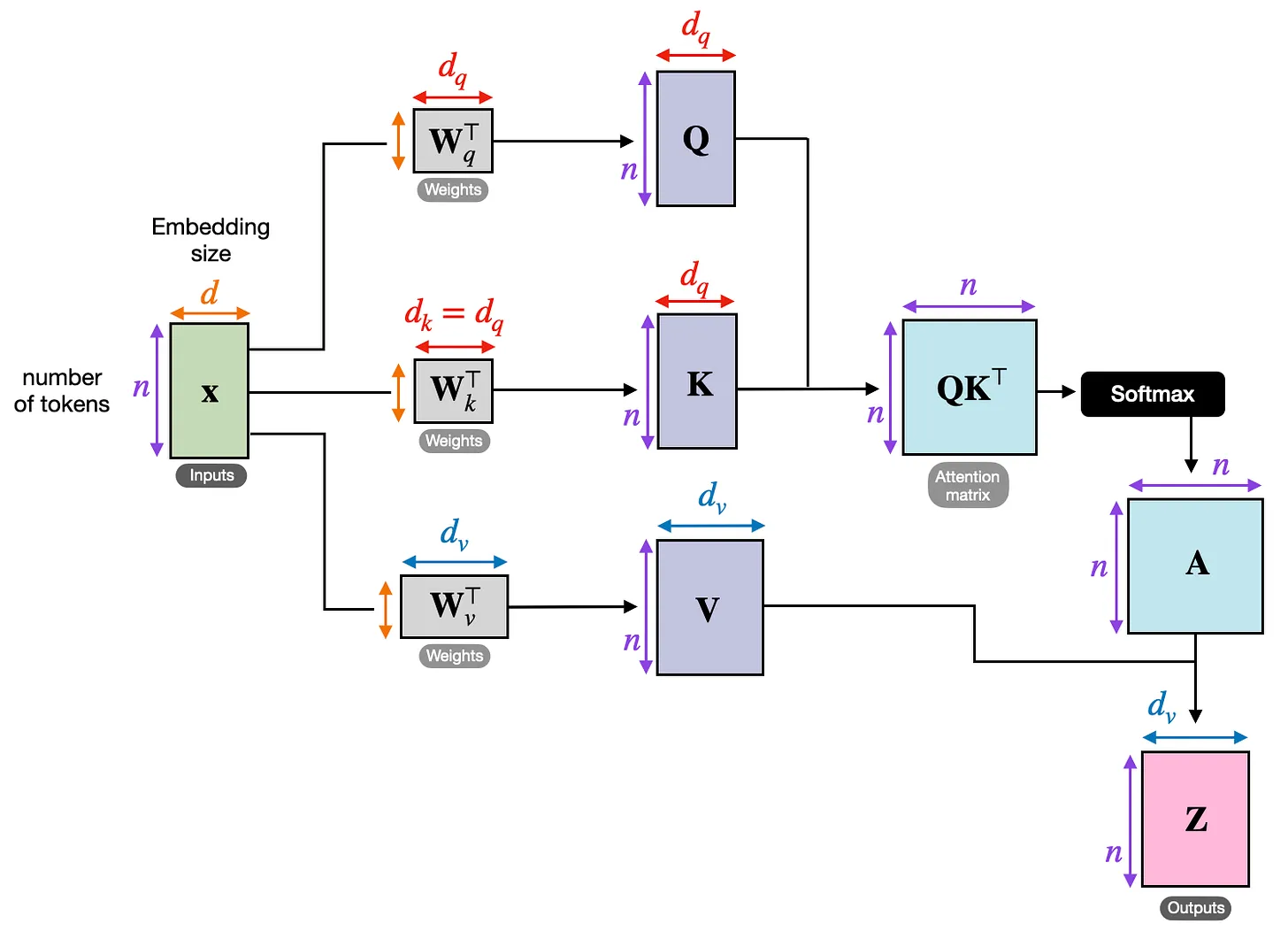
1.3 Self-Attention 内部机制
Transformer 从输入 embedding X 计算 attention 矩阵 A,再用 A 生成变换后的输出 Z。
其中 Q、K、V 分别代表 queries、keys、values:
- query 表示当前 token 在寻找什么
- key 表示每个 token 提供了什么可供匹配的信息
- value 是一旦 attention 权重计算完成后,被混合进输出的实际信息
计算步骤如下:
Wq、Wk、Wv是将输入 embedding 投影到Q、K、V的权重矩阵QKᵀ产生原始的 token 间相关性得分- softmax 将这些得分转换为归一化的 attention 矩阵
A - 将
A作用于V,得到输出矩阵Z
注意 attention 矩阵不是手工编写的对象,它从 Q、K 和 softmax 中涌现出来。
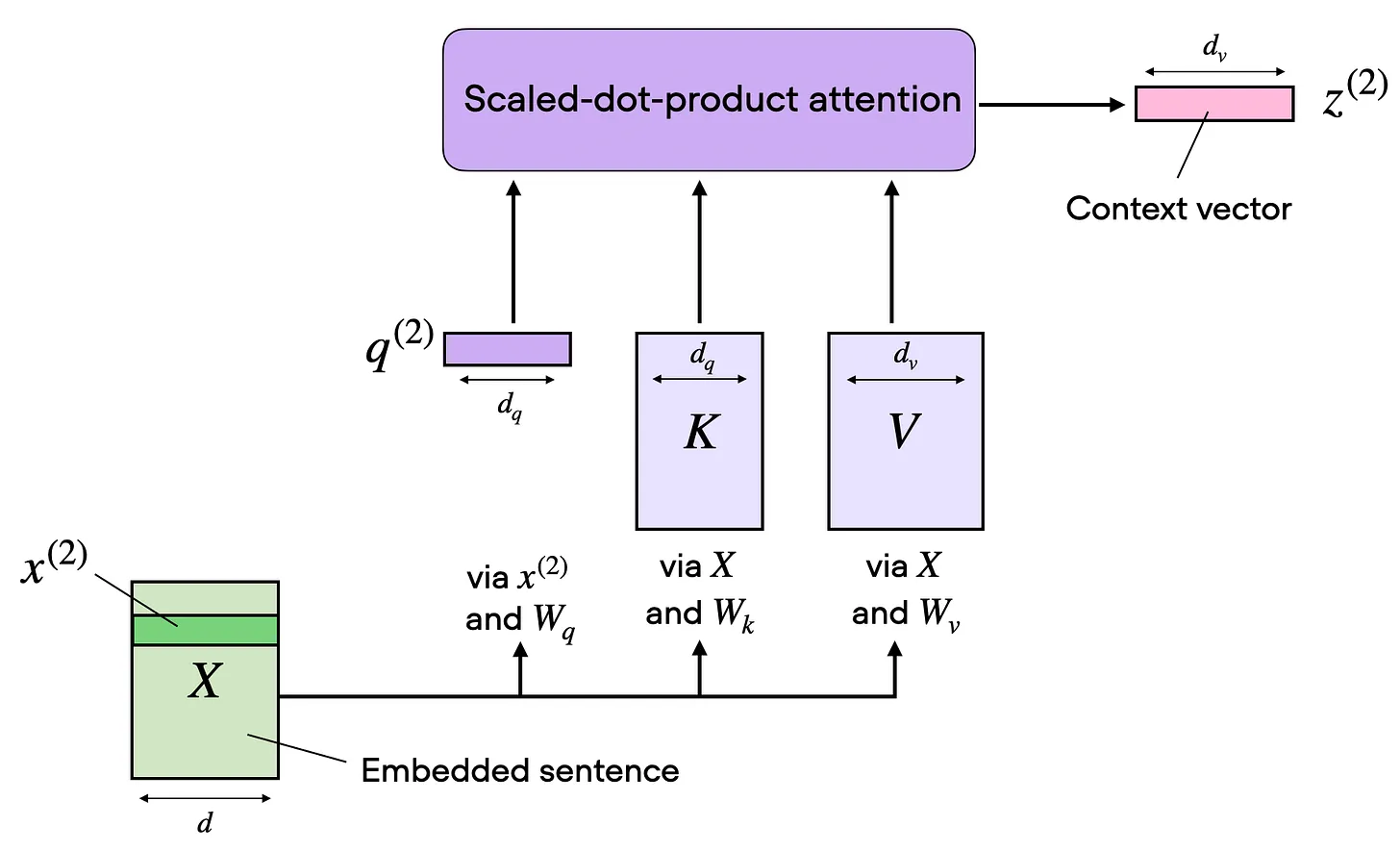
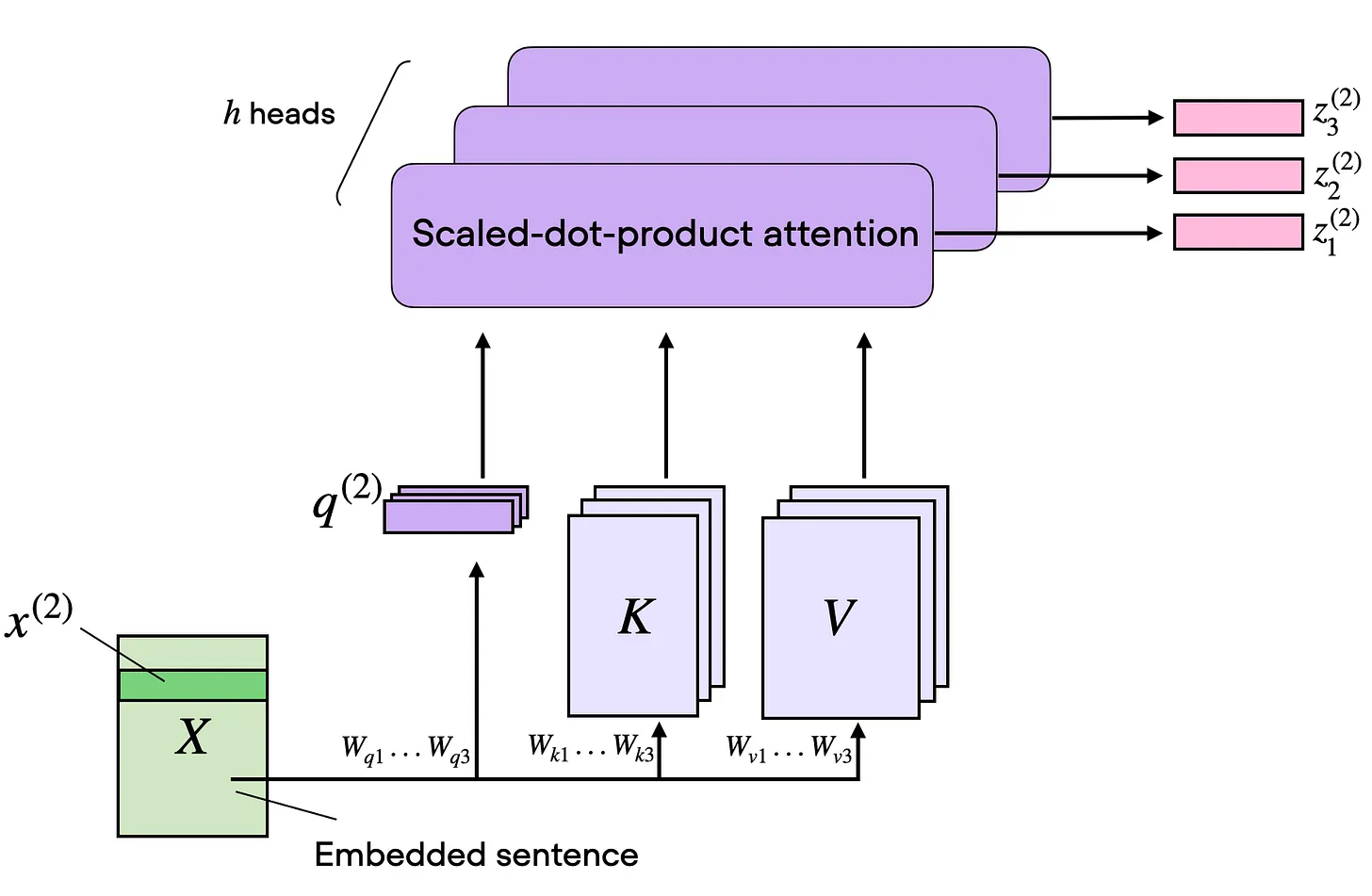
1.4 从单 Head 到 Multi-Head Attention
一组 Wq/Wk/Wv 矩阵给我们一个 attention head,对应一个 attention 矩阵和一个输出矩阵 Z。
MHA 只是用不同的可学习投影矩阵,并行运行多个这样的 head。
这样做的好处是不同 head 可以专注于不同的 token 关系:一个 head 可能关注短距离局部依赖,另一个关注更宏观的语义联系,还有一个可能关注位置或句法结构。
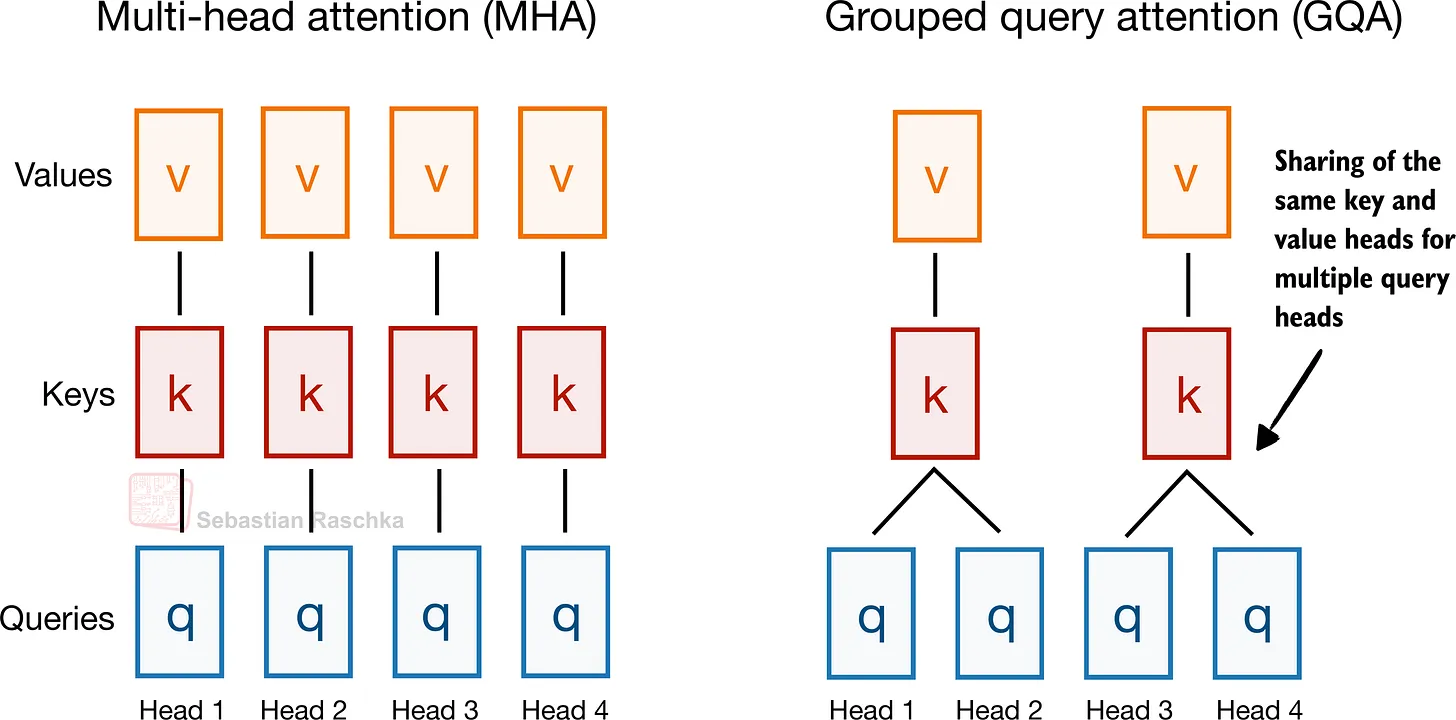
2. Grouped-Query Attention(GQA)
GQA 是从标准 MHA 派生出来的 attention 变体,由 Joshua Ainslie 等人在 2023 年论文 GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints 中提出。
它不为每个 query head 单独分配 keys 和 values,而是让多个 query head 共享同一套 key-value 投影,从而在不大幅改变 decoder 结构的前提下,大幅降低 KV cache 的成本(主要是内存上的节省)。
典型使用模型:
- Dense: Llama 3 8B、Qwen3 4B、Gemma 3 27B、Mistral Small 3.1 24B、SmolLM3 3B、Tiny Aya 3.35B
- Sparse (MoE): Llama 4 Maverick、Qwen3 235B-A22B、Step 3.5 Flash 196B、Sarvam 30B
2.1 GQA 为何流行
标准 MHA 为每个 head 单独维护 keys 和 values,从建模角度更优,但在推理时需要在 KV cache 中保存所有这些状态,成本高昂。
