近年来,主流大语言模型架构正经历从标准多头注意力(MHA)向多查询注意力(MQA)、分组查询注意力(GQA)及多头潜在注意力(MLA)的范式转移。这一演进的核心驱动力在于解决自回归解码阶段 KV Cache 带来的显存容量与带宽瓶颈(即“内存墙”问题),旨在通过降低访存开销来显著提升推理吞吐量与长文本处理能力。
当前 transformer 的组件中,尤其是 attention 部分从硬件适配和自身结构上有多方面的优化。如 Qwen3-Next、Llama 的 GQA,DeepSeek 的 MLA 等;也有像 minimax-M2 这样在权衡之后回归 full attention(仍采用 GQA,48 个 query head 配 8 个 KV head)、放弃 hybrid/linear attention 的选择。那这些优化到底是出于何种目的?想要回答这个问题,需要先从推理的两个阶段说起。
一、推理的两个阶段:Prefill 与 Decode
LLM 在 inference 阶段可以拆解为两个性质截然不同的步骤:
- Prefill 阶段:模型接收完整的输入 Prompt,处于一个
预填充状态。并行计算所有输入词元的中间表示($Q$、$K$、$V$),并生成第一个输出词元。该过程是矩阵-矩阵乘法(GEMM),计算高度密集,能充分利用 GPU 的并行计算单元,属于典型的 计算受限(Compute-bound) 场景。 - Decode 阶段:从第二个 token 开始,模型每次只生成一个新 token,并需要让当前 token 的 $\vec{q}$ 与历史序列的 $K$、$V$ 做注意力交互。如果不做任何缓存,每生成一个 token 都要为所有历史词元重新计算一遍 $K$、$V$,复杂度会随序列长度平方级膨胀,造成大量重复计算,理论复杂度攀升到$O(N^2)$。
正是 Decode 阶段“自回归 + 重复计算”的特性,催生了 KV Cache 这一“以空间换时间”的优化思路。
二、MHA 的计算流程
2.1 Prefill 阶段
模型接收到完整的输入序列,可以写作: $X=[\vec{x_1}, \vec{x_2}, … ,\vec{x_t},]$ 在 MHA 的 prefill 阶段:
- 输入序列经过线性层$W_q, W_k, W_v$投影成 $Q、K、V$,$Q,K,V \in \mathbb{R}^{t \times d}$, 并按 head 切分,维度变化为 $[b, h, L, d_h]$;
- 通过 $Q \times K^T$ 得到 $[b, h, L, L]$ 的注意力分数矩阵,再经 mask、softmax,与 $V$ 相乘聚合;
- 多头结果拼接还原回 $[b, L, d]$,依次经过
Add & Norm、FFN等模块; - 最终只取输出矩阵的最后一行 $[b, 1, d]$ 进入
LM Head用于预测下一个 token,同时把整段序列对应的 $K$、$V$ 写入 KV Cache,作为后续增量计算的基础。
在一个 multi-head attn 下,我们的 head 为 2,则会出现以下过程:
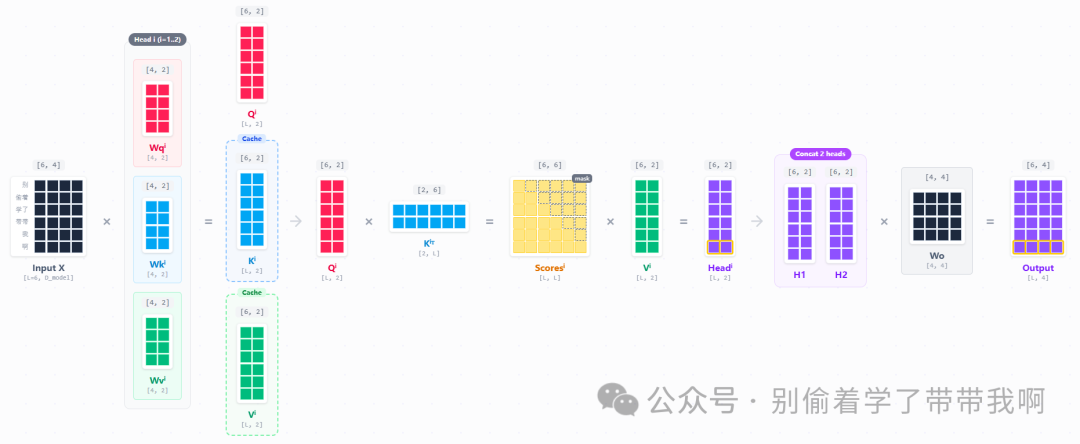
我们每个head,都要执行一次attention的score计算:
