2026 年 3 月 31 日,Anthropic 发布 @anthropic-ai/claude-code v2.1.88 时出了一个低级失误:Bun 默认生成的 59.8 MB .js.map source map 文件没有被 .npmignore 排除。几小时内,约 1,900 个 TypeScript 源文件、512,000 行代码被全网镜像。这不是一次黑客攻击,而是一次人为的发布配置疏忽。次日 Anthropic 紧急发出 DMCA 下架请求,却因操作失误误删了约 8,100 个不相关仓库,引发社区二次震荡。
但真正值得关注的不是泄露本身,而是这些代码揭示的工程。
多数报道在追逐猎奇细节——隐藏功能、内部代号、虚拟宠物。这些噪音会随时间消散。六个月后依然有价值的,是架构。Claude Code 是目前使用最广泛的 AI 编程 Agent,它的源码揭示了一套经过大规模生产验证的工程模式。本文以源码暴露出的五层架构为主线,融合多方解读,试图说清一件真正重要的事:Claude Code 的引擎盖下,究竟是什么样子。
关于信息来源:本文基于此次泄露代码的公开分析与多方二手解读整理。文中涉及的具体数字(代码行数、token 数、API 调用量、命中率等)大多来自社区拆解,未必经过 Anthropic 官方确认,仅供理解架构时参考。此外需要强调一个前提:代码里存在 ≠ 产品里启用——泄露的源码中混杂着实验性逻辑、已废弃功能,以及 feature flag 关闭的未上线模块(如后文的 KAIROS),读到具体机制时请带着这层判断。
五层架构,从外到内
很多人以为 AI 编程工具不过是给模型 API 套一层终端界面。但 512,000 行代码、约 40 个内置工具、85 个斜杠命令、React + Ink 渲染的终端 UI、Bun 运行时——这分明是一个完整的生产级系统,而非简单的”套壳”封装。
从源码中可以辨认出五个清晰的层次:
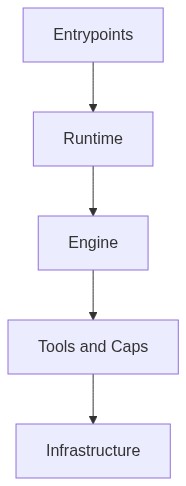
| 层级 | 核心职责 |
|---|---|
| 入口层 Entrypoints | CLI、桌面端、网页、IDE 插件、SDK——统一路由,标准化输入 |
| 运行层 Runtime | REPL 循环、TAOR 状态机、Hook 系统、任务队列 |
| 引擎层 Engine | QueryEngine 单例、动态提示词组装、流式响应、上下文压缩 |
| 工具与能力层 Tools & Caps | ~40 个内置工具、权限隔离、MCP 扩展协议、安全校验 |
| 基础设施层 Infrastructure | 认证、缓存、文件存储、远程控制、遥测、多代理隔离 |
