推荐系统(Recommender System, RS)本质上解决的是一个信息过载问题:当候选物品从几千膨胀到几百万甚至上亿时,用户既没耐心也没能力逐一浏览。搜索需要用户明确知道自己想要什么,而推荐的价值在于帮用户发现那些符合兴趣、但尚未意识到的物品。
过去十年,推荐系统已经从一套简单的协同过滤算法,演进为一个涵盖数据工程、召回策略、排序模型、在线服务和实验平台的完整工业系统。本文以 DevelopersVoice 的架构综述和 System Design Handbook 的工程指南为主线,融合工业界实践,尝试把工程架构与核心算法结合起来,重新梳理推荐系统的全貌。
推荐系统不是单一算法,而是一套流水线
在现代工业实践中,一个完整的推荐系统通常被拆分为四个核心阶段。Netflix、YouTube、Amazon 这些头部平台的推荐架构,无一例外地遵循着同一个多级漏斗(multi-stage funnel)模式:

| 阶段 | 输入 | 输出 | 核心任务 |
|---|---|---|---|
| 数据处理与嵌入 | 用户画像、物品属性、行为日志 | 特征向量、索引 | 特征工程、Embedding 生成、索引构建 |
| 多路召回 | 全量物料库(百万~亿级) | 千级候选集 | 从海量物品中快速筛选用户可能感兴趣的候选 |
| 精准排序 | 召回候选集 + 精细特征 | 百级有序列表 | 用复杂模型预测 CTR/CVR,按分数排序 |
| 重排与过滤 | 排序结果 | 最终展示列表 | 去重、多样性打散、业务规则插入、疲劳度控制 |
这个分层的逻辑非常明确:召回负责”不错过”,排序负责”不排错”,重排负责”看得舒服”。如果跳过召回直接对全库排序,计算成本高到不可接受——对一亿物品逐一跑复杂排序模型,P99 延迟会从毫秒级飙升到分钟级。如果只有召回没有精排,推荐结果的精准度又无法满足用户体验。漏斗的每一级都在用更精细的模型处理更少的候选。
召回层:协同过滤的核心思想
召回层是推荐系统的”海选”阶段。它面对的是百万甚至亿级的全量物料库,需要在毫秒内把候选集缩减到几百到几千的量级。协同过滤(Collaborative Filtering, CF)是这里最经典的一类方法,它的核心假设是:用户对物品的喜好不是孤立的,而是有规律可循的——过去的交互行为能够预测未来的偏好。
用户-物品评分矩阵
协同过滤的原始数据通常被组织成一个用户-物品评分矩阵。行代表用户,列代表物品,矩阵中的每个单元格是用户对物品的评分(显式反馈,如 1~5 星)或交互信号(隐式反馈,如点击、购买、播放时长)。
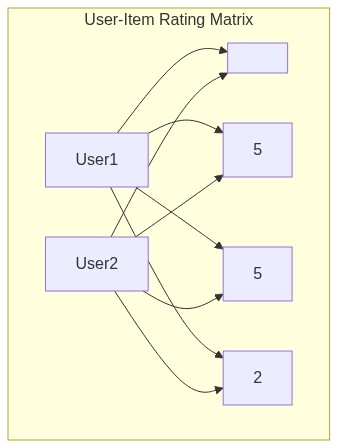
这个矩阵通常是极度稀疏的——没有任何用户会与所有物品产生交互。Netflix Prize 数据集中,评分矩阵的填充率仅约 1.2%。协同过滤的目标,就是利用已有的评分去预测那些空白单元格的值,从而把预测分数高的物品推荐给用户。
UserCF vs ItemCF
根据”找相似”的对象不同,协同过滤分为两条路径:
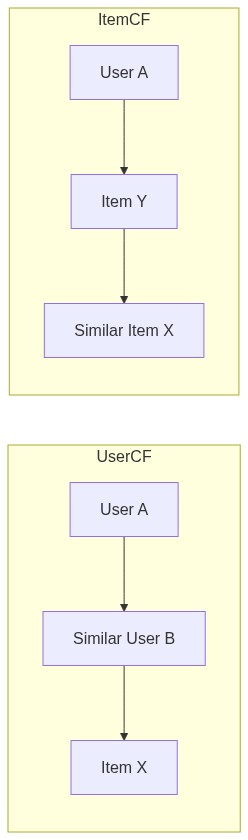
基于用户的协同过滤(UserCF) 的思路是”人以群分”:先找到与目标用户兴趣相似的其他用户(邻居),然后把邻居喜欢但目标用户还没接触过的物品推荐给他。直觉是”和你品味相似的人喜欢的书,你也可能喜欢”。
基于物品的协同过滤(ItemCF) 的思路是”物以类聚”:先计算物品之间的相似度(经常被同一批用户喜欢的两件物品被认为是相似的),当用户喜欢了物品 A,就把与 A 最相似的物品 B、C、D 推荐给他。直觉是”看了又看”、”买了也买”。
在工业实践中,ItemCF 往往更受欢迎。原因很实际:物品数量通常远小于用户数量,计算 Item-Item 相似度更轻量;而且用户的兴趣变化快,但物品间的相似关系相对稳定,缓存更友好。Amazon 早期的推荐系统就是以 ItemCF 为主力召回通道。
相似度度量
无论是 UserCF 还是 ItemCF,都需要一个度量相似性的函数。常见的选择:
- 余弦相似度(Cosine Similarity):把两位用户对共同物品的评分看作两个 n 维向量,计算夹角余弦值。取值 [-1, 1],最通用也最常用