\[\mathrm{Scores}_1 = Q_1 K_1^T = \underbrace{ \begin{bmatrix} 1 & 0 \\ 0 & 1 \\ 1 & 1 \\ 0 & 0 \\ 1 & 0 \\ 0 & 1 \end{bmatrix} }_{Q_1(6 \times 2)} \times \underbrace{ \begin{bmatrix} 2 & 0 & 2 & 0 & 2 & 0 \\ 0 & 2 & 2 & 0 & 0 & 2 \end{bmatrix} }_{K_1^T(2 \times 6)} = \begin{bmatrix} 2 & 0 & 2 & 0 & 2 & 0 \\ 0 & 2 & 2 & 0 & 0 & 2 \\ 2 & 2 & 4 & 0 & 2 & 2 \\ 0 & 0 & 0 & 0 & 0 & 0 \\ 2 & 0 & 2 & 0 & 2 & 0 \\ 0 & 2 & 2 & 0 & 0 & 2 \end{bmatrix}\]在 Transformer 结构中,每一层的输出向量(Hidden State)中,只有最后一行(即最新 Token 的向量)会被传递到最终的LM Head或下一层对应的位置 ,用于生成下一个预测结果。
在 Prefill 阶段因为我们没有见过所有输入,所以需要并行计算整个 attn 矩阵取最后一行进入 LM Head 预测下一个 token。然而在 Decoding 阶段,当我们已经有一个 token 生成后,需要计算下一个 token,当生成第 $t$ 个 token时,我们需要$[x_1, … , x_{t-1}]$的 $K$ 和 $V$ 来计算注意力,但这些历史 token 的 $K$ 和 $V$ 在生成第 $t-1$ 个 token 的时候已经算过一遍了。
2.2 Decode 阶段:有无 KV Cache 的对比
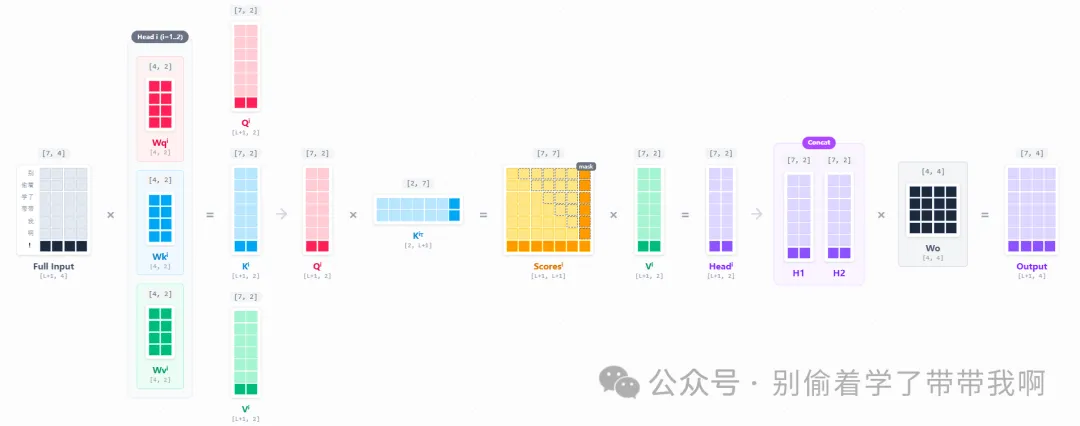
上图中所有浅色部分都是计算过一遍的,随着 context length 的增长,计算资源被大量浪费在重复计算上。
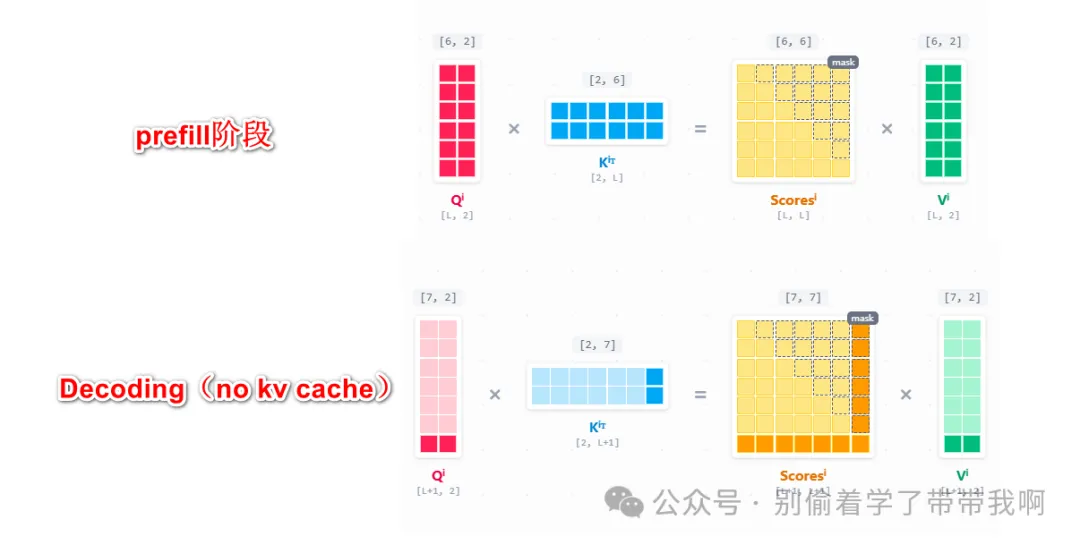
- 没有 KV Cache:每生成一个新 token,都需要把已经生成过的所有 token 重新跑一遍 attention,$K$、$V$ 被反复计算,浪费严重。生成 $N$ 个 token 的总复杂度量级直接攀升到 $O(N^2)$。
- 有 KV Cache:把历史 token 的 $K$、$V$ 缓存起来,每一步只为当前新 token 计算一行 $q$、$k$、$v$,再把新的 $k$、$v$ 拼接到缓存上。$Q$ 与缓存的完整 $K$、$V$ 做注意力计算,由 GEMM 退化为 GEMV,计算量大幅下降。
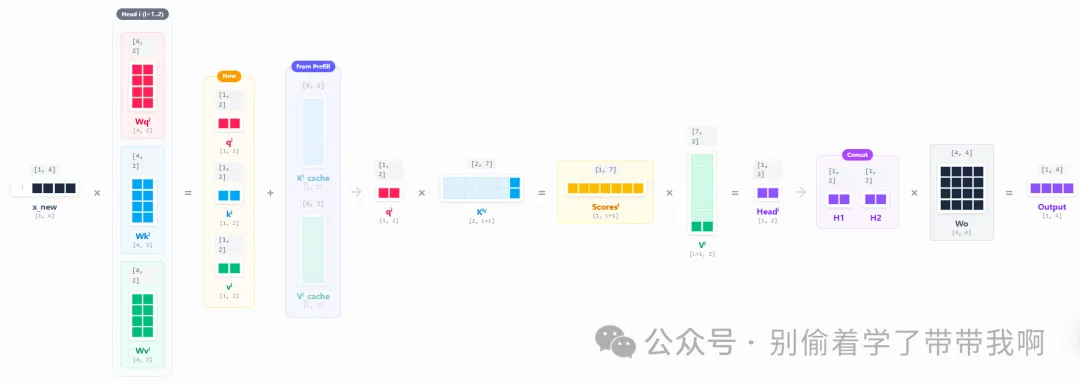
这样,计算第 $t$ 个 token 的输出就可以忽略 $[\vec{x_1}, … , \vec{x_{t-1}}]$ 所在的历史上下文,而 $\vec{x_t}$ 是唯一需要的新输入,这样避免了对历史 token 进行重复的 Embedding 和线性层计算。接着用权重矩阵 $W_q, W_k, W_v$ 和当前的 $\vec{x_t}$ 计算对应向量:
\[\vec{q_t}=\vec{x_t}W_q \\ \vec{k_t}=\vec{x_t}W_k \\ \vec{v_t}=\vec{x_t}W_v \\\]此时生成的 $\vec{q_t}, \vec{k_t}, \vec{v_t}$ 都只是行向量而不是大矩阵,因此很明显由 矩阵-矩阵乘法(GEMM) 退化为了 矩阵-向量乘法(GEMV),计算量大大减小。需要注意的是,这种退化成立的前提是 batch size = 1;当 batch 增大后,多个请求的 query 会重新拼成矩阵,又回到 GEMM(这一点会在第五节展开)。当前的 query vector $\vec{q_t}$ 与完整的 $K_{new}$ 计算 attn score,并作用于:
将最新的 $\vec{k_t}, \vec{v_t}$ 追加写入显存中的 cache 区域,为生成第 $t+1$ 个 token 做好准备,这就是 KV Cache。
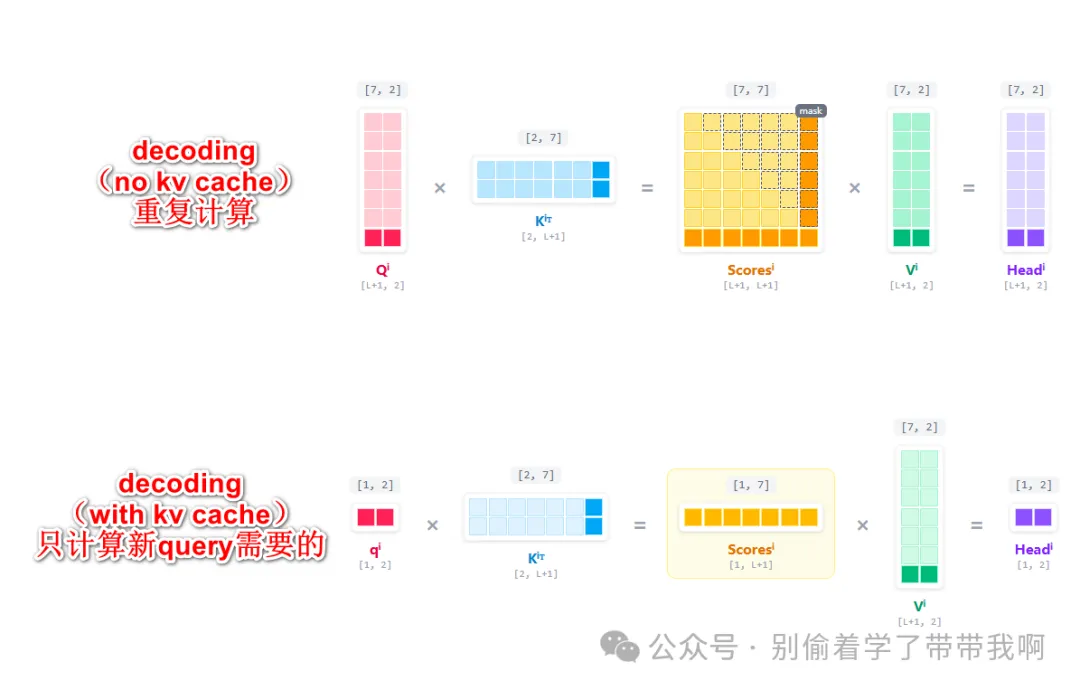