GQA 保留较多的 query head,但减少 key-value head 的数量,让多个 query 共享它们。这降低了参数量和 KV cache 的访问流量,同时不像 MLA 那样需要复杂的实现改动。
在实践中,对于那些想要比 MHA 更便宜、但比 MLA 等压缩方案更简单实现的团队,GQA 是非常受欢迎的选择。
2.2 GQA 的内存节省效果
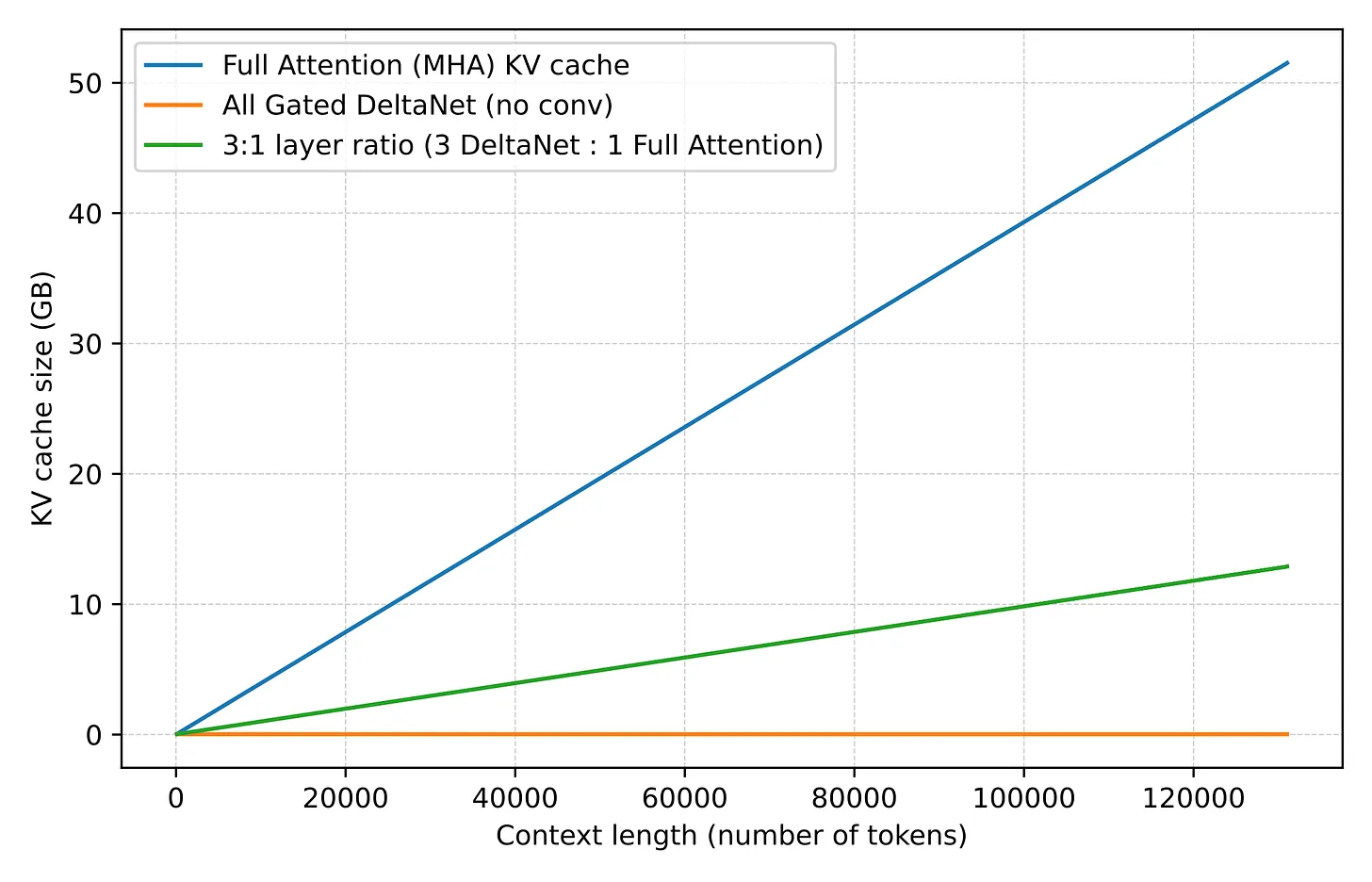
GQA 在 KV 存储上带来了显著节省:每层保留的 key-value head 越少,每个 token 需要缓存的状态就越少。这就是为什么随着序列长度增长,GQA 的优势越来越明显。
GQA 是一个连续谱:如果一路减少到只有一个共享 K/V 组,就进入了 Multi-Query Attention(MQA)的领域——成本更低,但建模质量可能下降更明显。通常甜蜜点在 MQA(1个共享组)和 MHA(K/V组数等于query数)之间,缓存节省显著但相对 MHA 的建模质量下降有限。
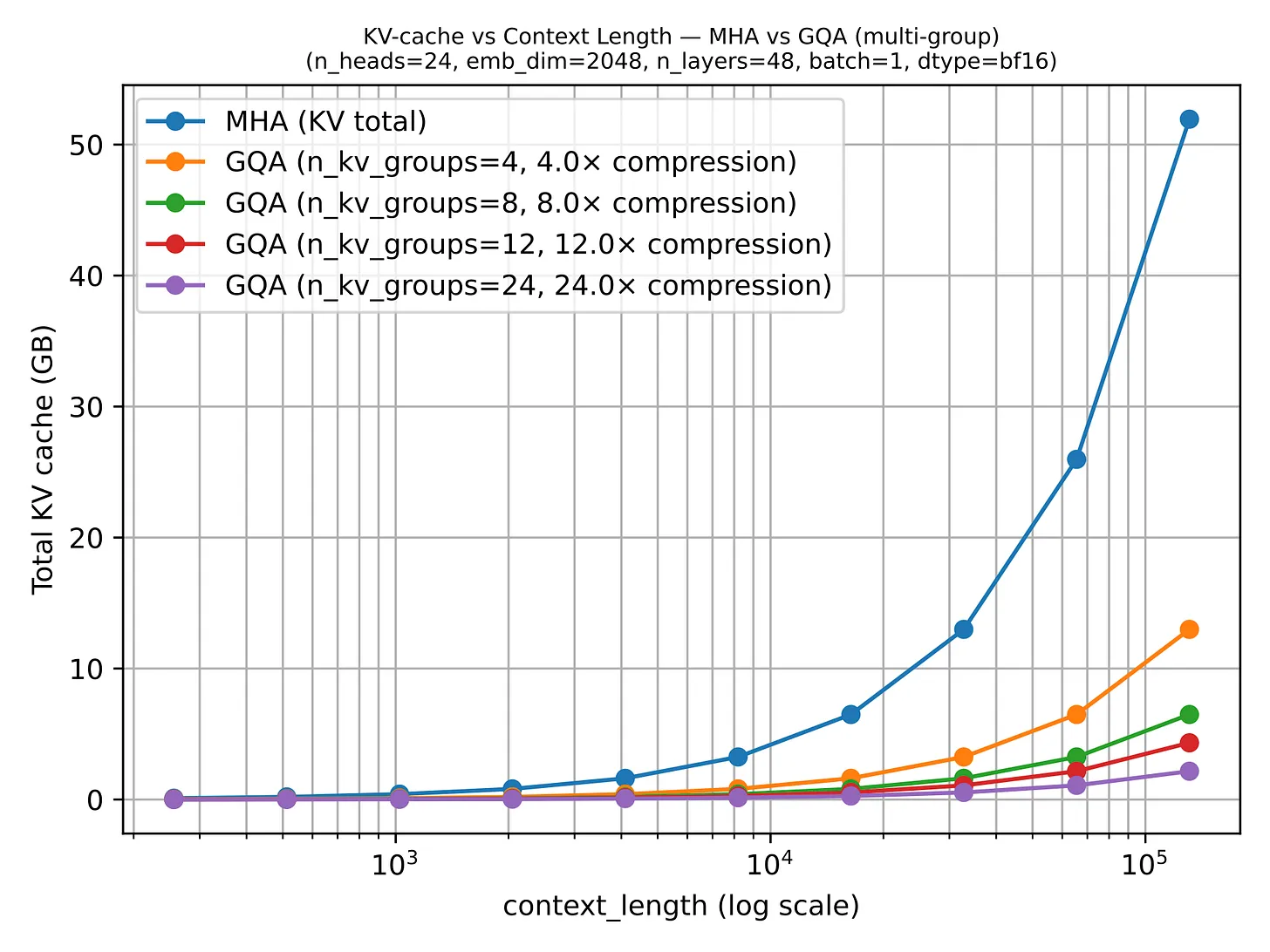
2.3 GQA 在 2026 年仍然重要
MLA 等更先进的变体正在流行,因为它们能在相同 KV 效率水平下提供更好的建模性能(如 DeepSeek-V2 论文中的 ablation 研究所示),但实现与服务也更复杂。
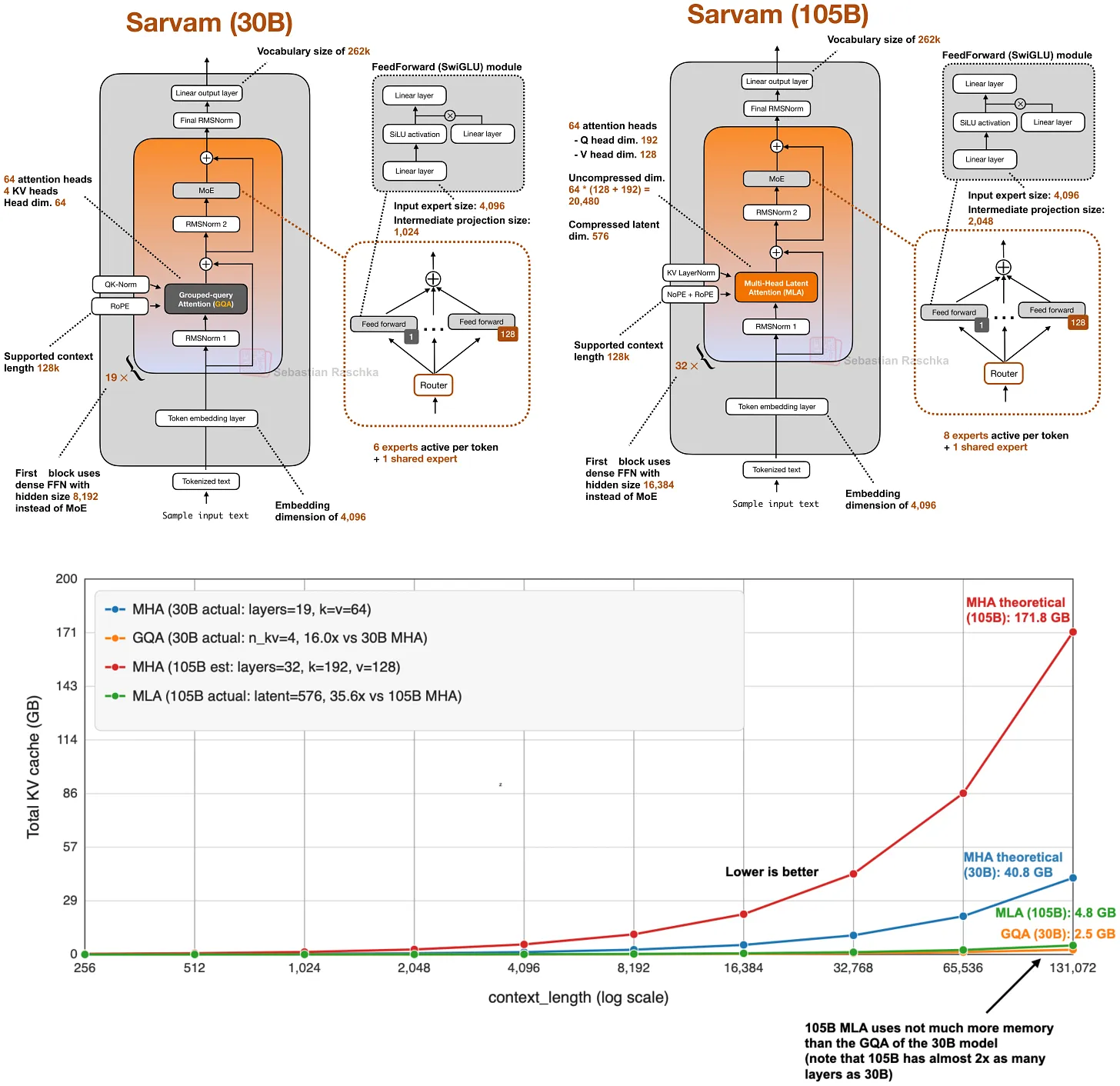
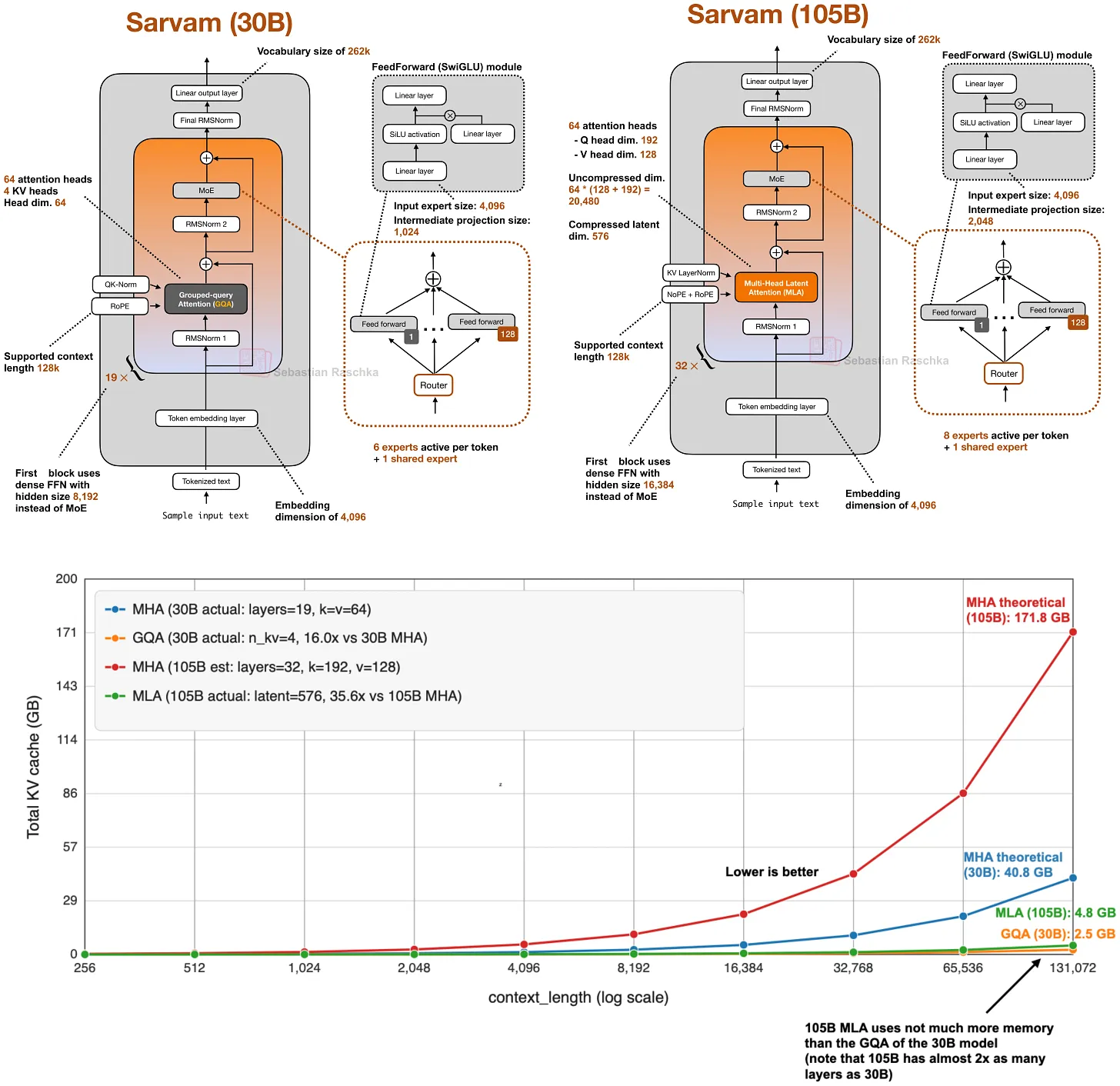
GQA 之所以仍然有吸引力,是因为它鲁棒、易于实现,也更容易训练(hyperparameter tuning 的需求更少)。这也是为什么一些新发布的模型仍然选择坚守 GQA。Sarvam 是一个很好的对比案例:30B 版本使用 GQA,而 105B 版本切换到了 MLA。
原文还点名提到 MiniMax M2.5 与 Nanbeige 4.1,作为仍然坚持经典 GQA 而未叠加更多效率技巧的例子。
3. Multi-Head Latent Attention(MLA)
MLA 的动机与 GQA 类似,都是为了减少 KV cache 的内存需求。区别在于:GQA 通过减少存储的 K/V 数量来缩小 cache,而 MLA 通过压缩存储的内容来缩小 cache。
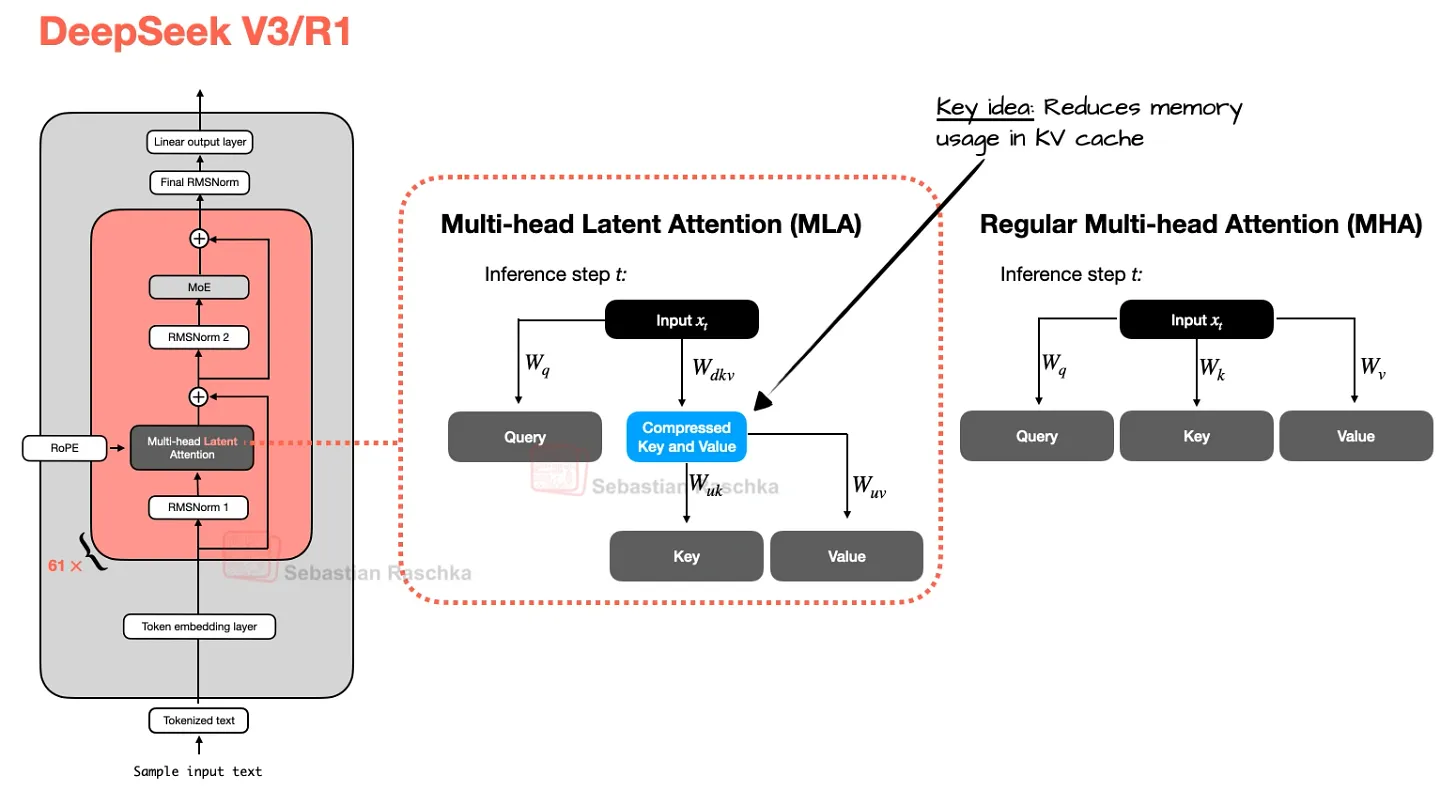
MLA 最初在 DeepSeek-V2 论文中提出,在 DeepSeek-V3 和 R1 之后成为 DeepSeek 时代的标志性设计。它比 GQA 实现更复杂、服务更困难,但随着模型规模和 context length 增大、cache 访问流量开始主导性能时,在相同内存压缩率下能保持更好的建模性能,因此越来越具有吸引力。
需要补充一点:原文在图 13 的图注中专门提醒,这张示意图为了简洁没有画出 query 侧的对应压缩/变换,实际 MLA 的改动并不只发生在缓存下来的 K/V 表示上。
典型使用模型:DeepSeek V3、Kimi K2、GLM-5、Ling 2.5、Mistral Large 3、Sarvam 105B