这五层的关系不是简单的上下堆叠,而是围绕一个核心信条组织的:把 Agent loop 做得极简,把 loop 周围的 harness 做得极重。 512,000 行代码里,Agent 循环本身可能只有 20 行;剩下的全是上下文管理、权限系统、工具协议、错误恢复、记忆与压缩——这就是 Anthropic 所说的 harness engineering。
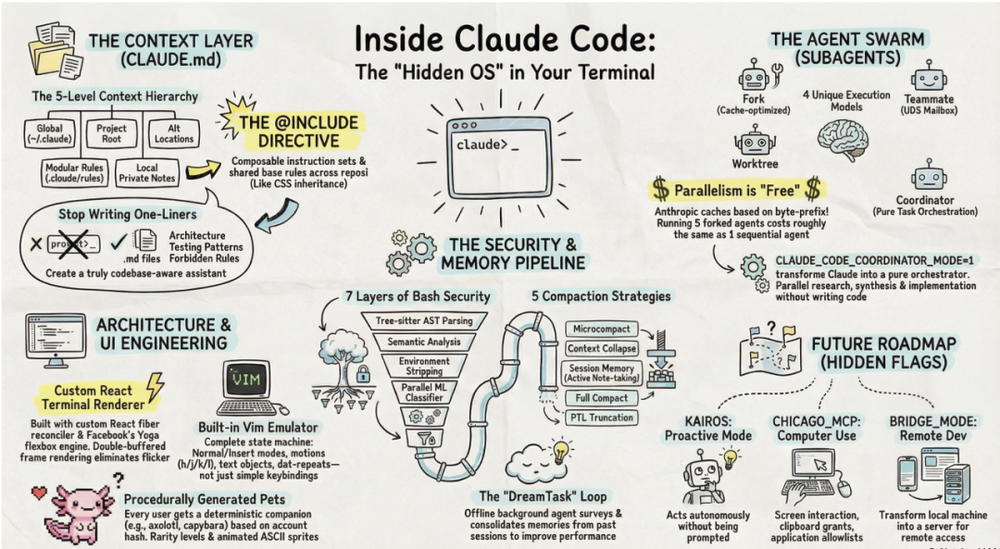 Claude Code 全局架构速览 | reddit
Claude Code 全局架构速览 | reddit
据说 Anthropic 内部的经验是:AI 产品的质量 60% 取决于模型能力,40% 取决于围绕模型搭建的 harness 系统——工具、安全、记忆、上下文管理。这 512,000 行代码,就是那 40%。
入口层(Entrypoints)
入口层的职责是:把用户侧碎片化的输入标准化,再向下传递。
entrypoints/cli.tsx 在极早期做 fast-path 分流——--version、MCP server 辅助模式、bridge / remote control、daemon、headless runner 等特殊模式在此短路返回,避免加载完整 CLI 运行时。
main.tsx(约 4,683 行)是真正的运行时编排器。它负责解析 CLI 参数、加载配置与策略、初始化 GrowthBook feature flags、处理 migrations,并路由到 interactive / non-interactive / remote / direct-connect / assistant 等模式。这说明 Claude Code 从第一天起就被设计为多端产品:CLI、桌面端、IDE 插件、SDK 共享同一套核心引擎,前端的变化不会污染核心逻辑。
运行层(Runtime)
运行层管理着每条命令的进出和状态流转。它的核心是一个极简的 TAOR 循环:Think → Act → Observe → Repeat(这个缩写来自社区解读,并非业界标准术语;其思想可追溯到后文提到的 ReAct)。翻译成代码,本质上就是一个 while 循环:
while (true) {
const response = await model.generate(messages);
if (!response.hasToolCall()) break;
const result = await executeTool(response.toolCall);
messages.push(response, result);