- 皮尔逊相关系数(Pearson Correlation):在余弦相似度基础上先减去各自的均值,消除不同用户评分尺度差异(有人习惯给高分,有人习惯给低分)。在显式评分数据上通常优于余弦
- 杰卡德相似系数(Jaccard Similarity):计算两个集合的交集 / 并集。只关心”有没有交互”不关心评分高低,非常适合隐式反馈(点击流、浏览记录)
从协同过滤到矩阵分解
协同过滤的一个明显瓶颈是可扩展性:当用户和物品数量达到千万甚至亿级时,直接计算全量相似度矩阵非常昂贵,稀疏矩阵中大量空白单元格也会干扰相似度估计。
矩阵分解(Matrix Factorization, MF)提供了一个更优雅的解法:把庞大的用户-物品评分矩阵,分解为两个低维稠密矩阵的乘积。
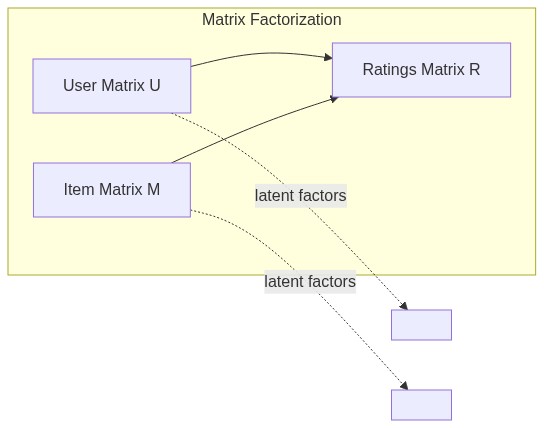
假设原始评分矩阵为 R(m 个用户 × n 个物品),我们希望找到:
- 一个用户隐因子矩阵 U(m × k)
- 一个物品隐因子矩阵 M(k × n)
使得 U × M ≈ R。这里的 k 远小于 m 和 n(通常 50~200)。
这些”隐因子”(Latent Factors)没有显式的物理意义,但它们捕捉了用户兴趣和物品属性的抽象特征。比如在电影推荐中,某个隐因子可能同时对应”科幻 + 宏大叙事”,那么喜欢《星际穿越》的用户在这个因子上的得分很高,《2001太空漫游》在这个因子上的得分也很高。通过两个向量的点积,就能预测用户对任意物品的评分。
工业界常用的矩阵分解算法:
- SVD(奇异值分解):通过数学方法直接分解矩阵,适用于稠密或填充后的数据
- ALS(交替最小二乘法):固定一个矩阵优化另一个,交替迭代至收敛。Spark MLlib 中的推荐算法就是基于 ALS 实现的,天然支持分布式
- 隐语义模型(LFM):专门处理隐式反馈数据,通过引入置信权重区分”没看过”和”不喜欢”
矩阵分解的核心价值在于:它把推荐问题从”在高维稀疏空间中寻找邻居”转化为”在低维稠密空间中的向量点积”,计算效率大幅提升,也更容易与向量检索系统(FAISS、Milvus、ScaNN)结合部署。
双塔模型:深度学习时代的召回
当矩阵分解遇到需要融合大量异构特征(文本、图像、上下文)的场景时,表达能力就不够了。双塔模型(Two-Tower Model) 是目前工业界候选生成阶段的主流架构。
双塔模型的思路很直接:用两个独立的深度神经网络分别编码用户特征和物品特征,各自输出一个稠密 Embedding 向量,然后通过向量内积或余弦距离度量匹配程度。训练完成后,所有物品的 Embedding 预先计算好并建立 ANN(Approximate Nearest Neighbor)索引,线上请求时只需要实时编码用户向量,再用 FAISS 或 ScaNN 做亚毫秒级的近邻检索——就能从几百万物品中检索出 Top-K 候选。
双塔架构之所以能成为工业标准,关键在于它解耦了用户侧和物品侧的计算:物品塔可以离线批量预计算,用户塔在线实时推理,两者独立扩展。这让系统在保持表达能力的同时满足了毫秒级延迟的硬约束。
排序层:从 LR 到深度学习
召回层从海量物品中筛选出几百到几千的候选集,排序层要做的是给这些候选精确打分,按分数从高到低排列。
排序问题可以被形式化为一个函数 F(user, item, context) → score,其中 score 通常是点击率(CTR)、转化率(CVR)或综合收益的预期值。这是推荐系统里模型最”重”的环节:特征最多、模型最复杂、延迟预算最紧。
从线性模型到深度模型
排序模型的演进经历了几个清晰的阶段:
逻辑回归(LR):最基础的排序模型。将用户画像、物品特征和上下文特征拼接成一个高维稀疏向量,输入广义线性模型,输出 0~1 之间的概率。LR 的优点是可解释性强、训练和预测都快;缺点是难以自动捕捉特征之间的交叉关系——需要人工做大量的特征工程。
GBDT + LR:用梯度提升树(GBDT)自动挖掘有效的特征组合,再把树输出的叶子节点作为新特征输入 LR。Facebook 在 2014 年发表的论文让这个方案成为了工业界的主流范式。