3.1 压缩而非共享
MLA 不像 MHA 和 GQA 那样缓存完整分辨率的 key 和 value tensor,而是存储一个 latent 表示,在需要时再重建可用状态。本质上,这是一种嵌入在 attention 内部的 cache 压缩策略。
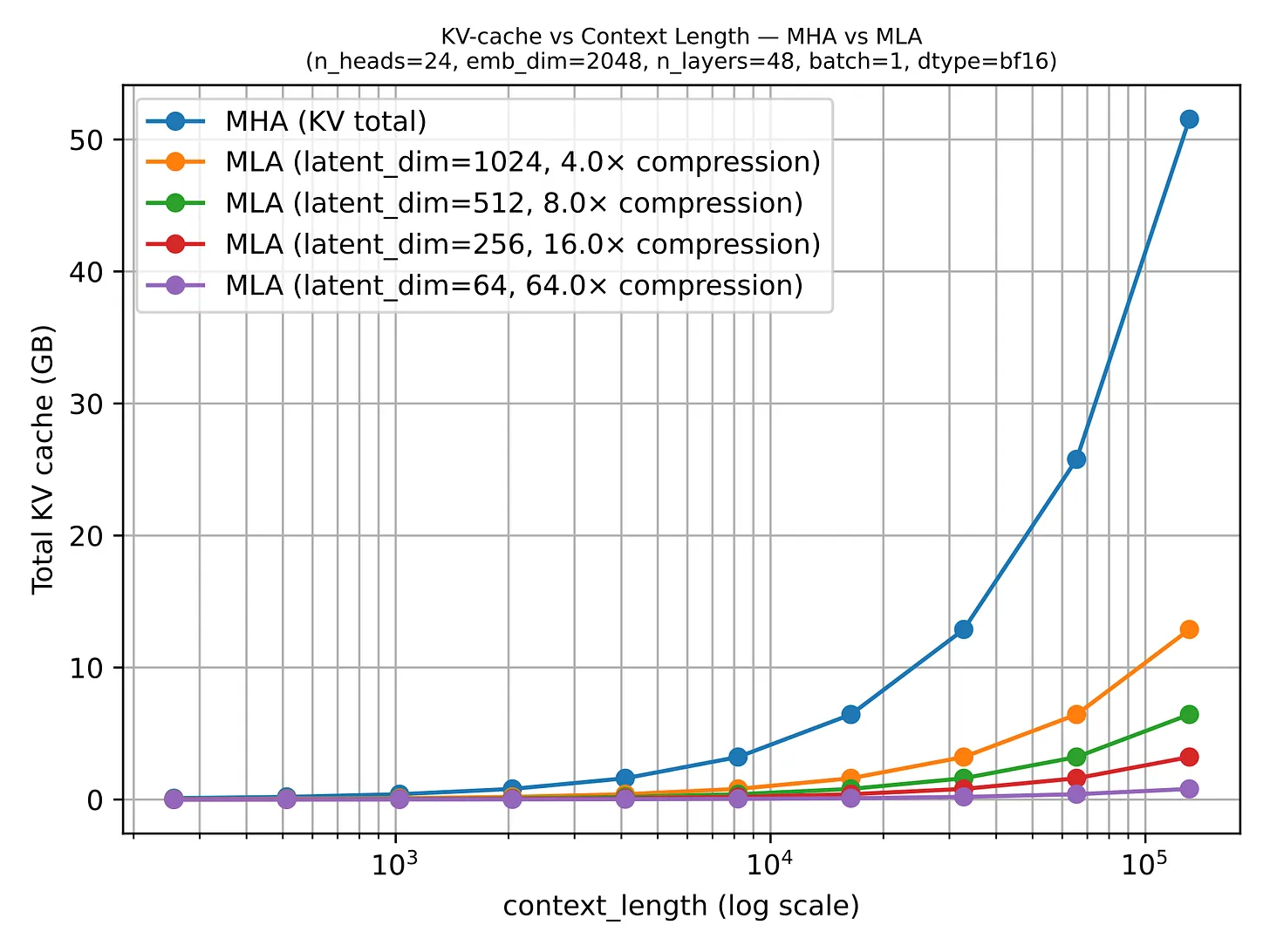
3.2 MLA 的 ablation 研究
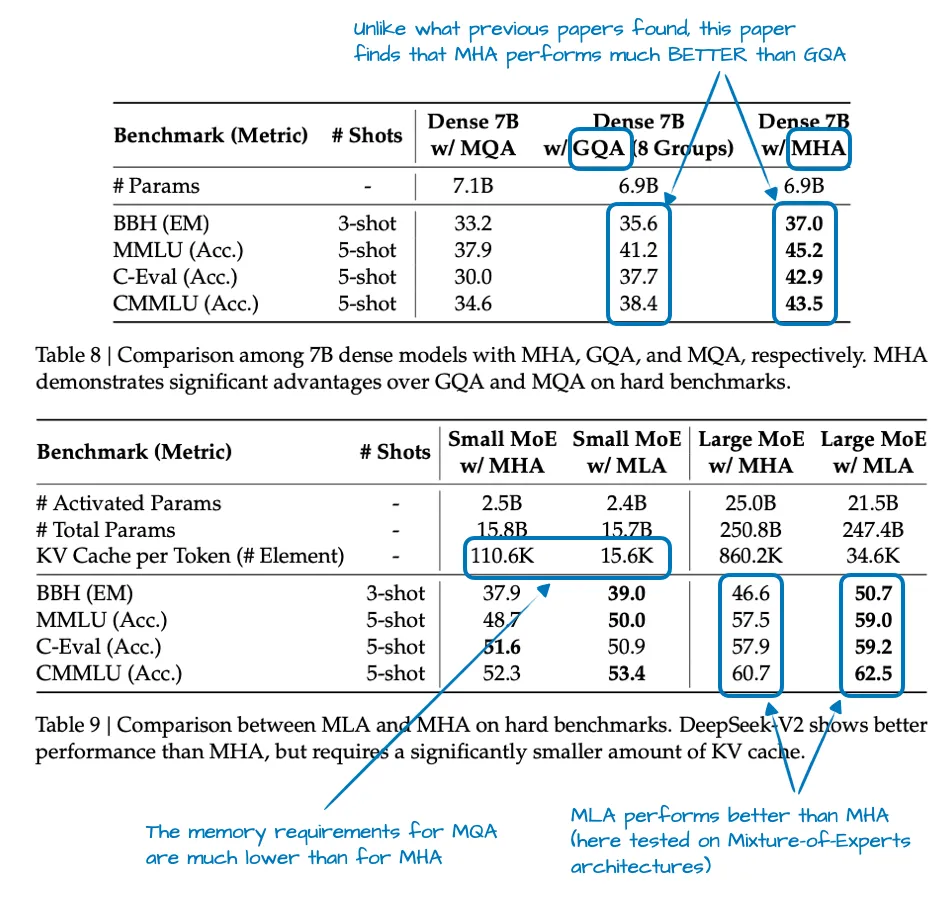
DeepSeek-V2 论文提供了一些 ablation 实验:GQA 在建模性能上低于 MHA,而 MLA 保持得更好,仔细调优后甚至能超过 MHA。这比”它也节省内存”的说法更有说服力。
换句话说,MLA 之所以成为 DeepSeek 的首选 attention 机制,不仅是因为高效,还因为它在大规模场景下是一次保质的效率提升。(不过据同行反映,MLA 在特定规模才效果最好;对于 <100B 的小模型,GQA 似乎更容易调整和使用。)
3.3 MLA 的扩散
DeepSeek V3/R1、V3.1 等将设计正常化后,MLA 开始出现在第二波架构中:Kimi K2 延续了 DeepSeek 方案并继续扩大规模;GLM-5 将 MLA 与 DeepSeek Sparse Attention 结合;Ling 2.5 将 MLA 与 linear-attention hybrid 配对;Sarvam 同时发布了两个版本——30B 使用 GQA,105B 切换到 MLA。
Sarvam 这组对比特别有价值:同一个团队实现了两种方案,并有意识地为不同规模选择了不同方案,这让 MLA 不再只是理论上的替代方案,而是模型家族随规模扩大后的具体升级路径。
4. Sliding Window Attention(SWA)
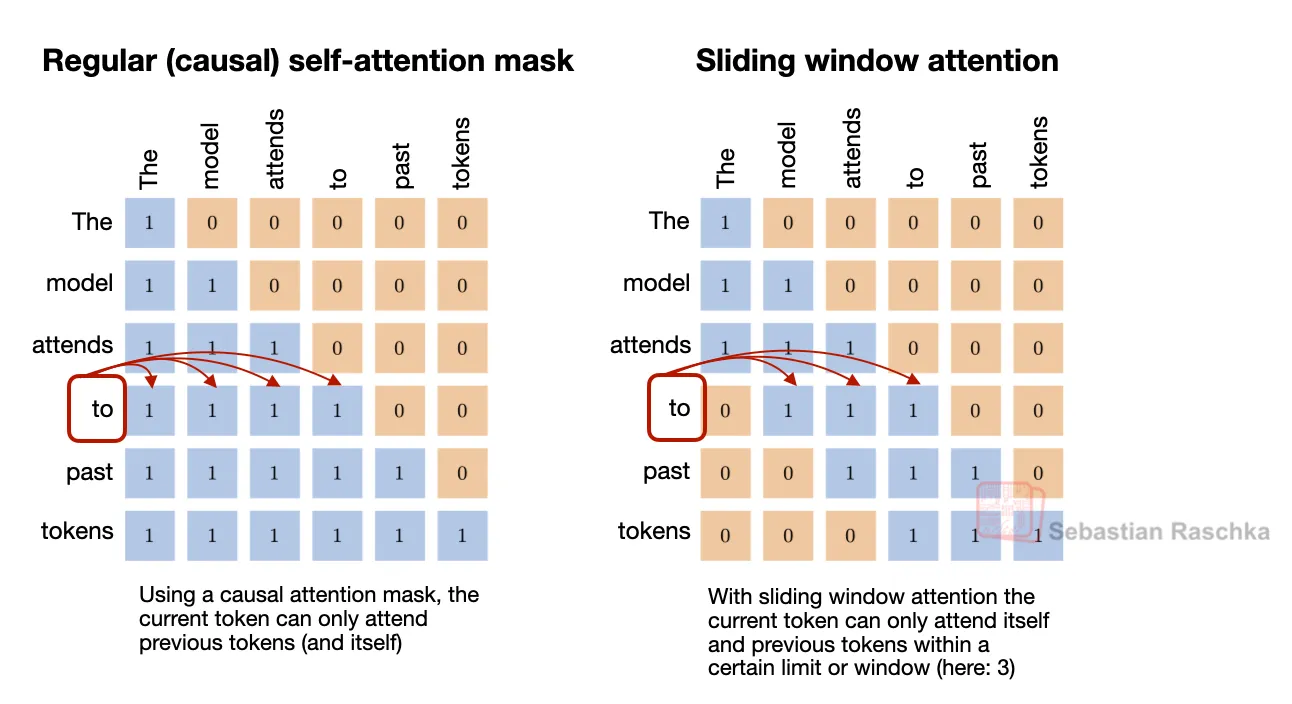
Sliding Window Attention 通过限制每个位置能 attend 到的历史 token 数量,降低长 context 推理的内存和计算成本。每个 token 只 attend 固定窗口内最近的若干 token,而非整个前缀。因为 attention 被限制在局部 token 邻域内,这种机制也常被称为 local attention。
部分架构将这些 local 层与偶尔的 global attention 层结合,使信息仍能在整个序列中传播。
典型使用模型:Gemma 3 27B、OLMo 3 32B、Xiaomi MiMo-V2-Flash、Arcee Trinity、Step 3.5 Flash、Tiny Aya
4.1 以 Gemma 3 为参考
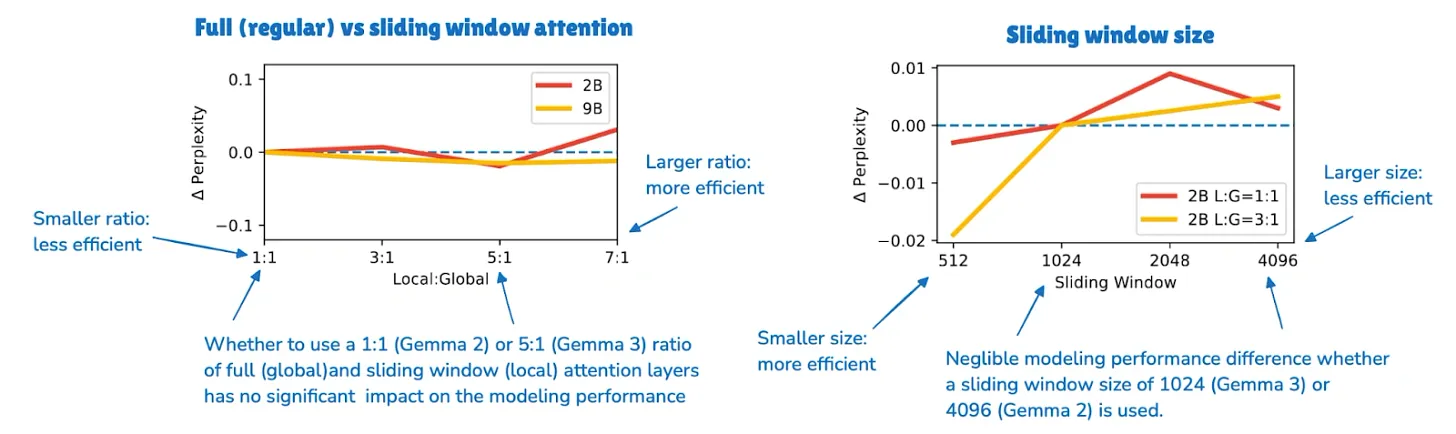
Gemma 3 是最清晰的近期 SWA 案例之一,因为它方便与 Gemma 2 对比。Gemma 2 已经使用了 local-to-global 层 1:1 比例、4096 token 窗口的 hybrid attention 设置;Gemma 3 将其推进到 5:1 比例,并将窗口缩小到 1024。