}
模型产生一条消息;如果包含工具调用,就执行工具,把结果追加到对话历史,继续循环;没有工具调用则停止,等待用户输入。所有状态都以不可变的 message 形式存在——仅从对话历史就能完整重建当前状态。
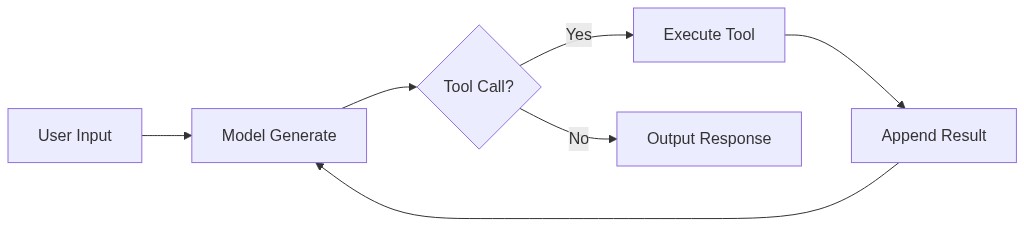
这个循环简单到令人惊讶,但这就是重点。很多团队构建第一个 Agent 时会去搞复杂的状态机、DAG 编排器或自定义控制流引擎。Claude Code 证明你不需要这些——一个基于 tool call 的 while 循环加上 message history 作为核心数据结构,就能覆盖绝大多数 Agentic 行为。
复杂度不在循环里,而在循环周围的 harness 中。运行层的 REPL 模块(约 5,005 行)要处理流式输出、权限对话框、工具执行进度、任务前后台切换、远程会话状态同步、消息滚动与恢复——可以把它理解成终端里的会话操作系统。
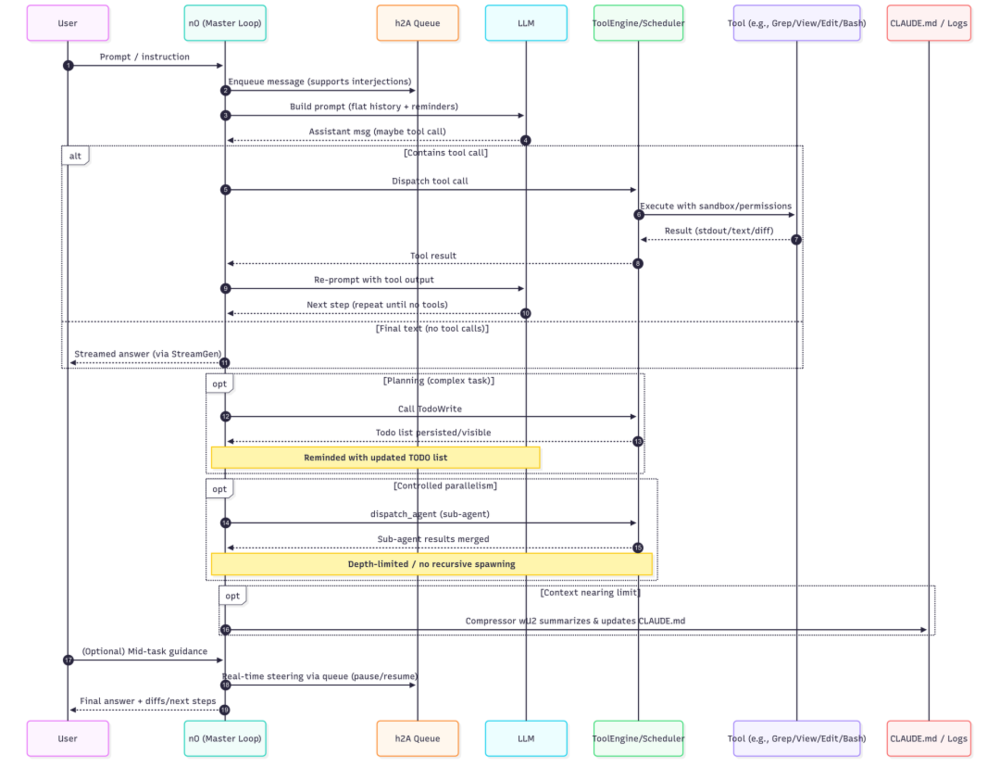 Claude Code HARNESS 视角解读 | vrungta.substack
Claude Code HARNESS 视角解读 | vrungta.substack
引擎层(Engine)
引擎层是系统的心脏,核心是 QueryEngine 单例,负责拼接上下文、管理提示缓存、处理流式响应和压缩对话,代码量接近 46,000 行。
动态提示词组装
Claude Code 没有一份静态 system prompt。它是数百个提示碎片在运行时动态拼装的结果——根据当前模式、可用工具、项目上下文的不同,系统注入不同的提示片段。光是安全守则就有约 5,677 个 token,相当于两万字的行为规范。这是把软件工程的模块化思想搬进了提示词管理。
引擎层使用 SYSTEM_PROMPT_DYNAMIC_BOUNDARY 模式,把静态指令(会话间不变)与动态上下文(会话相关)显式分离。这不仅是代码组织上的优化,更是缓存优化:静态内容命中 prompt cache,动态内容放在边界之后。据社区分析,团队还专门跟踪了多个会导致缓存失效的因素(cache-break vectors),监控到底是什么让缓存失效——因为在这个规模上,每一次缓存失效都直接等于真金白银。(这与后文基础设施层提到的 14 个缓存断点(cache breakpoints)是两个不同概念:前者是”什么会打断缓存”,后者是”在哪些位置切分缓存”。)
三层上下文压缩
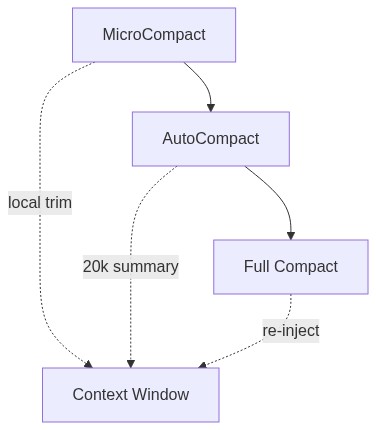