这也顺带回答了一个常见疑问:为什么没有 Q Cache? 因为 decode 阶段每一步真正参与计算的只有当前 token 对应的那一行 $q$ 向量,历史 $Q$ 的信息在后续步骤中不再被使用,自然无需缓存。
三、KV Cache 带来的新问题:从“救星”到“瓶颈”
KV Cache 的本质是 空间换时间。它确实节省了计算量,却把压力转嫁到了显存上。
3.1 显存占用
每个 token 需要缓存的显存量近似为:
\[\text{Mem} = 2 \times n_\text{layers} \times n_\text{heads} \times d_\text{head} \times P_\text{precision}\]其中:
2:K 和 V 两个矩阵;n_layers:模型层数;n_heads × d_head:等价于隐藏维度d_model;P_precision:数值精度(FP16 = 2 bytes,FP32 = 4 bytes)。
以 Llama-2-7B(标准 MHA)为例,n_layers = 32、d_model = 4096。当上下文长度达到 4K 时,单个序列的 KV Cache 已经占用 GB 级显存;一旦推理并发上来(例如 batch size = 32 甚至更大),即使是 80GB 的 A100 也会迅速被 KV Cache 吃满。
3.2 显存带宽:真正的“内存墙”
比显存容量更棘手的,是 显存带宽。GPU 中 HBM(显存)和 SRAM(计算单元)是两个独立的物理结构,attention 的实际计算发生在 SRAM 中,而缓存的 $K$、$V$ 存放在 HBM 中。每一步 decode 都需要把 KV Cache 从 HBM 搬运到 SRAM,搬运的速度由显存带宽决定。
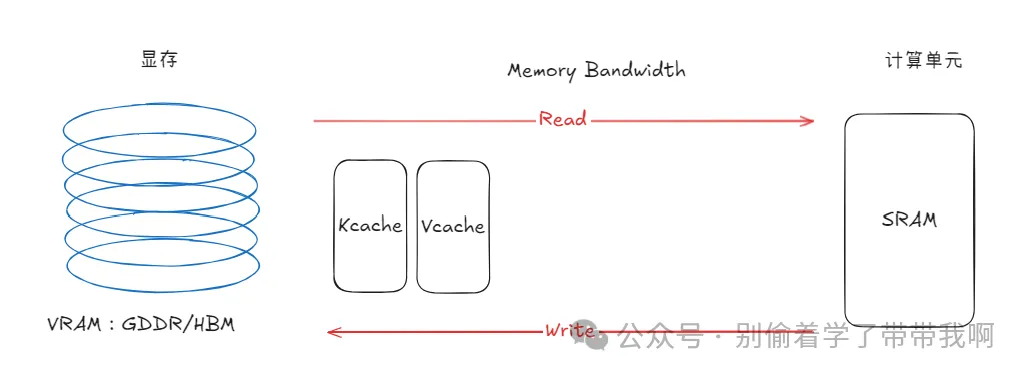
| 架构 | 显卡 | 显存带宽 | FP16/BF16 算力 | 显存类型 |
|---|---|---|---|---|
| Volta | Tesla V100 | 900 GB/s | ~125 TFLOPS | HBM2 |
| Turing | Titan RTX | 672 GB/s | ~130 TFLOPS | GDDR6 |
| Ampere(计算卡) | A100 | 2039 GB/s | 312 TFLOPS | HBM2e |
| Ampere(游戏卡) | RTX 3090 Ti | 1008 GB/s | ~160 TFLOPS | GDDR6X |
| Hopper | H100(SXM) | 3352 GB/s | 989 TFLOPS | HBM3 |
| Ada Lovelace | RTX 4090 | 1008 GB/s | ~330 TFLOPS | GDDR6X |
以 Llama-7B(FP16)为例,权重约 14GB,假设 KV Cache 累积到 1GB,每生成一个 token 就要搬运约 15GB 数据。在 A100(带宽约 2 TB/s,算力 312 TFLOPS)上:
- 搬运耗时: 15 GB/2000 GB/s = 7.5 ms
- 计算耗时: 7B 模型大约对应 14G FLOPS。A100 算力 312 TFLOPS。计算时间 ≈ 0.04 ms
- 搬运 / 计算 ≈ 187.5 倍
也就是说,绝大部分时间 GPU 的计算单元都在“摸鱼”等数据。这正是所谓的 内存墙(Memory Wall):decode 阶段是典型的 访存受限(Memory-bound) 场景,而非计算受限。可以通过下列公式计算:
\[\text{Latency} \approx \frac{\text{Model Weights} + \text{KV Cache Size}}{\text{Memory Bandwidth}}\]3.3 优化方向:从公式里能动什么?