关键发现不在于 local attention 更便宜(这早已人尽皆知),更有趣的收获来自 Gemma 3 ablation 研究:更激进地使用 SWA 似乎只带来轻微的建模性能下降。
4.2 比例与窗口大小
在实践中,说一个模型”使用 SWA”并不意味着它完全依赖 SWA。真正重要的是 local-to-global 层的模式和 attention 窗口大小:
- Gemma 3 和 Xiaomi 使用 5:1 的 local-to-global 模式
- OLMo 3 和 Arcee Trinity 使用 3:1 模式
- Xiaomi 还使用了 128 的窗口大小,比 Gemma 的 1024 激进得多
SWA 本质上是一个可以调整激进程度的旋钮。
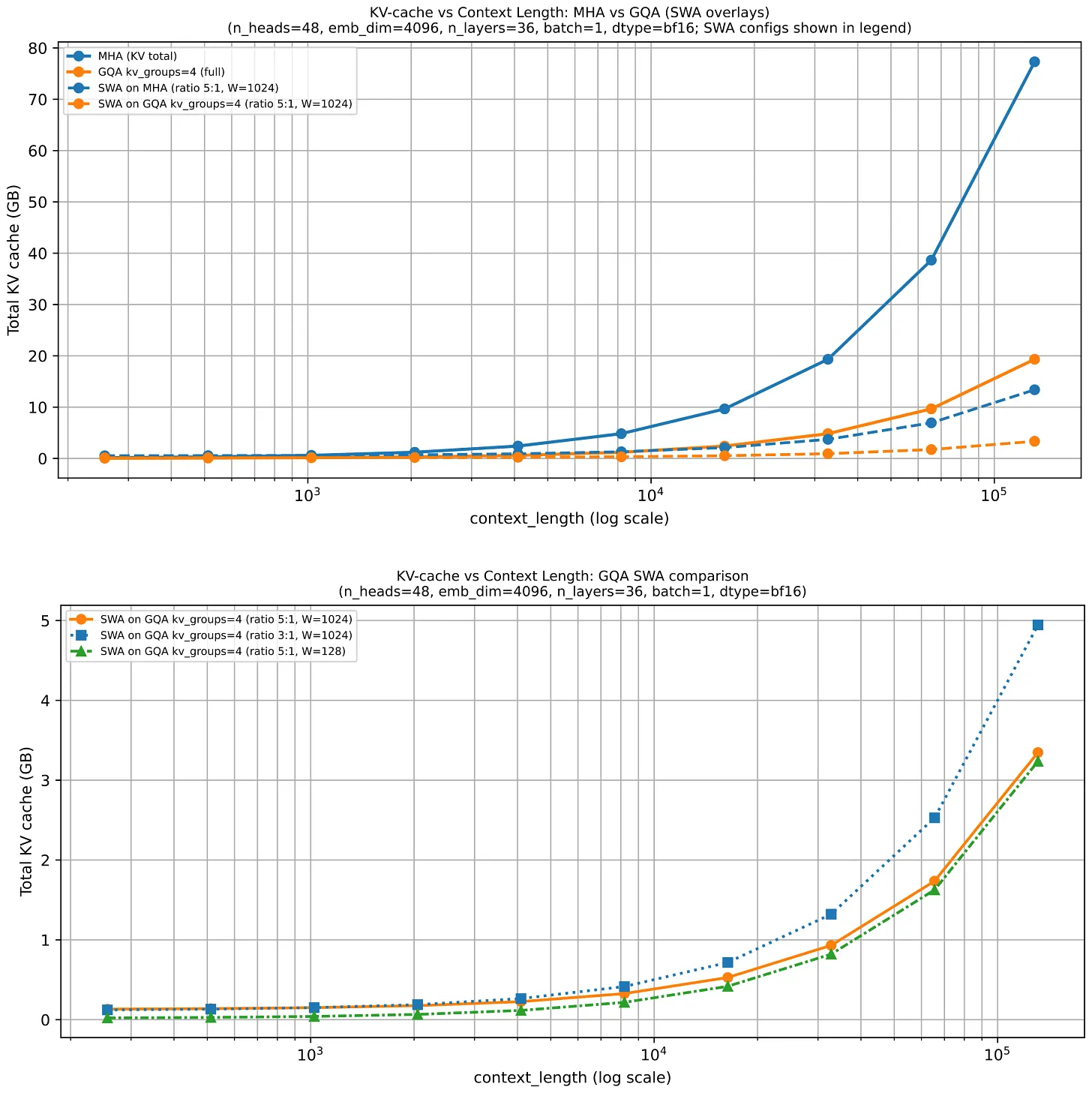
4.3 SWA 与 GQA 的结合
SWA 常与 GQA 一起出现,因为两者解决的是同一推理问题的不同方面:SWA 减少 local 层需要考虑的 context 量;GQA 减少每个 token 贡献给 cache 的 key-value 状态量。
这就是为什么很多近期 dense 模型同时使用两者,而不是将它们视为替代关系。Gemma 3 再次是一个很好的参考点,它在同一架构中同时结合了 SWA 和 GQA。
5. DeepSeek Sparse Attention(DSA)
DeepSeek Sparse Attention 是出现在 DeepSeek V3.2 系列中的架构改动之一,后来又在 GLM-5 中出现。
DeepSeek V3.2 将其与 MLA 结合使用,GLM-5 也采用了同样的组合,目的相同:在 context length 增大时降低推理成本。
典型使用模型:DeepSeek V3.2、GLM-5
5.1 与 SWA 的区别
在 SWA 中,当前 token 不 attend 完整前缀,而只 attend 固定的局部窗口。DeepSeek Sparse Attention 的大思路相同——每个 token 也只 attend 前序 token 的一个子集。
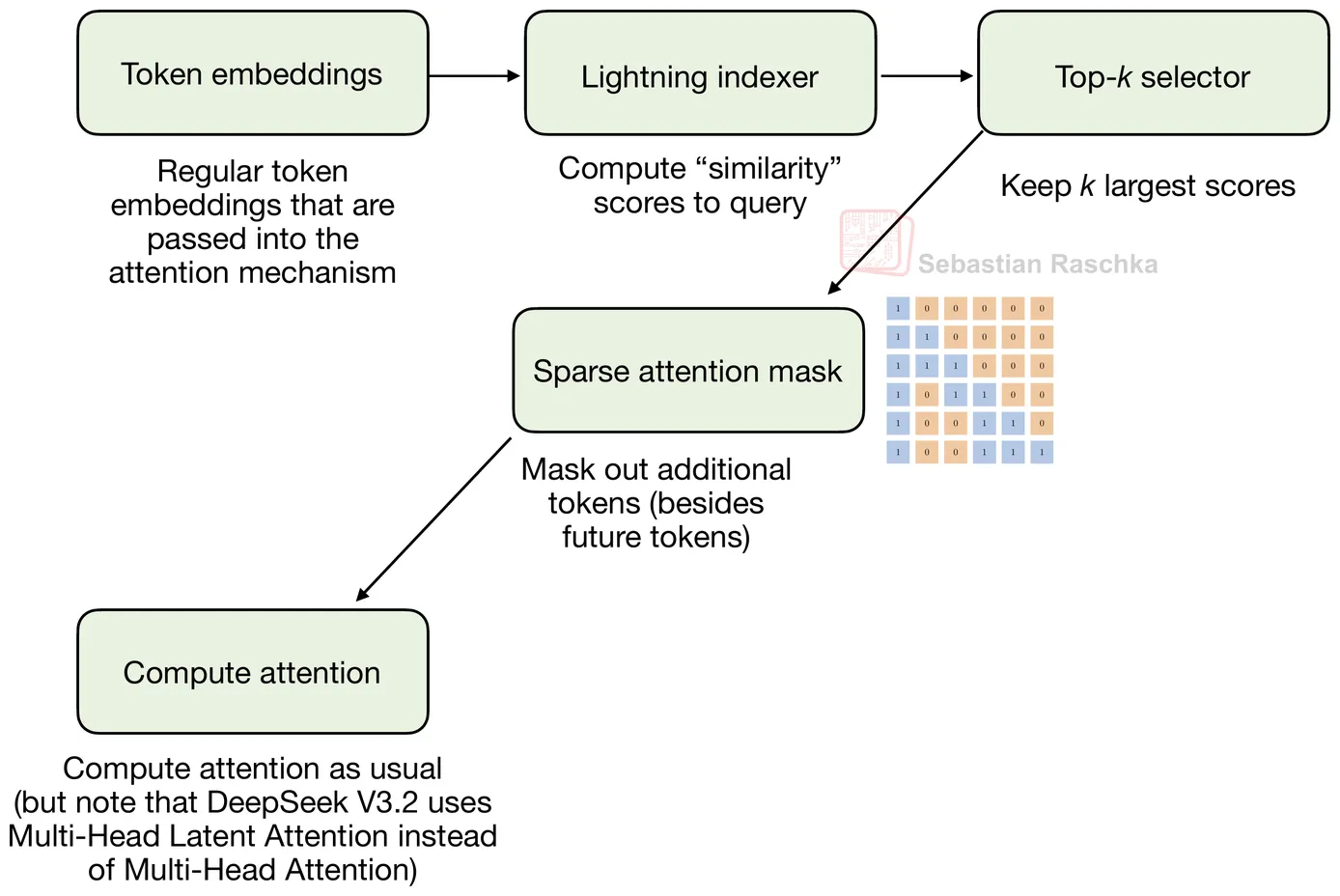
但不同之处在于:被选中的 token 子集不是由固定宽度的局部窗口决定的,而是由模型学习的 sparse 模式决定。具体来说,它使用一个 indexer-plus-selector 设计:lightning indexer 计算相关性得分,token selector 保留得分最高的一小部分历史位置。
选择方式是与 SWA 的主要区别。SWA 硬编码了局部性;DeepSeek Sparse Attention 仍然把 attention 限制在一个子集上,但让模型自己决定哪些历史 token 值得重新关注。
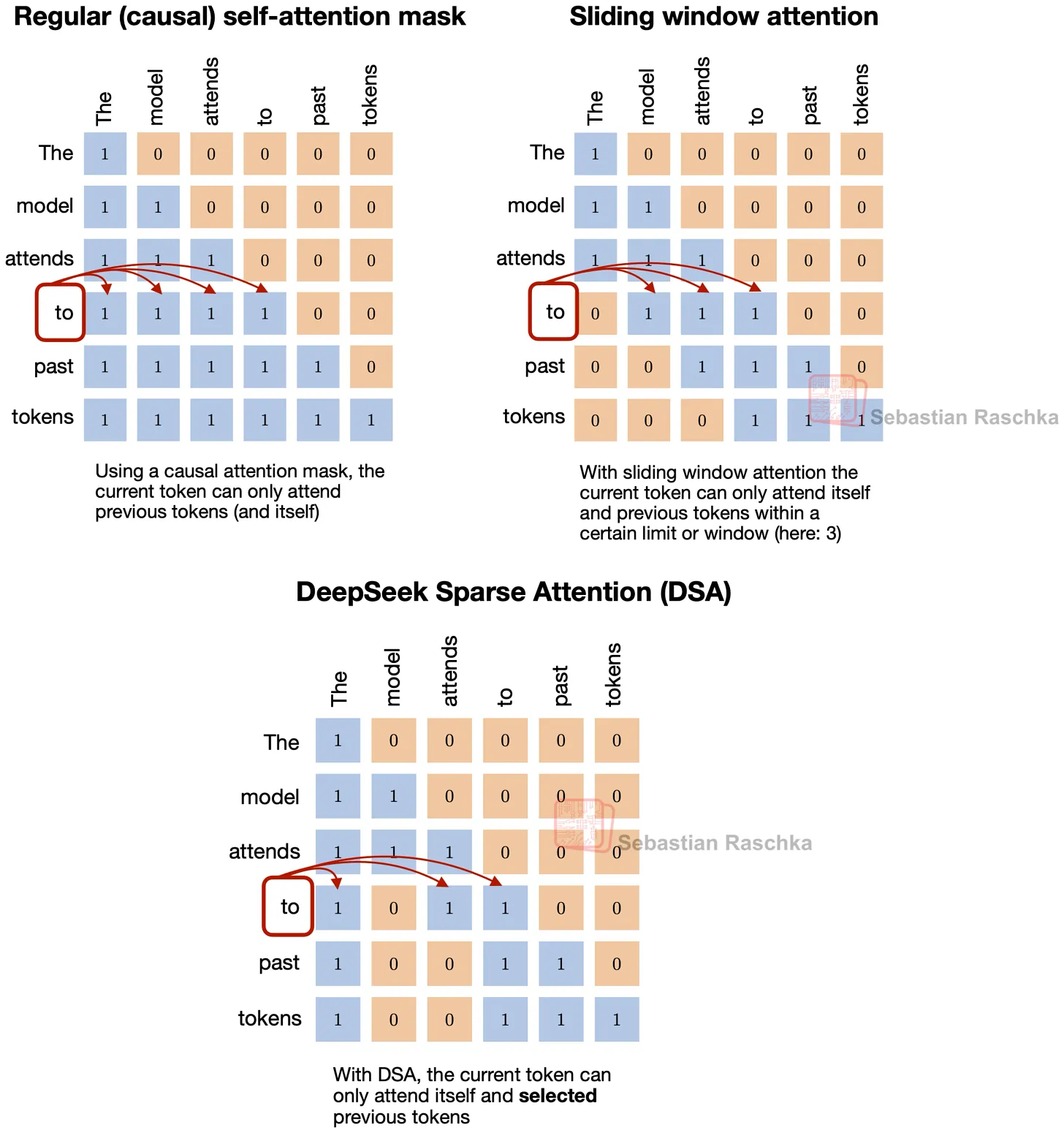