- MicroCompact:在本地裁剪旧的 tool 输出,零 API 调用,成本为零
- AutoCompact:接近上下文上限时触发,生成最多 20,000 token 的结构化摘要,内置连续 3 次失败即断路的熔断器
- Full Compact:全量压缩后,重新注入最近访问的文件(每文件上限 5,000 token)、活跃计划和 skill schema
据说一个 autocompaction 无限重试的 bug 曾经每天烧掉约 250,000 次 API 调用。上下文管理决策在这个规模上就是成本决策。
Coordinator Mode:多代理并行
引擎层里还有一个关键的多代理机制。CLAUDE_CODE_COORDINATOR_MODE=1 开启后,一个 Claude 实例充当协调者(Coordinator),通过 AgentTool 创建并管理多个 Worker Agent,在独立的 git worktree 里隔离执行。协调者不自己写代码,只负责分配任务和汇总输出。
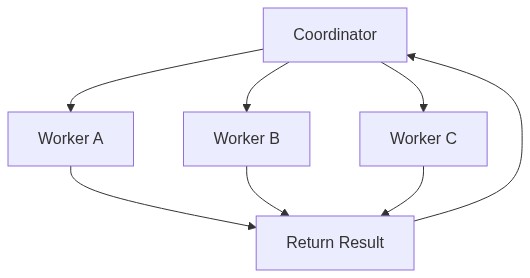
最精妙的是经济性设计:子 Agent fork 时,会创建与父上下文字节级一致的副本,从而共享 KV cache。子 Agent 只需要为自己独有的指令付费,而不是重复支付整个共享上下文的 token 成本。并行由此变得几乎免费——据说 Anthropic 用同样的 token 预算同时跑安全审计、模块重构、测试生成和文档编写,吞吐量接近串行的 4 倍。
工具与能力层(Tools & Caps)
约 40 个内置工具,每一个都是独立的、权限隔离的能力单元。工具基类的定义就有约 29,000 行 TypeScript。
专用工具优于通用 Shell
Claude Code 本可以只暴露一个 bash 工具就够用了,但它为常见操作都提供了专用工具。Bash 工具的 description 甚至会明确警告模型:不要用本工具来运行 find、grep、cat、head、tail、sed、awk 或 echo——请使用对应的专用工具。
| 通用 Shell 命令 | Claude Code 专用工具 |
|---|---|
grep, rg |
Grep(带类型参数,底层用 ripgrep) |
find, ls |
Glob(模式匹配,结果按修改时间排序) |
cat, head, tail |
Read(带行号,支持图片 / PDF) |
sed, awk |
Edit(精确字符串替换,要求先 Read) |
echo >, cat <<EOF |
Write(修改前强制先 Read) |