回看 KV Cache 的显存公式:
\[Size_{token} = 2 \times n_{layers} \times n_{heads} \times d_{head} \times P_{precision}\]逐项排除:
- 2:自注意力机制的根基,不能动;
- $n_{layers}$:决定模型深度与抽象能力,动了容易“降智”;
- $d_{head}$:通常为 128,决定每个头的特征容量,砍了同样伤模型质量;
- $P_{precision}$:可以走低比特量化(INT8 / INT4),属于另一条正交的优化路线,可叠加使用;
- $n_{heads}$:相对“可动”的维度,尤其是其中的 KV Head 数量。
由此自然引出了核心问题:我们真的需要那么多 KV Head 吗? 这就是 MQA、GQA、MLA 出现的根本动机。
四、MQA / GQA / MLA:从架构层“瘦身”KV Cache
通过减少需要缓存的键值头数(num_key_value_heads),可以直接缩小 KV Cache 的体积,从而缓解显存带宽压力。
MQA(Multi-Query Attention):所有 Query Head 共享 同一组 Key/Value Head,KV Cache 大小相对 MHA 直接减少 n_heads 倍。代价是模型质量通常会出现可感知下降。其直接结果就是 $n_{kv}=1$。
GQA(Grouped-Query Attention):将 Query Head 分成若干组,每组共享一组 KV Head。Group 数即最终的 KV Head 数,是介于 MHA 与 MQA 之间的折中方案,可在推理速度和模型质量之间灵活权衡。Llama-2/3、Qwen 系列等均采用 GQA。这里的 Group 数就是最终 KV Head 的数量,即 $n_{kv}=g$ ,每个 KV Head 负责服务的 Query Head 数量为 $\frac{n_{heads}}{n_{kv}}$
MLA(Multi-head Latent Attention):DeepSeek 提出的另一条思路,不直接减少 KV Head 数量,而是通过低秩潜在表示在计算图层面重构 Attention 结构,使得真正需要缓存到 HBM 的张量被显著压缩,同时尽量保持模型表达能力。
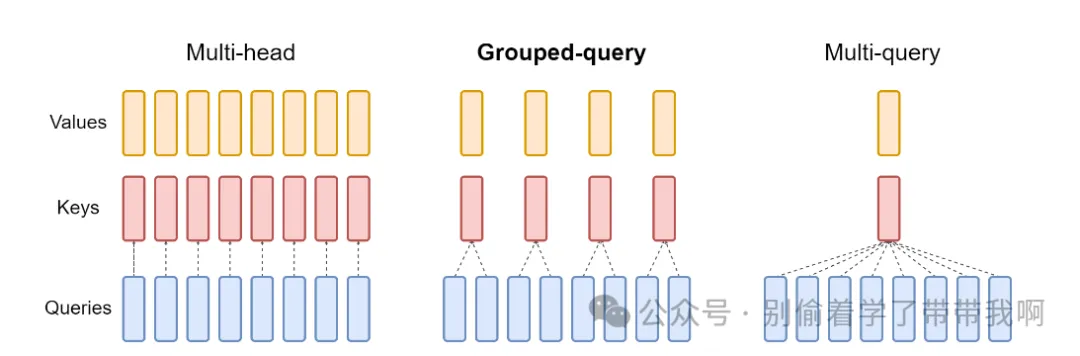
三者目标一致——压缩 KV Cache、突破内存墙——但路径不同:MQA/GQA 走“物理瘦身”,MLA 走“结构重构”。具体的实现细节、各自的优缺点与工程难点,将在后续篇章中展开。
MHA、MQA、GQA 三者其实改动很小,思想上就是从KV完全一一对应到份组对应。所以代码结构几乎完全相同。我们可以用一份代码去看出改动区别。
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class UnifiedAttention(nn.Module):
"""MHA/GQA/MQA 统一实现,只靠 num_kv_heads 区分。"""
def __init__(self, d_model, num_heads, num_kv_heads=None):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.head_dim = d_model // num_heads
# ---------- [差异1] KV 头数 ----------
# MHA: num_kv_heads == num_heads(默认)
# GQA: num_kv_heads < num_heads,比如 2
# MQA: num_kv_heads = 1
self.num_kv_heads = num_kv_heads if num_kv_heads is not None else num_heads
self.num_kv_groups = num_heads // self.num_kv_heads
assert num_heads % self.num_kv_heads == 0
# ---------- [差异2] K/V 投影维度随 KV 头数缩小 ----------
self.q_proj = nn.Linear(d_model, d_model, bias=False)
self.k_proj = nn.Linear(d_model, self.num_kv_heads * self.head_dim, bias=False)
self.v_proj = nn.Linear(d_model, self.num_kv_heads * self.head_dim, bias=False)
self.out_proj = nn.Linear(d_model, d_model, bias=False)
def forward(self, x):
B, L, _ = x.shape
q = self.q_proj(x).view(B, L, self.num_heads, self.head_dim).transpose(1, 2)
k = self.k_proj(x).view(B, L, self.num_kv_heads, self.head_dim).transpose(1, 2)
v = self.v_proj(x).view(B, L, self.num_kv_heads, self.head_dim).transpose(1, 2)
# ---------- [差异3] GQA/MQA 需要把 KV 头复制到和 Q 一样多 ----------
if self.num_kv_groups > 1:
k = k[:, :, None, :, :].expand(B, self.num_kv_heads, self.num_kv_groups, L, self.head_dim)
k = k.reshape(B, self.num_heads, L, self.head_dim)
v = v[:, :, None, :, :].expand(B, self.num_kv_heads, self.num_kv_groups, L, self.head_dim)
v = v.reshape(B, self.num_heads, L, self.head_dim)
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.head_dim)
output = torch.matmul(F.softmax(scores, dim=-1), v)
return self.out_proj(output.transpose(1, 2).contiguous().view(B, L, self.d_model))
mha = UnifiedAttention(d_model=512, num_heads=8, num_kv_heads=8)
gqa = UnifiedAttention(d_model=512, num_heads=8, num_kv_heads=2)
mqa = UnifiedAttention(d_model=512, num_heads=8, num_kv_heads=1)
其实所有的差异都是为了引入 num_kv_heads 变量,以 num_heads=32 为例:
- MHA:原始实现中没有
num_kv_heads,K/V 头数天然等于num_heads - GQA:引入
num_kv_heads = 8,每 4 个 Q 头共享 1 组 KV(共 8 组,num_heads / num_kv_heads = 32 / 8 = 4) - MQA:引入
num_kv_heads = 1,所有 32 个 Q 头共享同一组 KV
通过 config.json 其实能直观的看出来不同 attention 区别。num_attention_heads 和 num_key_value_heads 的数量对比,同样多的就是MHA,num_key_value_heads 少于 num_attention_heads 就是MQA或者GQA,如果 num_key_value_heads = 1 就是MQA了,如果不是1,那就是GQA了。
第二个修改是 nn.Linear ,因为 KV 头数变少了,K 和 V 的投影矩阵(权重矩阵)变小了,参数量也随之减少。