5.2 DeepSeek Sparse Attention 与 MLA 的配合
DeepSeek V3.2 同时使用 MLA 和 DeepSeek Sparse Attention:MLA 通过压缩存储内容来降低 KV cache 成本;DeepSeek Sparse Attention 减少模型需要重新访问的历史 context 量。换句话说,前者优化 cache 的表示形式,后者优化其上的 attention 模式。
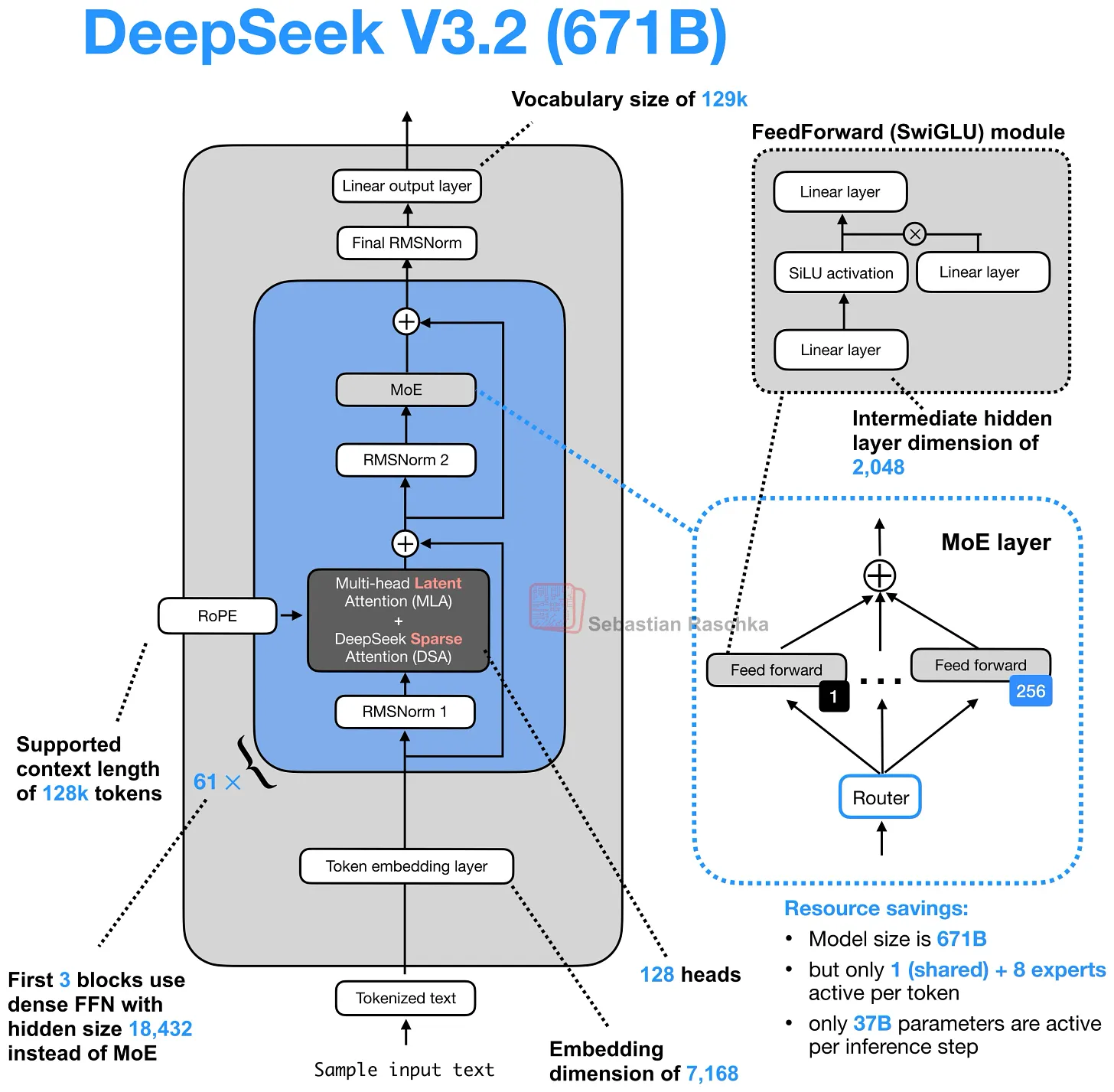
Sparse 模式不是随机的:第一阶段是 lightning indexer,对每个新 query token 为历史 token 打分,使用 MLA 的压缩 token 表示计算相似度得分,对历史位置排名;第二阶段是 token selector,只保留得分最高的小子集(如 top-k),并将其转化为 sparse attention mask。
DeepSeek Sparse Attention 相对较新、实现较为复杂,因此目前的普及程度还不及 GQA。
6. Gated Attention
Gated Attention 最好理解为一种改良版的 full-attention block,而非独立的 attention 新家族。
它通常出现在 hybrid 架构中:这些架构仍保留少量 full-attention 层用于精确内容检索,但在熟悉的 scaled dot-product attention block 之上添加了几处以稳定性为导向的改动。
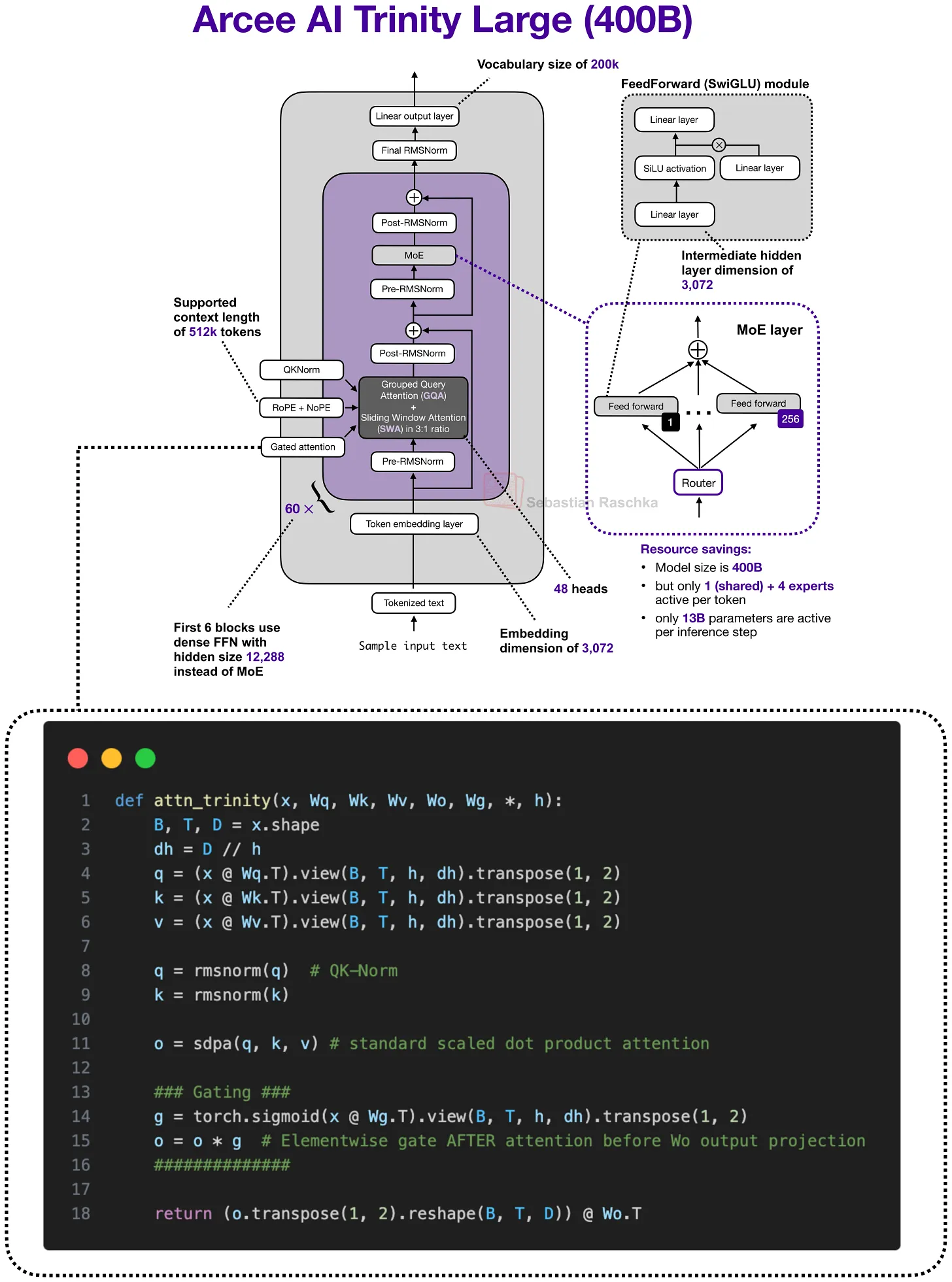
6.1 Gated Attention 出现的场景
Qwen3-Next 和 Qwen3.5 架构表明,近期的 hybrid 模型并不是在所有地方都替换掉 attention。它们将大多数 attention 层替换为更便宜的替代品,但在 stack 中保留了少数 full-attention 层。
这些保留下来的 full-attention 层就是 gated attention 通常出现的地方。Qwen3-Next 和 Qwen3.5 以 3:1 的模式将 gated attention 与 Gated DeltaNet 结合使用。
当然,除了 hybrid 架构,Trinity 也在更传统的 attention stack 中使用了类似的 gating 思路。
6.2 Gated Attention 与标准 Attention 的对比
Qwen 风格 hybrid 或 Trinity 中的 gated attention block 本质上是标准 scaled-dot-product attention,加上若干改动。在原始 Gated Attention 论文中,这些改动被描述为让保留的 full-attention 层在 hybrid stack 中表现更可预期的方式:
- Output gate:在 attention 结果加回 residual 之前,用一个门控对其进行缩放