这样做的原因有三:可观测性——结构化调用产生结构化日志;安全性——每个工具有独立权限和校验逻辑;模型性能——专用工具的显式参数和丰富描述能帮模型更快选对动作。
把安全嵌入使用点
大多数 Agent 框架把安全交给单独的配置层:权限文件、guardrails、内容过滤器。Claude Code 的做法不同——安全规则直接嵌入在工具描述里,就在模型每次调用时能看到的位置。比如 Bash 工具的 description 里明确写着:
- NEVER run destructive git commands (push --force, reset --hard,
clean -f, branch -D) unless the user explicitly requests
- CRITICAL: Always create NEW commits rather than amending
LLM 在行动附近看到约束时,远比在遥远的 system prompt 段落里更不容易”遗忘”。
六层权限防线
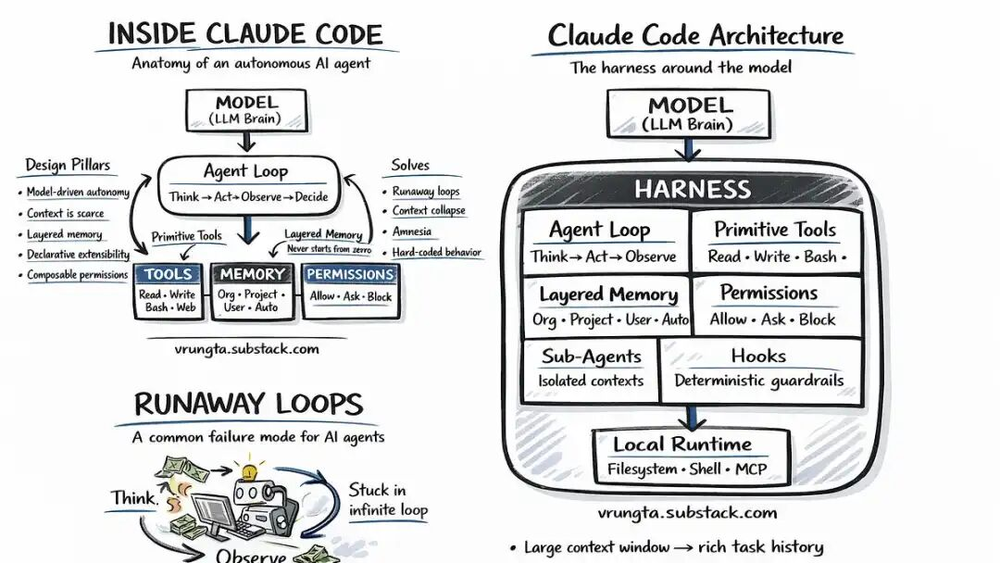 Agent 的六层防线与 useCanUseTool.tsx
Agent 的六层防线与 useCanUseTool.tsx
每一个工具调用在真正执行前,要经过六层检查:
- 白名单过滤:项目和用户配置直接过滤掉不在允许范围内的操作
- 自动模式分类器:判断此操作在无人值守时是否安全
- 协调者门控:针对 Coordinator 编排层做授权验证
- Swarm 工作者门控:针对子代理执行做授权验证
- Bash 安全分类器:23 条具体规则,覆盖 Zsh 等号扩展、Unicode 零宽字符注入、IFS 空字节注入等攻击向量——规则的具体程度说明 Anthropic 在真实运行中遇到过这些攻击
- 交互式用户确认:弹窗或桥接审批
设计哲学是每一层独立失败。不是只靠最终确认才放行,而是任何一层发现问题就停下来。纵深防御,不是单点守门。
基础设施层(Infrastructure)
除了认证、文件存储、缓存这些常规基建,基础设施层有几个容易被忽略但至关重要的设计。
14 个缓存断点与粘性锁存器
提示缓存架构用粘性锁存器(sticky latch)管理 14 个缓存断点,防止模式切换导致缓存失效。之所以如此精细,是因为每一次缓存失效都直接等于花钱——在 Claude Code 的用户规模下,哪怕缓存命中率下降 1%,一天的额外 API 调用成本就是一个惊人的数字。
远程控制机制