Wide & Deep:Google 在 2016 年提出的架构,用一个”宽”的线性部分做记忆(memorization),一个”深”的神经网络做泛化(generalization),两条路径联合训练。这个思路影响了后续大量工业排序模型的设计。
DeepFM:把 Wide & Deep 中的宽部分替换成 FM(Factorization Machine),不再需要手工设计特征交叉,同时学习低阶和高阶特征交互。
DIN(Deep Interest Network):阿里在 2018 年提出的模型,引入注意力机制,根据候选物品动态加权用户历史行为序列。核心洞察是:用户的兴趣不是一成不变的,同一个用户对不同候选物品的”相关历史”是不同的。
粗排与精排
在工程上,排序通常被进一步拆分为两级:
- 粗排(L1 Ranking):用轻量模型(小型神经网络或 GBDT)对几千候选做快速筛选,缩减到几百。可以使用召回阶段无法引入的交叉特征,但模型复杂度有限
- 精排(L2 Ranking):用最复杂的模型(Cross-Encoder、Deep & Cross Network)对几百候选做精确打分。这一层允许联合考察 user-item pair 的所有特征,精度最高但计算成本也最高
两级排序的意义在于:用粗排快速淘汰明显不相关的候选,把精排的算力预算集中在最有价值的几百个候选上。
重排与业务护栏
排序模型输出的有序列表,并不能直接呈现给用户。重排层(Re-ranking)负责加入商业逻辑和用户体验约束:
- 多样性约束:防止连续展示同一类目或同一品牌的内容——用户不想看到首页全是运动鞋
- 新鲜度加权:给新内容一定的流量倾斜,避免推荐结果被老物品垄断
- 疲劳度控制:同一物品在短时间内重复曝光会被降权
- 库存与利润因素:电商场景中,缺货商品需要被过滤,高毛利商品可能获得适度加权
- 内容合规过滤:低质、违规、地域受限内容的拦截
重排层的代码量通常不大,但业务影响却很直接——它是推荐系统与商业目标之间的最后一道接口。
工程架构中的关键问题
把算法跑通只是第一步。真正上线一个推荐系统,需要解决一系列硬核的工程问题。
离线与在线的分治
生产级推荐系统普遍采用”离线预计算 + 在线实时补全”的混合架构:
离线路径负责重计算:通过 Apache Kafka / Kinesis 做数据摄取,Spark / Flink 做特征计算,定时(小时级 / 天级)训练模型并生成 Embedding 和排序权重。所有物品的向量索引、用户画像快照、热门榜单都在这个路径中产出。
在线路径负责低延迟:接收用户请求后,从缓存和特征存储中拉取预计算结果,经过多级排序漏斗,在 200 毫秒内返回最终推荐列表。用户最近几分钟的点击、收藏等行为,通过实时流处理快速更新到在线特征中。排序模型以 TFServing / TorchServe 等模型服务框架部署,P99 延迟通常要求在几十毫秒以内。
这种离线-在线分治的根本原因是:复杂模型的训练和批量推理不可能在用户请求的毫秒级延迟窗口内完成。 分治让系统在保持模型复杂度的同时满足延迟 SLA。
缓存策略
| 缓存类型 | 内容 | TTL | 目标命中率 |
|---|---|---|---|
| 用户推荐列表 | 预计算的 Top-N | 1~24 小时 | 60~80% |
| 物品 Embedding | 稠密向量 | 24~72 小时 | 90%+ |
| 用户特征 | 画像 / 偏好数据 | 1~6 小时 | 70~85% |
| 会话特征 | 实时活动信号 | 5~30 分钟 | 40~60% |
缓存在推荐系统里的角色不只是加速——它还是降级策略。当排序服务过载或宕机时,预计算的缓存列表就是兜底方案。
冷启动
冷启动分为三种:新用户冷启动(没有历史行为)、新物品冷启动(没有交互记录)、新系统冷启动(平台初期数据稀疏)。
常见的应对策略:
- 新用户:利用人口统计属性、设备类型、注册来源做基于内容的推荐;用热门榜单或编辑精选作为兜底
- 新物品:基于元数据(类目、品牌、文本描述)生成 Embedding,用内容特征代替协同信号;给予一定的探索流量扶持