- 零中心化 QK-Norm 变体:用于 q 和 k,替代标准 RMSNorm
- Partial RoPE
这些不是 MLA 或 linear attention 那个量级的改动,只是应用于熟悉 attention block 的稳定性和控制性改进。
从分类上看,Gated Attention 更像是”保留下来的 full-attention 层应该如何做得更稳”这个问题的答案,而不是一个单独追求更低 attention 复杂度的新主路线。
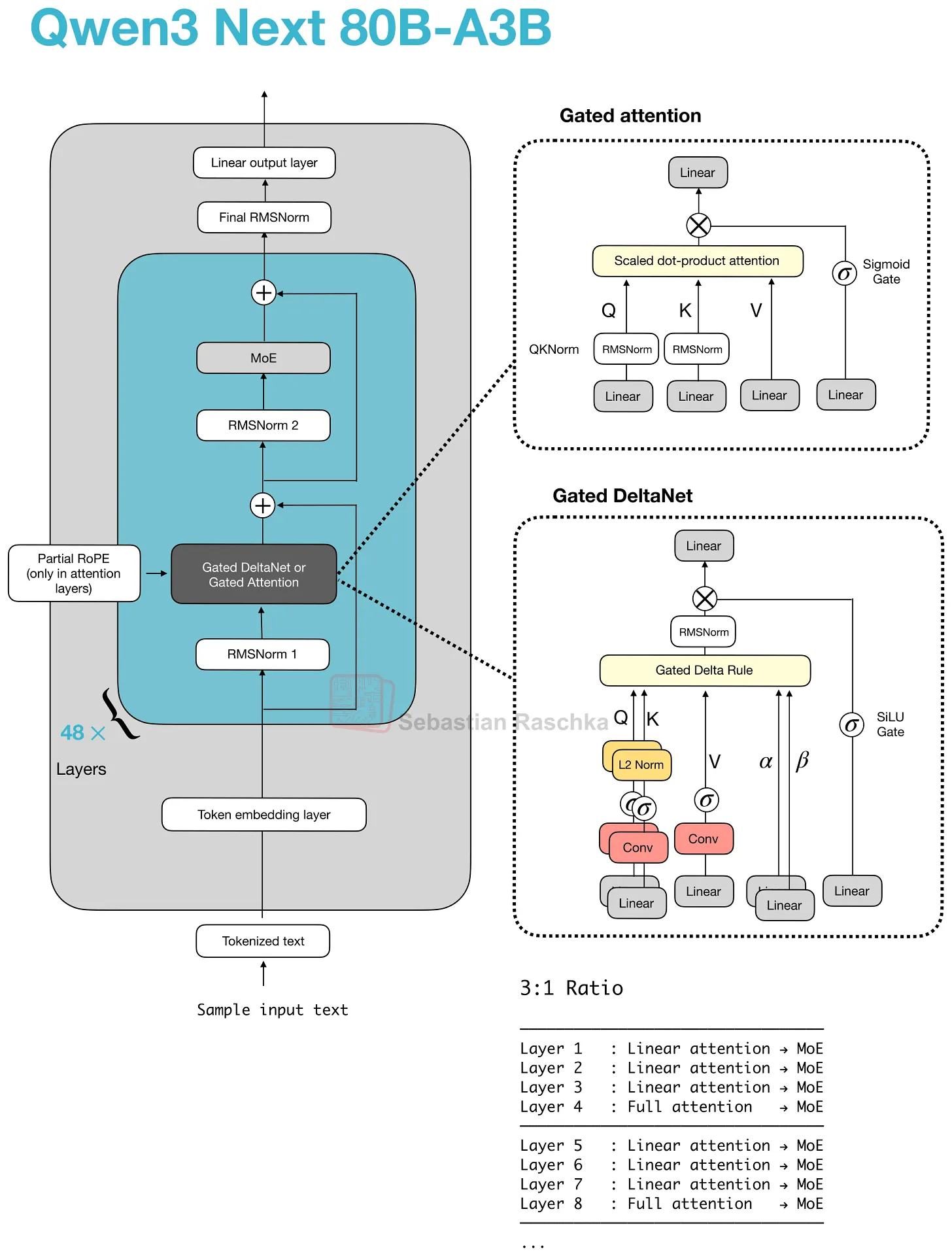
7. Hybrid Attention
Hybrid Attention 是一种更宏观的设计模式,而非某一具体机制。总体思路是保持类 Transformer 的 stack,但将大多数昂贵的 full-attention 层替换为更便宜的 linear 或 state-space 序列模块。
动机在于长 context 效率。Full attention 随序列长度呈二次方增长,一旦模型进入 128k、256k 甚至 1M token 的 context,attention 的内存和计算成本就变得昂贵到足以让人考虑:在大多数层使用更便宜的序列模块,只保留少数较重的检索层。(当然这会带来一定的建模性能 trade-off。)
7.1 Qwen3-Next 中的 Gated DeltaNet
据我所知,Qwen3-Next(2025 年)是第一个接近旗舰级的带 hybrid attention 的 LLM,它没有完全移除 attention,而是将三个 Gated DeltaNet block 与一个 Gated Attention block 混合。
轻量级 Gated DeltaNet block 承担了大部分长 context 工作,使内存增长比 full attention 平坦得多。保留的较重 gated-attention 层是因为 DeltaNet 在基于内容的检索上精确性不足。
在 Gated DeltaNet block 内部,模型计算 query、key、value 向量以及两个可学习的 gate(α、β)。它不构建通常的 token-to-token attention matrix,而是使用 delta-rule update 写入一个小型 fast-weight 内存。粗略来说,内存存储过去信息的压缩滚动摘要,gate 控制添加多少新信息、保留多少先前状态。
这使得 Gated DeltaNet 成为 linear-attention 或 recurrent 风格的机制,而非 MHA 的另一个变体。与 Mamba-2 的联系在于:两者都属于 linear-time gated sequence model 家族,但 Gated DeltaNet 使用 DeltaNet 风格的 fast-weight 内存更新,而非 Mamba 的 state-space 更新。
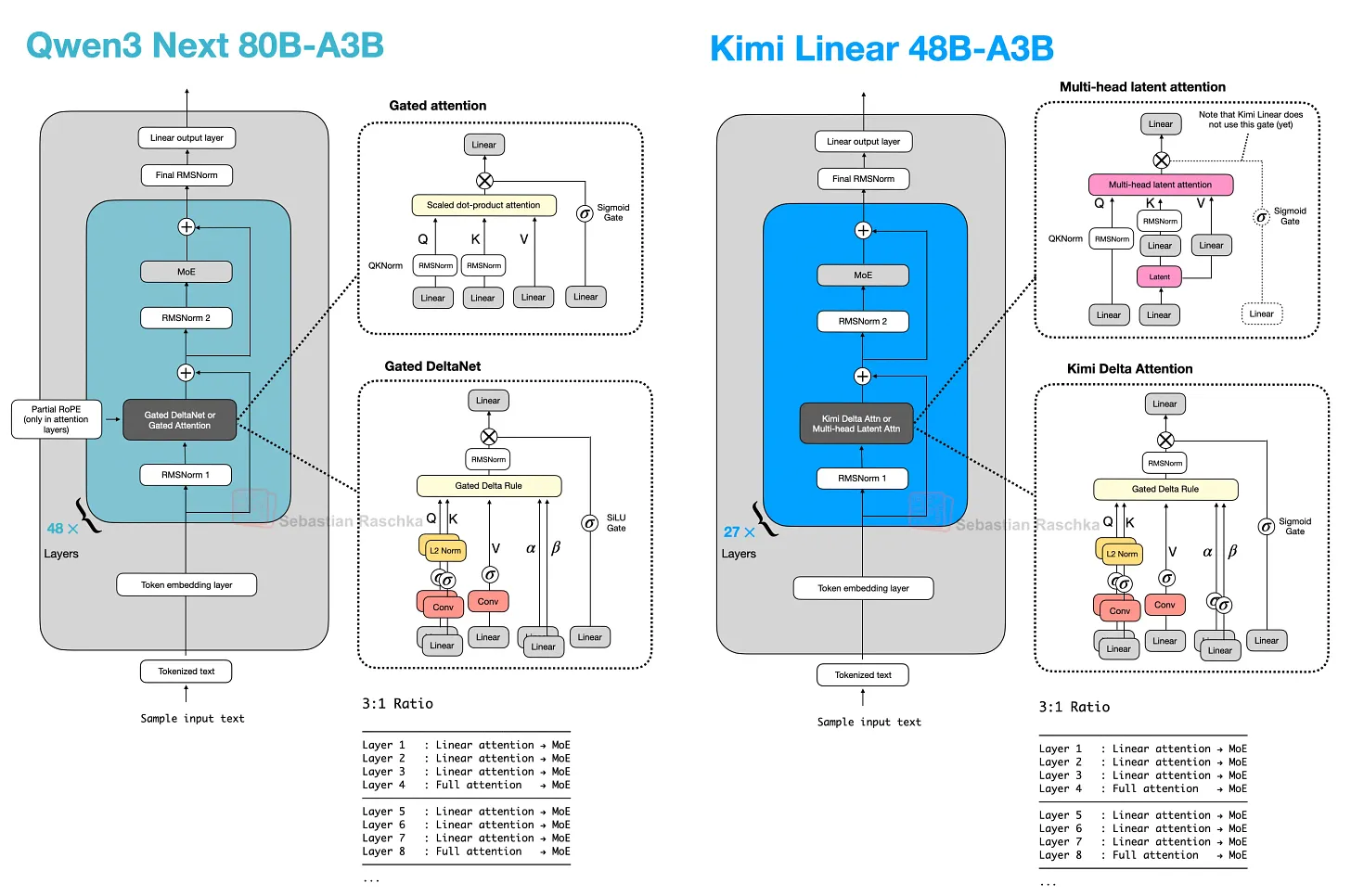