GrowthBook 提供远程 kill switch,可以针对特定用户禁用功能。Policy Limits 每小时轮询一次,服务端可以远程禁用工具或限制功能。企业版甚至支持远程推送 settings.json 覆盖本地配置。这意味着 Claude Code 的行为边界不完全由本地配置决定,也由 Anthropic 服务端实时定义——它不只是一个本地工具,更像是一个持续受控的服务。
这套架构,借鉴了人类的大脑
从技术谱系上看,Claude Code 的 TAOR 循环脱胎自 ReAct(Yao et al., 2022),但在此基础上加了 MCP 协议、git worktree 隔离和多层记忆系统。记忆分层的思路直接来自认知科学,与人类记忆分类高度对应:
- Semantic 层:稳定知识,类似长期语义记忆。只写入高信号内容,矛盾信息自动剔除,用 RAG 检索而非全量加载
- Episodic 层:过去的对话序列,类似情景记忆。按时间索引,按需检索
- Working 层:当前任务的动态上下文窗口,类似工作记忆。超出限制时用指针代替内容,保持轻量
核心信条永远是:不要把所有东西都塞进上下文窗口。存索引,按需拉取。
MEMORY.md 是一个始终加载的轻量索引文件,通常不超过 200 行,每行是一个指向详细 topic file 的指针。真正详细的笔记分散在 debugging.md、patterns.md 等文件中,按需获取而非默认加载。
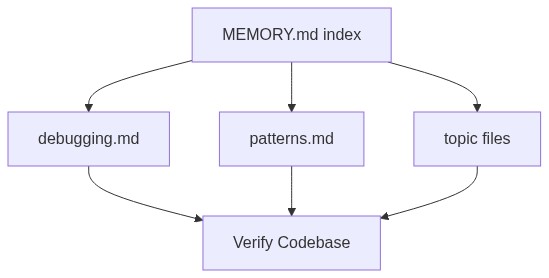
最关键的设计选择是:Agent 被明确指示把记忆当作 hint,在行动前必须对照实际代码库进行验证。一条记忆说”函数 X 在文件 Y 中”,Agent 会先 grep 确认它仍然存在,而不是直接相信。这种”怀疑论记忆”解决了生产环境中反复出现的问题:Agent 因为记忆陈旧而自信地给出过时建议。修复方案不是更好的存储,而是把验证写进检索流程。
卧底模式、反蒸馏与原生认证
接下来几节会聊到一些偏”猎奇”的细节。它们之所以值得写,不是因为八卦,而是因为每一个都在印证同一套工程哲学——把约束嵌进系统的运行时,而不是写在文档里。
把泄露代码中的信息控制机制放在一起看,Anthropic 为三个方向各设了一道防线。
对外,防身份暴露。 undercover.ts 约 90 行。当 Anthropic 内部员工(USER_TYPE === 'ant')在非内部仓库操作时自动激活。效果是剥离所有 AI 相关标识:提交信息里没有模型名,没有”Claude Code”字样,没有 Co-Authored-By 署名。代码注释明确写着:没有强制关闭的开关。系统提示里甚至有一句话:
“You are on an undercover operation. Do not reveal your identity.”