# ---------- [差异2] K/V 投影维度随 KV 头数缩小 ----------
self.q_proj = nn.Linear(d_model, d_model, bias=False)
self.k_proj = nn.Linear(d_model, self.num_kv_heads * self.head_dim, bias=False)
self.v_proj = nn.Linear(d_model, self.num_kv_heads * self.head_dim, bias=False)
self.out_proj = nn.Linear(d_model, d_model, bias=False)
还是以 d_model=512, num_heads=8, head_dim=64 为例:
- Q 投影:三者相同,始终是
Linear(512, 512),输出维度 =num_heads × head_dim = 8 × 64 = 512 - K/V 投影:这里是差异点:
- MHA: Linear(512, 512)
- GQA (kv=2): Linear(512, 128)
- MQA (kv=1): Linear(512, 64)
直观点理解:在这个例子中每个 head 的投影维度是 64,Q 始终保持完整的 8 个 head,输出维度为 8×64=512 ;而 KV 的输出维度取决于 KV head 的数量:GQA 有几组 KV head 就乘几个 64,MQA 则只有 1 组,输出维度仅为 64。本质上,k_proj 和 v_proj 的输出维度从 num_heads × head_dim 变成了 num_kv_heads × head_dim ,KV 头数越少,投影矩阵越小。这样一来,KV Cache所需要缓存的内容就变少了。
第三个修改,因为 Q 有 8 个头,而 KV 可能只有 1 个头(MQA)或 N个头(GQA),矩阵形状对不上,没法直接做点积计算:
\[Attention: Score=Q@K^T\]如果是MQA,Q 和 K 的头数维度不同,需要显式处理才能进行批量矩阵乘法。GQA也是同理。
Q: [B, 8, L, 64] ← 8 个头
K: [B, 1, L, 64] ← 1 个头 (MQA)
K^T: [B, 1, 64, L]
Q @ K^T = [B, 8, L, 64] @ [B, 1, 64, L] = ??? ← 第二维 8≠1,需要扩展
所以在这里,我们要做一个复制或者广播操作。
以 MQA(num_heads=8, num_kv_heads=1)为例:
- 只有 1 组 KV,但有 8 个 Q 头
- 计算时,
Q[0]~Q[7]都要和同一个 K/V 做 attention - 为了让矩阵运算能批量进行,把唯一的 K 复制 8 份:
[K] → [K, K, K, K, K, K, K, K]
复制前: Q: [B, 8, L, 64] K: [B, 1, L, 64] ← 形状不匹配,无法 matmul
复制后: Q: [B, 8, L, 64] K: [B, 8, L, 64] ← 形状匹配,可以批量计算
实际计算:
Q[0] × K[0] → Attention Score[0]
Q[1] × K[0] → Attention Score[1] (同一个 K)
Q[2] × K[0] → Attention Score[2] (同一个 K)
...
Q[7] × K[0] → Attention Score[7] (同一个 K)
再看看以 GQA(num_heads=8, num_kv_heads=2):
- 有 2 组 KV,8 个 Q 头,每 4 个 Q 头共享 1 组 KV
- Q[0]Q[3] 共享 K[0],Q[4]Q[7] 共享 K[1]
- 每组 KV 复制 4 份:
[K0, K1] → [K0, K0, K0, K0, K1, K1, K1, K1]
复制前: Q: [B, 8, L, 64] K: [B, 2, L, 64] ← 形状不匹配
复制后: Q: [B, 8, L, 64] K: [B, 8, L, 64] ← 形状匹配
实际计算:
Q[0] × K[0] → Score[0] ─┐
Q[1] × K[0] → Score[1] │ 共享 K[0]
Q[2] × K[0] → Score[2] │
Q[3] × K[0] → Score[3] ─┘
Q[4] × K[1] → Score[4] ─┐
Q[5] × K[1] → Score[5] │ 共享 K[1]
Q[6] × K[1] → Score[6] │
Q[7] × K[1] → Score[7] ─┘
从代码上可以看出来,这种做法本质上说有损的。MHA我们知道是Q和KV是一对一的。一定程度上是有点冗余,但是也得到了理论上最好的输出效果,但是一旦想着减少KV的数量,那么输出自然就随之降低了。这种人为的减少,代表着质量的下降。MQA就是减少的太多了,导致质量不理想。所以我们才有了GQA(目前仍是主流),减少一部分,但是又没到质量不能看的地步。
五、MQA/GQA 的优化目标
前面我们分析了 MQA/GQA 如何通过减少 KV 头数来降低 KV Cache 的显存占用。但这种优化真的能带来实质性的推理加速吗?要回答这个问题,我们需要深入分析 Decode 阶段的数据传输瓶颈。
首先明确一点,优化的核心问题是 一体两面 的两个问题:
- 显存占用:优化前的 KV Cache 太大了,MQA/GQA 能压缩多少?
- 显卡利用率:带宽不足和显存占用导致 latency,计算资源一直在空转等待,最终落到 compute-bound 和 memory-bound 的平衡问题。
在 Decode 阶段,每生成一个新 token,GPU 需要从 HBM(高带宽显存)读取两类数据:
- 模型权重:包括 Q/K/V 投影矩阵、FFN 权重等,这些参数在整个推理过程中保持不变
- KV Cache:历史 token 的 K 和 V 缓存,随着序列长度增长而线性增长
我们以一个具体的例子来量化分析。需要说明的是,这里换用了一组更接近常见部署卡(A6000 级别,带宽 768 GB/s、FP16 稠密算力约 155 TFLOPS)的参数,与第三节中用 A100(2 TB/s、312 TFLOPS)估算的数字并不冲突,只是硬件不同、量级一致。假设模型配置如下:
- 模型参数量:7B(70 亿参数)
- 层数 $n_{layer}$:32 层
- 注意力头数 $n_h$:32 个
- 每头维度 $d_h$:128
- 隐藏层维度 $d_{model}$:$n_h \times d_h = 32 \times 128 = 4096$
- 精度:FP16(2 字节)
- Model Weights:~13.5GB
- Context Length:4096
- Memory Bandwidth:768 GB/s
- Peak Compute:155 TFlops
5.1 传输延时
MHA模式下,每个token的KV Cache占用:
\[2 \times \underbrace{32}_{\text{layers}} \times \underbrace{32}_{\text{heads}} \times \underbrace{128}_{d_{head}} \times 2\text{ bytes} = 0.5\text{ MB}\]算上 context length 为 4096 时,整个 KV Cache size = $0.5 MB \times 4096 \approx 2 GB$。
每次decoding要搬运的数据:
- Weights: ~13.5 GB
- KV Cache: ~2 GB
- 总计: ~15.5 GB
假设显存带宽768 GB/s,理想情况下:
\[\text{搬运时间}=\frac{15.5\text{ GB}}{768\text{ GB/s}} \approx 20.2\text{ ms}\\\text{计算时间} \approx \frac{14 \text{ GFLOPs}}{155000 \text{ GFLOPs}} \approx 0.09 \text{ ms}\]二者差了约 224 倍,是明显的内存墙。
5.2 KV Cache 压缩
如果换成 GQA 和 MQA 会怎样?