Qwen3.5 则把原本 Qwen3-Next 的 hybrid 路线提升进了 Qwen 主旗舰系列。这基本表明 hybrid 策略已经被验证为可行,未来可能会看到更多采用此架构的模型。
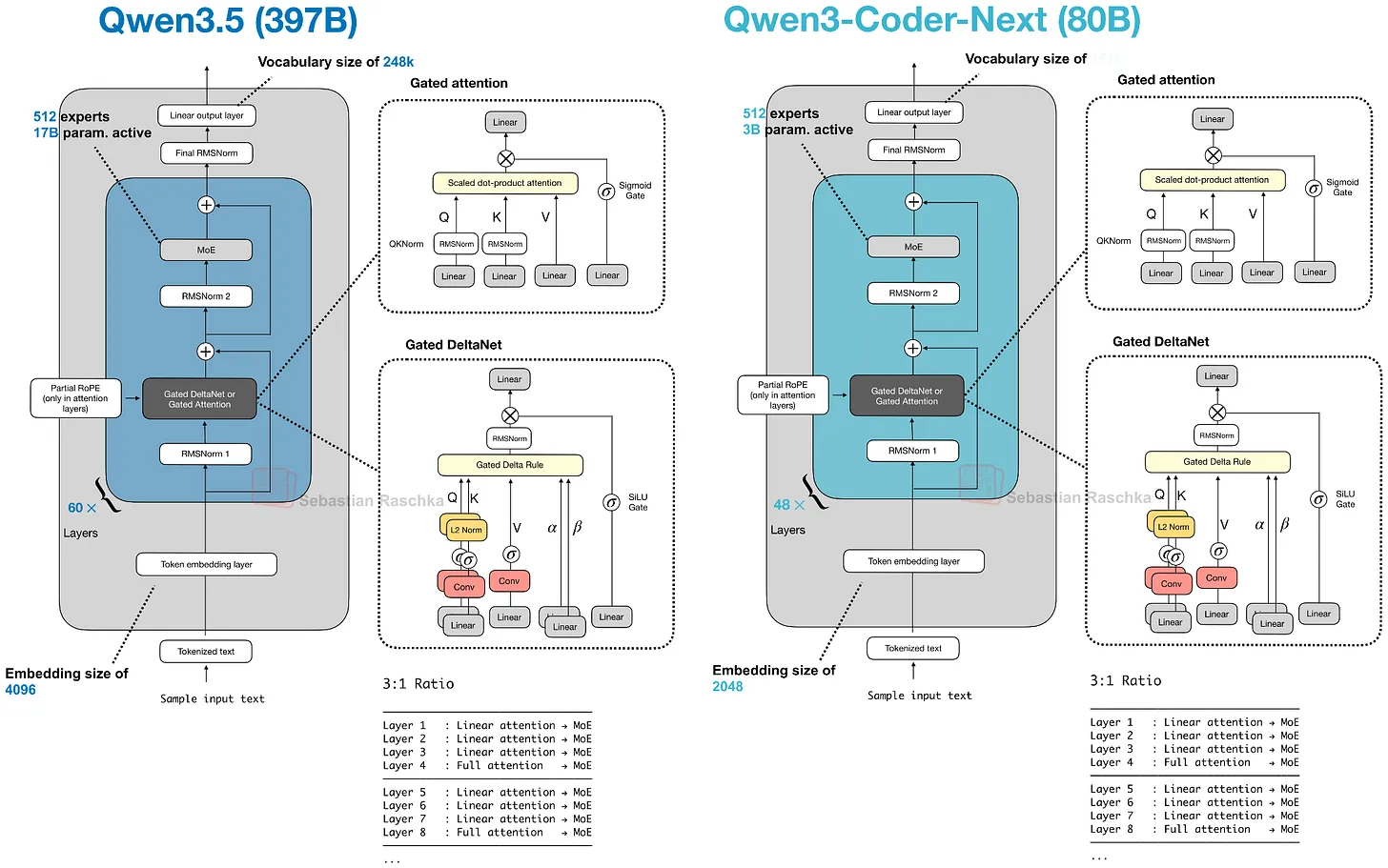
7.2 Kimi Linear 与改良版 Delta Attention
Kimi Linear 保留了相同的宏观 Transformer 骨架和 3:1 模式,但对两半的组成都做了调整。
轻量侧:Kimi Delta Attention 是 Gated DeltaNet 的改进版。Qwen3-Next 每个 head 使用标量 gate 控制内存衰减;Kimi 使用 channel-wise gating,对内存更新提供更细粒度的控制。较重侧:Kimi 将 Qwen3-Next 的 gated-attention 层替换为 gated MLA 层。
整体模式与 Qwen3-Next 和 Qwen3.5 相同,但两个组件都(略微)改变:大多数层仍由更便宜的 linear 风格机制处理,周期性的较重层仍然保留用于更强的检索。
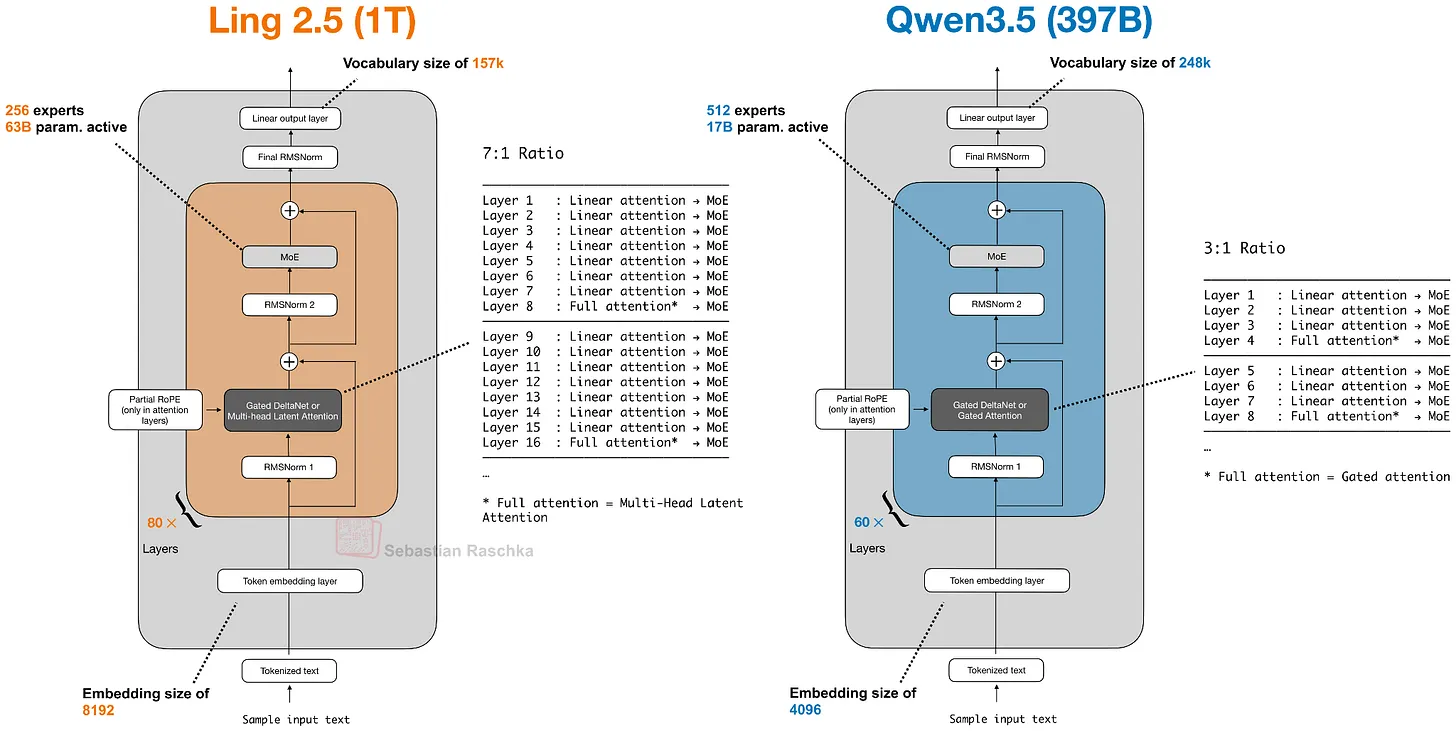
7.3 Ling 2.5 与 Lightning Attention
Ling 2.5 展示了轻量侧的另一种替换。它使用一种稍微简单的 recurrent linear attention 变体——Lightning Attention,而不是 Gated DeltaNet。较重侧保留了来自 DeepSeek 的 MLA。
大多数序列混合在更便宜的 linear-attention block 中进行,少量较重层保留用于更强的检索。区别在于,具体的轻量机制变成了 Lightning Attention,而非 DeltaNet 或 Kimi Delta Attention。
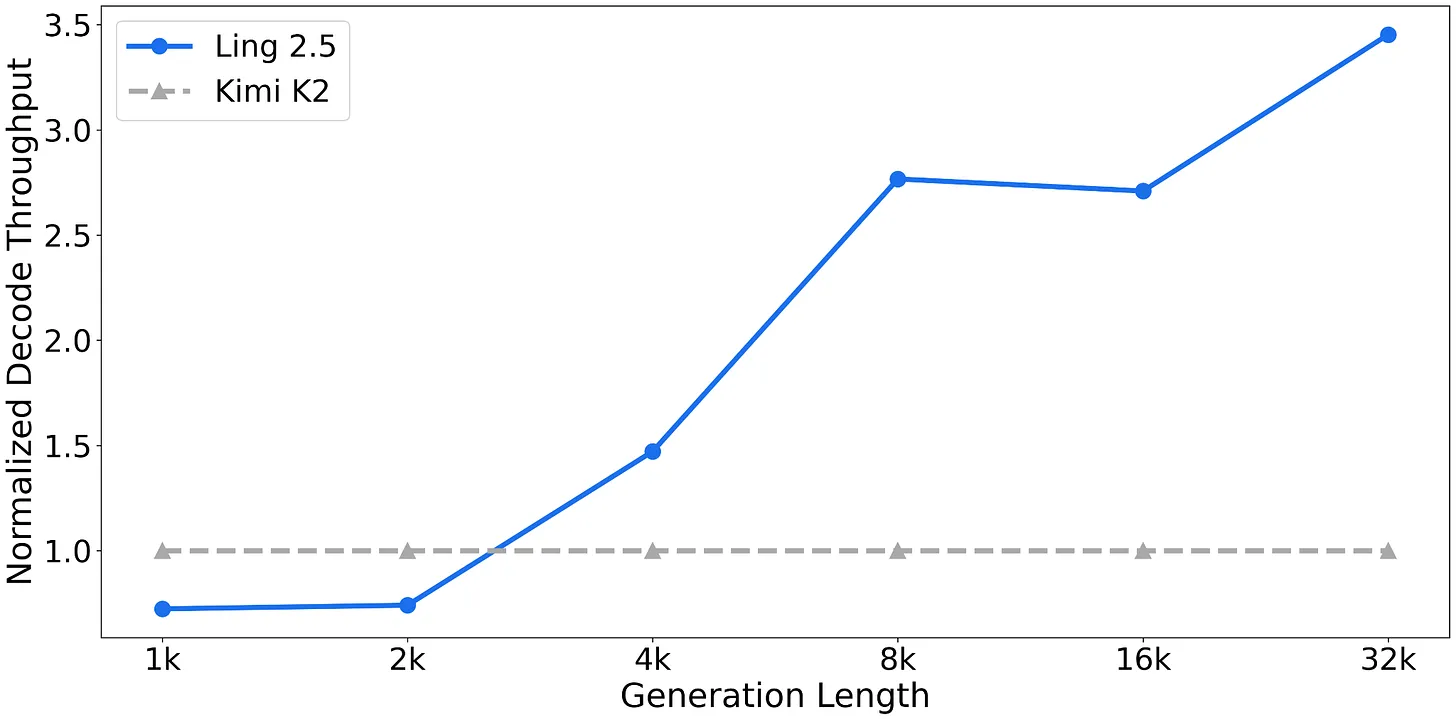
Ling 2.5 更侧重于长 context 效率而非绝对 benchmark 领先。据 Ling 团队报告,在 32k token 场景下其吞吐量显著高于 Kimi K2,这正是这些 hybrid 方案所追求的实际回报。
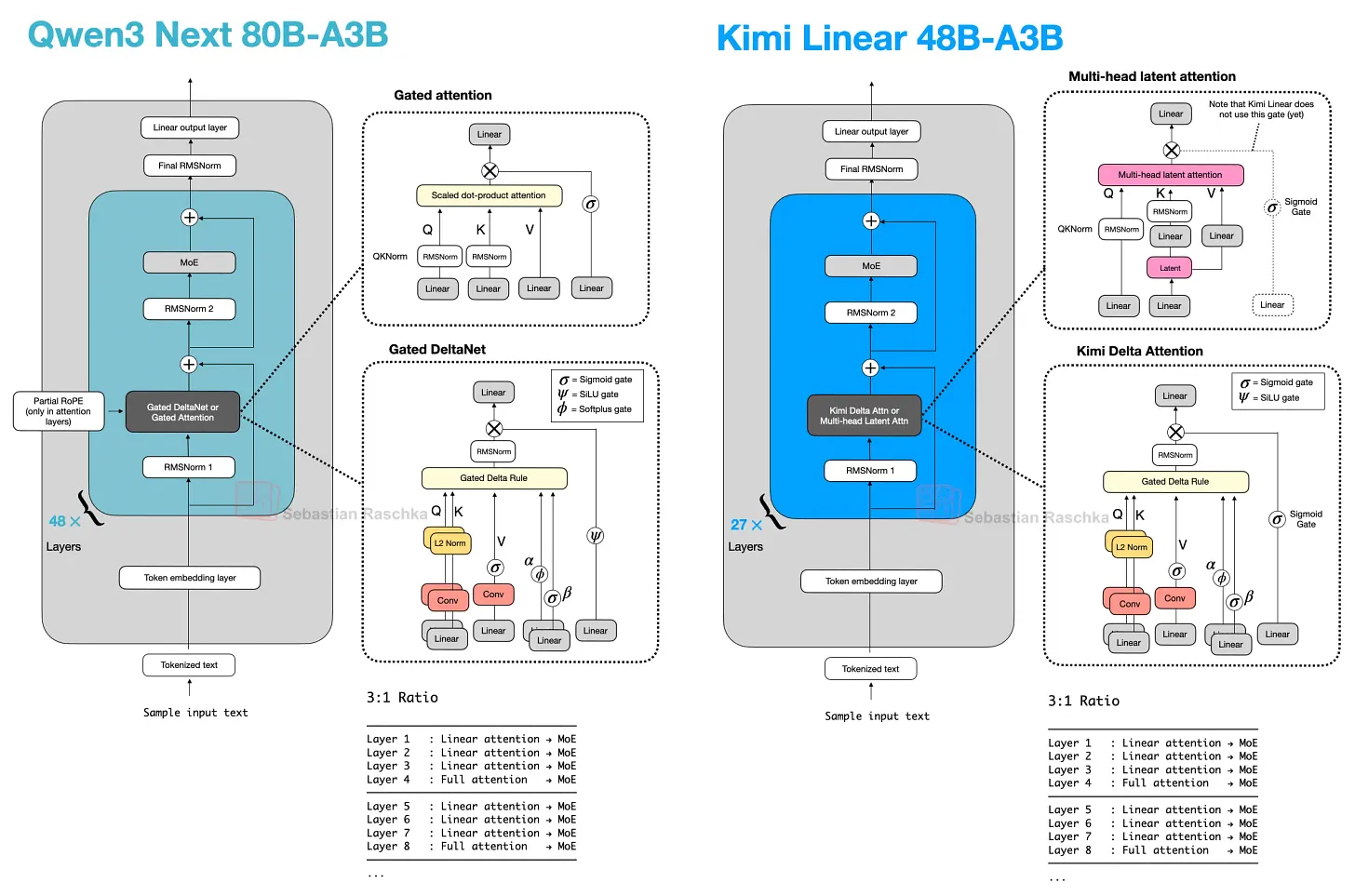
7.4 Nemotron 与 Mamba-2
Nemotron 将模式推得离 Transformer baseline 更远。Nemotron 3 Nano 是一个 Mamba-Transformer hybrid,将 Mamba-2 序列建模 block 与 sparse MoE 层交织,只在少数层使用 self-attention。
这是上述基本 trade-off 的更极端版本:轻量序列模块是 Mamba-2 state-space block,而非 DeltaNet 风格的 fast-weight update,但基本 trade-off 类似。
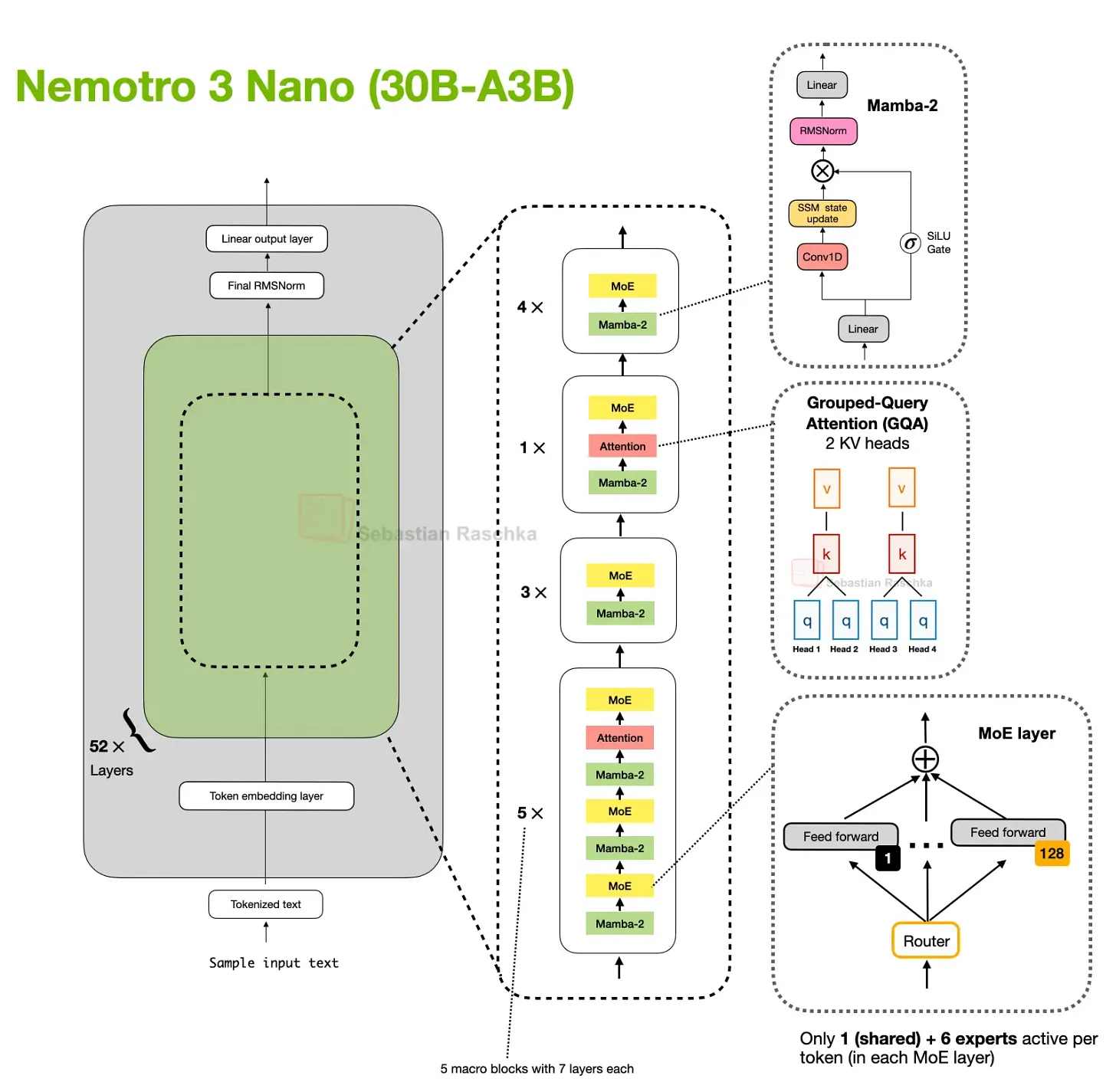
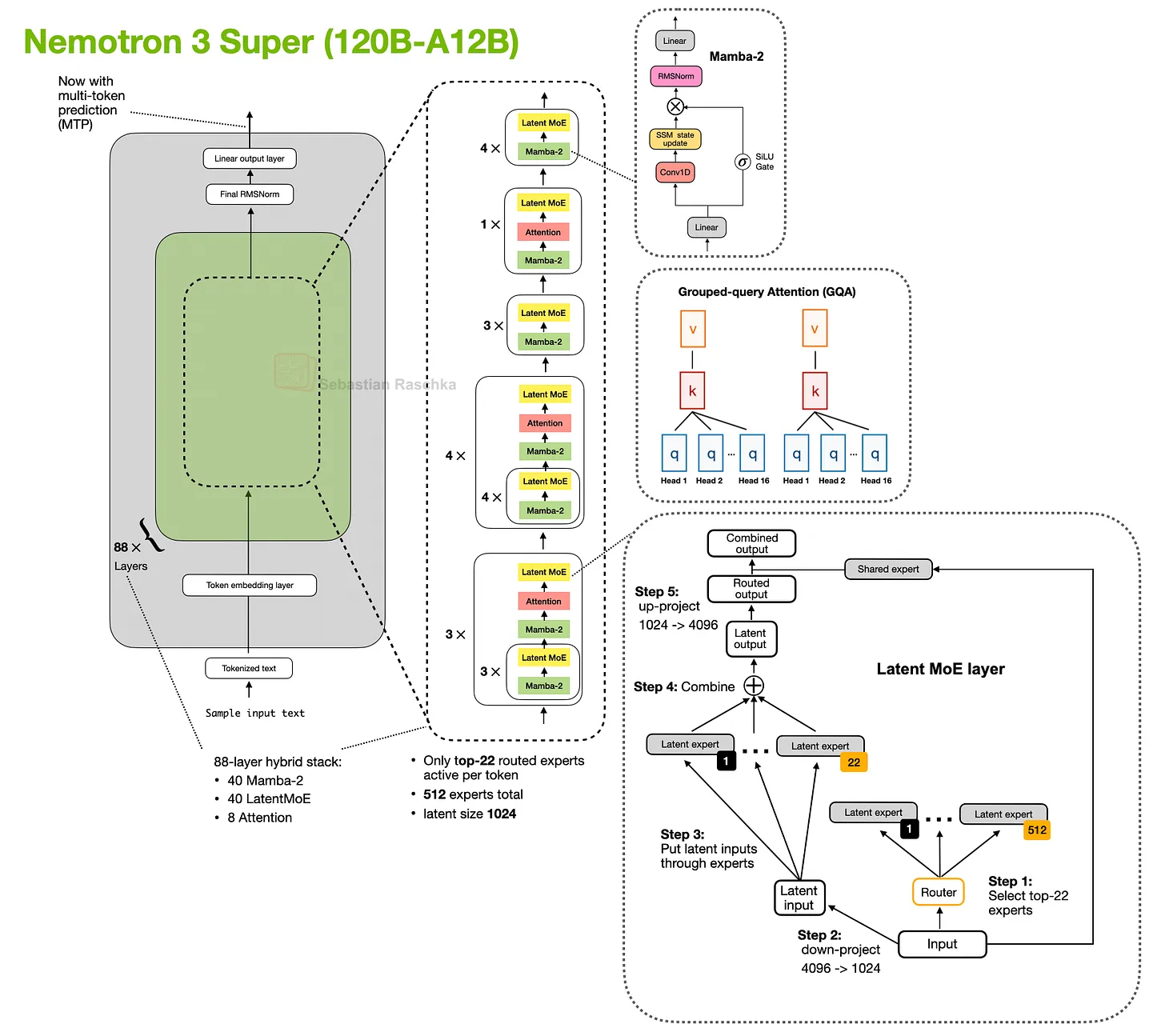