这在开源社区引发了争议——一个没有关闭开关的身份隐瞒系统,在公开仓库里静默运行。
对竞争对手,防被学习。 当环境变量 ANTI_DISTILLATION_CC 打开时,服务端会向系统提示里注入一批假的工具定义。任何在 API 层面录制 Claude Code 流量、拿来训练竞争模型的人,会把这些假工具一并学进去——相当于在数据投毒。另有辅助机制:把推理链替换成带加密签名的摘要,外部观测者看到的不是完整推理过程,而是一个无法逆向的签名。
对篡改客户端,防伪造请求。 HTTP 请求头里有一个占位符 cch=00000,在请求发出前被 Bun 底层的 Zig 代码替换成一个计算出来的哈希值。服务端验证这个哈希,确认请求来自未被篡改的官方二进制文件。这套机制在 JavaScript/TypeScript 层以下运行,无法通过修改前端代码绕过。即使设置了 DISABLE_TELEMETRY=1,这个认证 token 依然会随每个 API 请求发出——遥测可以关,但身份认证关不掉。
三件套的共同逻辑:对外不露身份,对对手不露推理,对非官方客户端不提供服务。
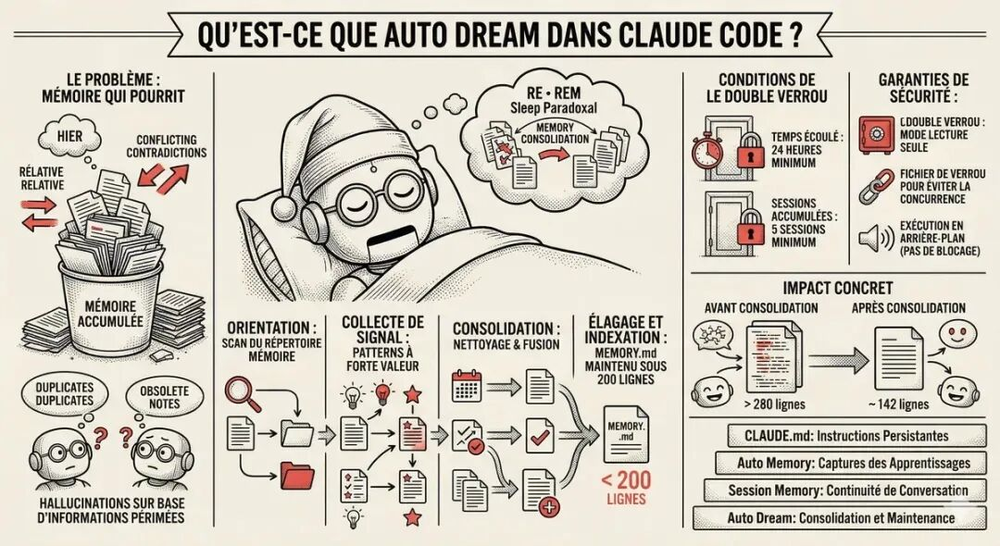
Auto-Dream:代码里的 REM 睡眠
基础设施层里有一个后台进程叫 Auto-Dream,专门处理记忆整合。每隔 24 小时,或者完成 5 次会话之后,系统会 fork 一个子代理,审阅历史记录:合并相关内容、删除矛盾信息、把模糊表述固化成确定知识。
代码里这个进程的系统提示写得很文学:
“You are dreaming. Reflect on your memories, synthesize durable knowledge, and clean up noise.”
 Auto-Dream 机制图解
Auto-Dream 机制图解
Auto-Dream 的设计非常工程化。它有三重门控(时间间隔、会话计数、文件级 advisory lock),并且用最便宜的检查先做筛选——先看距上次整理是否超过 24 小时,再看会话数是否达到 5 次,最后才尝试获取锁。锁文件本身也设计得精巧:mtime 就是 lastConsolidatedAt,文件体是持有者的 PID,但即使 PID 还活着,超过一定时间也会被视为过期——防止 PID 重用导致的死锁。
整理前后的效果很直观:整理前 MEMORY.md 可能超过 280 行,充斥重复和矛盾;整理后被压缩到约 142 行,条理清晰。这本质上是 Agent 记忆的垃圾回收——而且发生在用户空闲时,不占用工作 token。
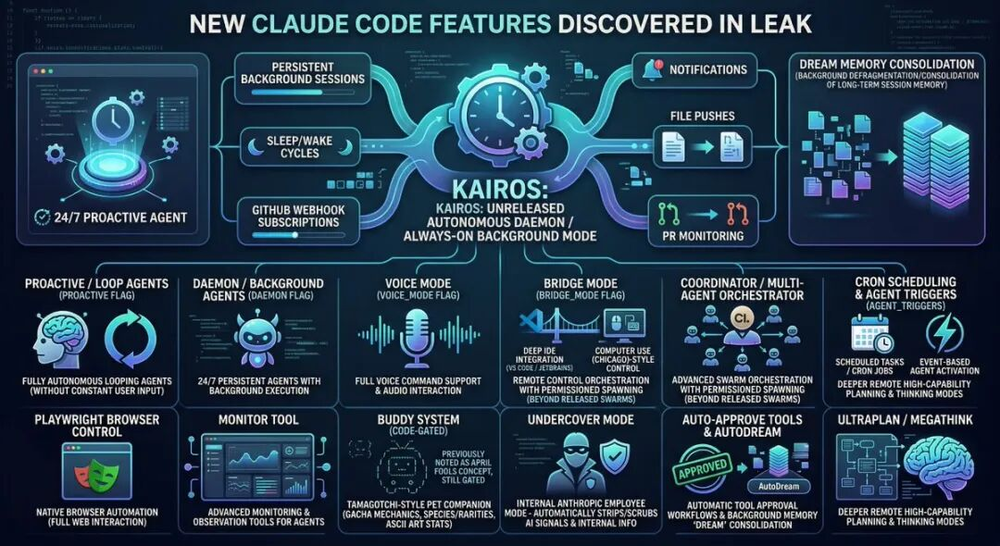
KAIROS:还没发布的永不睡觉模式
Feature flag 关着,但逻辑已写完。