GQA-8 下,4个 Query 共享1组 KV Head ,$n_{kv}=8$:
\[Size_{token}=2 \times 32 \times 8 \times 128 \times 2=0.125 \text{ MB} \\ \text{KV Cache} = 0.125 \times 4096 =0.5 \text{ GB}\]比MHA的2GB减少了75%。搬运时间:$\frac{13.5\text{ GB}+0.5\text{ GB}}{768\text{ GB/s}} \approx 18.2 ms$
MQA ($n_{kv}= 1$)下,所有 Query 共享一组 KV Head:
\[Size_{token}=2 \times 32 \times 1 \times 128 \times 2=0.016 \text{ MB} \\ \text{KV Cache} = 0.016\times 4096 =64 \text{ MB}\]比MHA减少了97%。搬运时间:$\frac{13.5\text{ GB}+0.064\text{ GB}}{768\text{ GB/s}} \approx 17.7 ms$
关键发现:虽然 GQA 将 KV Cache 降低了 75%,但由于模型权重占据了绝大部分数据传输量(约 96%),实际的总传输量只降低了约 10%(20.2 ms → 18.2 ms)。这意味着在 batch size = 1 的场景下,MQA/GQA 带来的加速效果非常有限。
5.3 Batch Size 的影响
那么 MQA/GQA 在什么情况下才能发挥作用呢?答案是增大 batch size。
当 batch size 增大时:
- 模型权重:所有样本共享,传输量保持不变(13.5 GB)
- KV Cache:每个样本都需要独立的缓存,传输量线性增长
当 Batch Size 提升之后,计算时间会线性增长(GEMV → GEMM),而搬运时间的结构和计算时间不一样,因为模型权重是所有请求共享的。
把两者写成 Batch Size 的函数,计算时间是标准的线性函数,过原点:
\[T_{compute}(\text{Batch Size})=t_c \cdot \text{Batch Size}\]其中,$ t_c = \frac{\text{FLOPs}_{\text{per_token}}}{\text{Peak Compute}} = \frac{14 \text{ GFLOPS}}{155 \text{ TFLOPS}} \approx 0.09 \text{ ms} $。每多一个请求,计算时间就多 0.09 ms。
而搬运时间则是仿射函数多了一个截距:
\[T_{\text{memory}}(BS) = \underbrace{\frac{C_{kv}}{BW}}_{\text{斜率 } a} \cdot BS + \underbrace{\frac{W}{BW}}_{\text{截距 } b}\]其中 $W$ 是模型权重(13.5 GB),$C_{kv}$ 是单个请求的 KV Cache,$BW$ 是显存带宽(768 GB/s)。
关键就在于截距 $b=\frac{W}{BW}=\frac{13.5}{768} \approx 17.6 \text{ ms}$ 这部分,不管 Batch Size 是 1 还是 100,这 13.5 GB 的权重都只搬一次。Batch Size 越大,这个固定开销被均摊到每个请求上的份额就越小。
而斜率 $a$ 取决于使用哪种 attn 方案:
| 方案 | $C_{kv}$(seq=4096) | 斜率 $a=C_{kv}/BW$ |
|---|---|---|
| MHA | 2 GB | 2.604 ms |