更大的 Nemotron 3 Super 保留了 Mamba-2 hybrid attention 方法,并增加了 latent MoE 和 shared-weight multi-token prediction(MTP,用于 speculative decoding)等其他效率改进。
译者补充:如何给这些 Attention 变体分类
如果第一次接触这些术语,最容易混淆的地方在于:它们并不都处在同一抽象层级。一个更清晰的办法是按”它主要改了 attention 的哪一部分”来分类:
- KV 表示与缓存成本:MHA、GQA、MLA 主要回答”每个 token 的 K/V 应该怎么表示和缓存”。其中 MHA 是基线,GQA 通过共享 K/V head 降低缓存开销,MLA 通过压缩 latent 表示降低缓存开销。
- 可见上下文的选择方式:SWA、DSA 主要回答”当前 token 到底看哪些历史 token”。SWA 用固定局部窗口硬编码稀疏模式,DSA 则让模型学习要保留哪些历史位置。
- Block 级稳定性或架构级替换:Gated Attention、Hybrid Attention 主要回答”在整个网络里 attention block 应该怎样被保留、改造或替换”。前者是对 full-attention block 的稳态改良,后者则是用 linear attention 或 state-space 模块替换大多数 full-attention 层的整体架构策略。
这也是为什么很多术语并不是互斥关系。例如,一个模型完全可以同时使用 GQA + SWA,因为前者优化的是 KV cache 表示,后者优化的是可见上下文范围;也可以出现 MLA + DSA,因为一个在压缩缓存表示,另一个在学习稀疏访问模式。
结语
当然,文献中还有很多(大多是小众的)attention 变体本文未能覆盖。本文的重点在于目前最先进开放权重模型中实际使用的那些。
特别期待:(1)全新的 Mamba-3 层被整合进上述 hybrid 架构(替代 Gated DeltaNet);(2)attention residuals 得到更广泛的应用。
关于”目前最优架构是什么”这个问题,很难回答,因为没有公开的、在相同训练数据上训练不同架构的实验。
就当前最优模型选择而言,hybrid 架构仍属新颖尝试,主要卖点是(长 context)效率,而非纯粹的建模性能。Sebastian 在原文里还明确提到,他认为这类架构很适合 agent context 一类长上下文场景;但在本地运行 LLM 时,使用 GQA 等经典设置往往仍能获得更好的 tok/sec 吞吐量,说明 inference stack 的优化还不够成熟。
无论如何,很期待 DeepSeek V4 会带来什么,DeepSeek 在过去两年一直是相当可靠的趋势引领者。
原文链接:A Visual Guide to Attention Variants in Modern LLMs
作者:Sebastian Raschka, PhD
发布日期:2026-03-22