KAIROS(古希腊语 kairos,意为”在正确的时间行动”)是一个持续后台运行的代理模式:每隔几秒检查一次是否有值得主动做的事,订阅 GitHub webhook,支持 cron 定时刷新,24 小时不间断运行。不需要你开口,它自己判断什么时候该动。
 KAIROS 及其他泄露的未发布功能
KAIROS 及其他泄露的未发布功能
现有的 AI 编程工具都是”你叫我才动”的模式——会话开始、任务执行、会话结束。KAIROS 如果上线,这个边界就消失了:AI 不再是一个被动工具,而是一个在后台持续工作的合作者。比如一旦有新的 GitHub issue 或报错事件推送过来,它在后台就开始修了——不等你上班。
这是本次泄露里最重要的产品路线图信号。
代码里的情绪检测
当用户在对话里说出 wtf、damn it、useless 这类词时,系统会识别出用户处于挫败状态。识别方法是正则表达式,不是 LLM 推理。原因很直接:更快,也更省钱。
代码底层的遥测系统显示,Anthropic 非常在意开发者的”挫败感”——系统会专门追踪用户是否在终端里对 Claude 爆粗口,以及连续输入 continue(通常因为模型输出中断导致的烦躁行为)的频率。这些信号被捕捉后可能用于体验优化或产品反馈分析。
这完美体现了 Claude Code 的一个核心工程原则:不是所有决策都需要最强模型。 权限预检交给最便宜的 Haiku;情绪检测用正则;MicroCompact 零 API 调用。主模型只负责它真正擅长的推理与生成,其他一切——安全检查、分类、压缩、格式化——都交给最便宜且可靠的方案。这种分层路由的思路,才是真正大规模跑起来之后的成本智慧。
写在最后
回到最初的问题——Claude Code 的引擎盖下究竟是什么样子?答案出乎意料地朴素:一个 20 行的 while 循环,外面包着 512,000 行的 harness。 五层架构——入口、运行、引擎、工具、基础设施——本质上都在服务同一件事:让那个极简的循环在真实世界里跑得安全、便宜、可控。动态提示词组装、三层上下文压缩、共享 KV cache 的多代理、六层权限防线、怀疑论记忆、Auto-Dream 的垃圾回收,每一个看似炫技的设计,落到根上都是工程约束下的务实取舍。
真正的启示不在于那些猎奇细节,而在于一个反直觉的结论:构建强大 Agent 的关键,不是更复杂的控制流,而是把循环做薄、把循环周围的一切做厚。模型能力决定上限,harness 工程决定你能不能稳定地把那个上限交付到用户手里。这,才是这 512,000 行代码留给所有 Agent 构建者最值钱的一课。
最后再提醒一次:以上解读建立在泄露代码与社区分析之上,机制是否启用、数字是否精确,都应以 Anthropic 官方为准。读它,是为了理解一套工程思路,而不是把每个细节当作定论。