| GQA-8 | 512 MB | 0.667 ms |
| MQA | 64 MB | 0.083 ms |
只要 Batch Size 够大,计算时间总有可能追上搬运时间,前提是计算的斜率 $t_c$ 比搬运的斜率 $a$ 更陡。
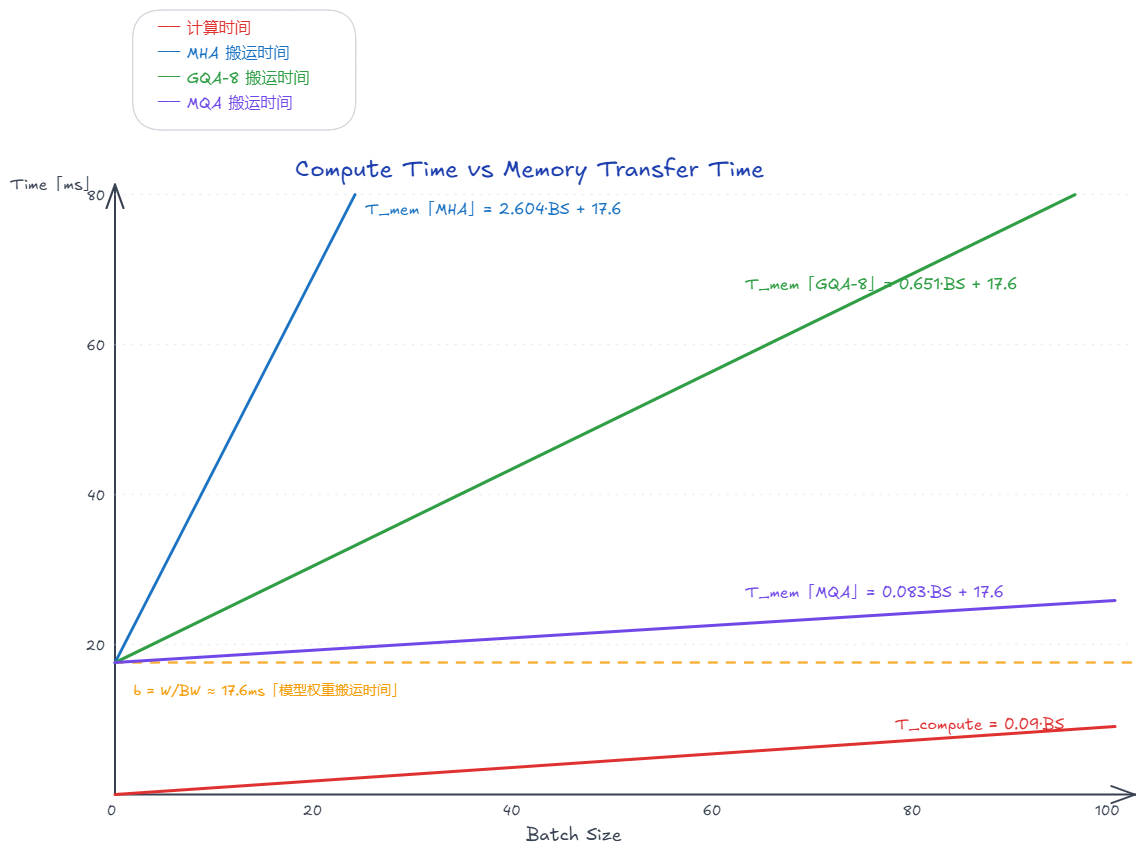
由此可见 MQA/GQA 的优化目标可以归纳为:
- 降低 KV Cache 显存占用:通过减少 KV 头数,使得相同显存容量下可以支持更长的序列或更大的 batch size
- 提升大 batch 场景下的吞吐量:当 batch size 足够大时,KV Cache 的传输量占比提升,MQA/GQA 的加速效果才能充分体现
- 缓解内存墙问题:在 Decode 阶段,计算强度低,访存成为瓶颈。减少 KV Cache 的访存量可以一定程度上缓解这一问题
实际应用中的权衡:
- 小 batch 场景(如在线服务、单用户交互):MQA/GQA 的加速效果有限,但可以节省显存,支持更长的上下文
- 大 batch 场景(如离线批处理、高并发服务):MQA/GQA 的加速效果显著,同时显存节省允许更大的并发量
- 质量考量:GQA 在质量和效率之间取得了较好的平衡,是当前主流选择;MQA 虽然效率最高,但质量损失较大
这也解释了为什么 Llama-3、Qwen2.5 等主流模型都采用 GQA 而非 MQA:在实际部署中,既要保证模型质量,又要在大 batch 场景下获得显著的推理加速。
六、MLA(Multi-head Latent Attention)
前面我们看到,MQA/GQA 通过减少 KV 头数来压缩 KV Cache,但这种”物理瘦身”不可避免地会带来一定的质量损失。DeepSeek 提出的 MLA(Multi-head Latent Attention)则走了另一条路:不减少头数,而是通过低秩分解在结构层面重构 Attention,实现”几乎无损”的 KV Cache 压缩。
MLA 的设计哲学是:与其直接减少 KV 头数(有损压缩),不如通过低秩投影将高维的 K、V 压缩到低维的潜在空间(latent space),只缓存压缩后的低维表示。
传统 MHA 中,每个 token 需要缓存的是:
\[K, V \in \mathbb{R}^{n_{\text{heads}} \times d_{\text{head}}} = \mathbb{R}^{d_{\text{model}}}\]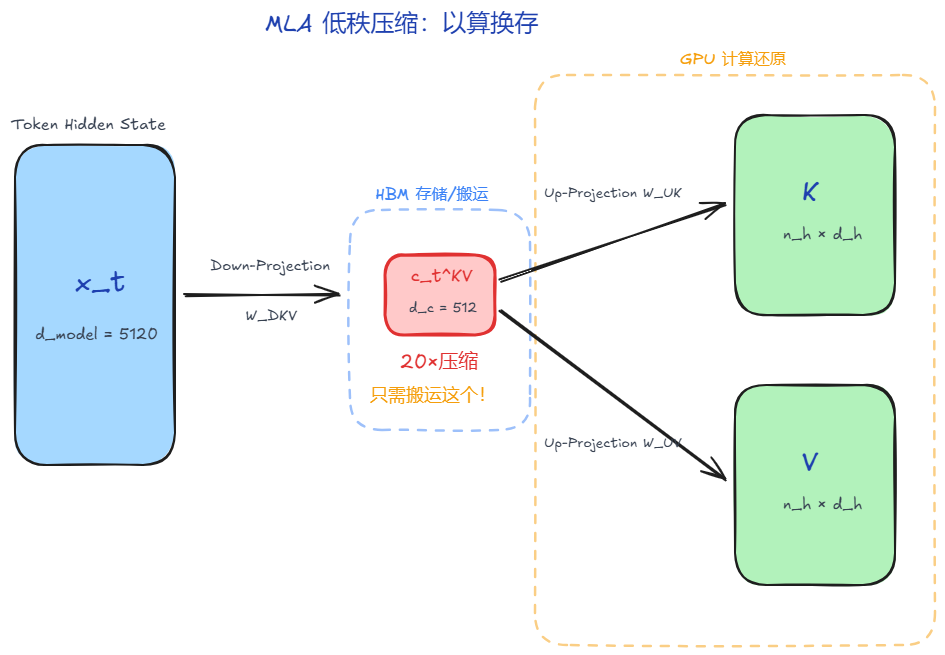
对于 Llama-2-7B($d_{\text{model}} = 4096$),每个 token 需要缓存 $2 \times 4096 = 8192$ 个 FP16 数值。
MLA 的做法是:引入一个低秩压缩矩阵 $W_{DKV}$,将原始的 K、V 投影到低维空间:
\[c_t^{KV} = x_t \cdot W_{DKV}, \quad W_{DKV} \in \mathbb{R}^{d_{\text{model}} \times d_c}\]其中 $d_c \ll d_{\text{model}}$(例如 $d_c = 512$),这样每个 token 只需要缓存 $d_c$ 维的压缩表示 $c_t^{KV}$,而不是完整的 $2 \times d_{\text{model}}$ 维的 K、V。
乍一看,这种做法似乎只是把问题推迟了:虽然缓存的是压缩后的 $c^{KV}$,但在计算 Attention 时不还是要把它还原回高维的 K、V 吗?
\[K = c^{KV} \cdot W_{UK}, \quad V = c^{KV} \cdot W_{UV}\]这样一来,每次 Decode 都要做一次解压(矩阵乘法),岂不是”以算换存”的代价太大?