- 新系统:结合多模态内容理解(标签、文本、图像),在行为数据不足时直接用内容特征做匹配;通过 Thompson Sampling 或 ε-Greedy 等探索策略平衡开发和探索
多路召回融合
工业系统很少只依赖单一召回通道。常见的召回路径包括:
- 协同过滤召回(UserCF / ItemCF / MF)
- 向量 Embedding 召回(双塔模型、Graph Embedding)
- 热门 / 地域 / 新品策略召回
- 用户历史行为触发召回
多路召回的结果需要融合后交给排序层。融合策略可以是简单的加权去重,也可以是用一个轻量模型做召回间的二次筛选。关键设计原则是:每条召回通道独立失败不影响整体,且新增一路召回的边际成本要低。
AB 测试与指标体系
推荐系统的优化是持续迭代的过程,AB 测试是评估新算法效果的必备手段。采用 Champion-Challenger 架构配合一致性哈希分桶,避免用户级别的实验污染。
核心指标分三个维度:
技术指标:延迟分位数(P50 / P95 / P99)、缓存命中率、吞吐量、错误率
模型质量指标:
- Precision@K / Recall@K:推荐列表中相关物品的比例 / 覆盖率
- NDCG(Normalized Discounted Cumulative Gain):衡量排序质量,位置越靠前的相关结果贡献越大
- 覆盖率(Coverage):有多少长尾物品被推荐出去
业务指标:
- 点击率(CTR)、转化率(CVR)
- 人均曝光时长 / 人均点击次数(用户粘性)
- 每次推荐带来的收入(Revenue per Recommendation)
- 多样性(Diversity)与新颖性(Novelty)
正在发生的变化
推荐系统正在经历几个结构性的转变。
生成式推荐(Generative Recommendation)
传统推荐是判别式的——从已有物品池中筛选和排序。生成式推荐则把推荐形式化为一个序列生成任务:给定用户的历史交互序列,用 Transformer 架构直接生成下一个应该推荐的物品 token。
Meta 的 HSTU(Hierarchical Sequential Transduction Units)和快手的 LEARN 是这个方向的早期工业实践。更激进的方案如 MTGR(Multi-Task Generative Recommender)试图用一个万亿参数的序列 Transducer 取代整个多级漏斗——召回、排序、重排统一在一个生成模型里完成。
这条路还在早期,但方向已经明确:从多级漏斗走向端到端生成。
LLM 与推荐的融合
大语言模型正从三个维度渗入推荐系统:
- 内容理解:用 BERT 类模型对物品标题、描述、评论做语义编码,融入排序特征。ByteDance 的 HLLM 和 Alibaba 的 LUM 都在这个方向上
- 对话式推荐:LLM 直接理解用户的自然语言偏好表达,维护对话状态,在交互中动态细化推荐——用户不再只能点击,而是可以说”我想看类似《星际穿越》但更轻松一点的”
- 多模态融合:图像、文本、音频的联合编码,在行为信号不足时用内容语义补位。研究显示多模态方案在推荐准确度上比单一模态提升约 38%
公平性与偏见
推荐系统会放大已有数据中的偏见——热门物品越推越热,长尾物品永远沉底。这不仅是算法公平性问题,也是商业问题(长尾物品贡献了大量 GMV)。
应对手段包括:重排阶段的多样性约束、校准(Calibration)以对齐推荐分布与公平目标、以及在损失函数中直接引入公平性正则项。核心张力在于:参与度优化和公平性约束之间需要领域特定的权衡,没有通用的最优解。
写在最后
从 2014 年写下这篇博客的初稿到现在,推荐系统发生了巨大的变化。早期关注的是”欧氏距离和皮尔逊系数哪个更好”,今天工业界更关心的是”如何把十亿级的向量检索做到毫秒级延迟”、”如何用多目标模型同时优化点击和停留时长”、”如何在召回阶段就把内容语义和用户长期兴趣对齐”。
但底层逻辑没有变:推荐系统始终是在信息过载的场景下,通过算法和工程手段,把”用户可能最感兴趣的内容”高效、准确地送到他们面前。 理解召回、排序、重排的分层架构,掌握协同过滤和矩阵分解的核心思想,是进入这个领域的坚实起点。而双塔模型、注意力排序、生成式推荐这些新范式,则定义了这个领域的下一个十年。