MLA 的关键创新在于:通过矩阵结合律,将解压矩阵吸收进 Q 的投影权重,从而完全跳过解压步骤。
传统 MHA 的 Attention Score 计算:
\[\text{Score} = Q \cdot K^T = (x_t W_Q) \cdot (c^{KV} W_{UK})^T\]利用矩阵结合律重新组合:
\[\text{Score} = x_t \cdot (W_Q W_{UK}^T) \cdot (c^{KV})^T = x_t \cdot W_Q' \cdot (c^{KV})^T\]其中 $W_Q’ = W_Q W_{UK}^T$ 可以在模型加载时预先合并,这样在推理时:
- 缓存的是:低维的 $c^{KV} \in \mathbb{R}^{d_c}$
- 计算时直接用:$Q’ \cdot (c^{KV})^T$,无需解压
这样就实现了”只搬运低维数据,直接在压缩空间计算”,完全避免了解压开销。用一段最小代码可以直观看到”矩阵吸收”是怎么回事:
import torch
d_model, n_heads, d_head, d_c = 4096, 32, 128, 512
W_Q = torch.randn(d_model, n_heads * d_head) # Q 投影
W_UK = torch.randn(d_c, n_heads * d_head) # K 的上投影(解压矩阵)
# 朴素做法:先把 c 解压回 K,再算 score
def naive(x_t, c_kv):
q = x_t @ W_Q # [B, n_heads*d_head]
k = c_kv @ W_UK # 解压:[B, n_heads*d_head]
return q @ k.T
# 矩阵吸收:把 W_UK 预先合并进 Q 的投影,推理时无需解压
W_Q_absorbed = W_Q @ W_UK.T # [d_model, d_c],加载时算一次
def absorbed(x_t, c_kv):
q_prime = x_t @ W_Q_absorbed # [B, d_c]
return q_prime @ c_kv.T # 直接在压缩空间 (d_c=512) 上做内积
# 两者数值等价,但 absorbed 只搬运/计算 d_c=512 维,而非 n_heads*d_head=4096 维
以 Llama-2-7B 为例($d_{\text{model}} = 4096$,$n_{\text{heads}} = 32$,$d_{\text{head}} = 128$),假设 MLA 的压缩维度 $d_c = 512$:
| 方案 | 每 Token 缓存维度 | 单层 Cache(seq=4096) | 压缩比 |
|---|---|---|---|
| MHA | $2 \times 4096 = 8192$ | 64 MB | 1× |
| GQA-8 | $2 \times 8 \times 128 = 2048$ | 16 MB | 4× |
| MQA | $2 \times 128 = 256$ | 2 MB | 32× |
| MLA | $512$ | 4 MB | 16× |
MLA 的压缩比介于 GQA 和 MQA 之间,但关键优势在于:几乎不损失模型质量。
MLA 的矩阵吸收技巧有一个前提:Q 和 K 的投影矩阵可以自由结合。但在使用 RoPE(旋转位置编码)的模型中,这个前提被打破了。
RoPE 的旋转矩阵 $R_{\theta}$ 卡在 $W_Q$ 和 $W_{UK}$ 之间:
\[\text{Score} = (x_t W_Q \cdot R_{\theta}) \cdot (c^{KV} W_{UK} \cdot R_{\theta})^T\]由于 $R_{\theta}$ 是位置相关的,无法预先合并到权重矩阵中,矩阵吸收失效。
DeepSeek 的解决方案:Decoupled RoPE
将 Q 和 K 拆分为两部分:
- 内容部分(Content):享受低秩压缩,维度为 $d_c$
- 位置部分(Position):独立存储 RoPE 编码,维度为 $d_{\text{rope}}$
最终 KV Cache 的结构变为:
\[\text{Cache} = [c^{KV}, k^{\text{rope}}]\]其中:
- $c^{KV} \in \mathbb{R}^{d_c}$:压缩后的内容表示(如 512 维)
- $k^{\text{rope}} \in \mathbb{R}^{d_{\text{rope}}}$:RoPE 位置编码(如 64 维)
这样只增加了约 12.5% 的存储开销($64 / 512$),但保留了 RoPE 的位置建模能力。
MLA 的另一个重要意义在于:通过减少访存量,有可能将 Decode 阶段从 Memory Bound 翻转为 Compute Bound。
回顾前面的分析,Decode 阶段之所以是 Memory Bound,是因为:
\[\frac{\text{计算量(FLOPs)}}{\text{访存量(Bytes)}} \ll \frac{\text{GPU 算力(FLOPS)}}{\text{显存带宽(Bytes/s)}}\]MLA 通过压缩 KV Cache,大幅降低了访存量,使得计算强度(Compute Intensity)提升。以 A6000 为例(FP16 稠密算力约 155 TFLOPS,带宽 768 GB/s,与第五节参数保持一致):
\[\text{翻转条件:} n_{\text{heads}} > \frac{\text{Peak Compute} \times 2}{4 \times \text{Bandwidth}} \approx 101\]- Llama-2-7B($n_{\text{heads}} = 32$):即使用 MLA,仍然是 Memory Bound
- DeepSeek-V2($n_{\text{heads}} = 128$):成功翻转为 Compute Bound
这也解释了为什么 DeepSeek-V2 特意设计了 128 个 head——head 数量直接决定了能否实现瓶颈翻转。
优势:
- 压缩比高:相比 MHA 可达 16× 压缩,接近 MQA 的效果
- 质量无损:通过低秩分解而非直接减少头数,模型表达能力几乎不受影响
- 可能翻转瓶颈:在足够多 head 的情况下,可以从 Memory Bound 转为 Compute Bound
局限:
- 训练成本:需要从头训练,无法像 GQA 那样从 MHA checkpoint 转换
- 实现复杂度:矩阵吸收、Decoupled RoPE 等技巧增加了工程实现难度
- 硬件要求:要实现瓶颈翻转,需要足够多的 head(通常 > 100),这对小模型不适用
MLA 代表了 KV Cache 优化的另一条技术路线:
- MQA/GQA:物理瘦身,直接减少 KV 头数,简单直接但有损
- MLA:结构重构,通过低秩分解压缩 KV Cache,复杂但几乎无损
两者并非互斥,而是针对不同场景的权衡:
- GQA 适合快速迭代、对质量要求不极致的场景(如 Llama、Qwen)
- MLA 适合追求极致性能、愿意投入训练成本的场景(如 DeepSeek-V2/V3)
从长期来看,随着模型规模和 head 数量的增长,MLA 这类”以算换存”的方案可能会成为主流——毕竟,算力在增长,但显存带宽的增长速度远远跟不上。
参考
- Ainslie, J., et al. (2023). GQA: Training generalized multi-query transformer models from multi-head checkpoints. arXiv:2305.13245
- Shazeer, N. (2019). Fast transformer decoding: One write-head is all you need. arXiv:1911.02150
- DeepSeek-AI. (2024). DeepSeek-V2: A strong, economical, and efficient mixture-of-experts language model. arXiv:2405.04434
- Hugging Face. Optimizing inference. Transformers Documentation
- NVIDIA. NVIDIA Ada Lovelace Architecture White Paper. PDF
- 苏剑林. 缓存与效果的极限拉扯:从 MHA、MQA、GQA 到 MLA. Science Spaces
- 原文参考:KV Cache(一):从 KV Cache 看懂 Attention(MHA、MQA、GQA、MLA)的优化