感谢婉君的博客,让我自己也很想写篇博文来整理和罗列一下个人对于云计算和海量数据这方面的看法和理解,全部内容仅为个人理解。
另外感谢撤退学长的博客,分享了很多有价值的内容。
—
大清早拉肚子不睡觉真大丈夫?
—
- 所谓云计算什么的,其实就是自己这里搞不好的事情丢给牛逼的学长们去完成
云计算(Cloud Computing),是一种基于互联网的计算方式,通过这种方式,共享的软硬件资源和信息可以按需求提供给计算机和其他设备。优点是自助、共享、灵活、易监测度量。主要的服务模式有软件即服务(SaaS)、平台即服务(PaaS)和基础架构即服务(IaaS)
宏观上讲,从单一的某台机器的虚拟化到实现云计算,是一个对物理资源逐步封装的过程,同时,将虚拟化资源低阶的使用权限和特定虚拟机生命周期的管理权限留给云服务的使用者,把对集成资源高阶的管理和配置配置资源留给云服务的提供者。简言之,在使用云计算服务的过程中,给用户带来的最大的体验改进就在于其不需要知道参与计算的物理设备的具体情况与其实现方法,只需要关注于自己需要这些云资源去完成的计算任务即可。
本科时候有个室友听说我当时在搞云计算方向,他的态度是这玩意儿太概念,太空洞,至少在那个时候还缺少一些支柱型的科学体系和实验支持。我不是很同意他的观点,但是也很难否定他。现在业界对于云计算的定义我个人觉得都显得比较复杂和纠结,往往会有种玩票的即视感,事实上自从2006年8月9日,Google首席执行官埃里克·施密特在搜索引擎大会(SES San Jose 2006)首次提出“云计算”的概念以来,云计算一直缺乏一种能让每个从业者和团队都认可的定义,原因也很简单,因为大家都将其套用到自己实际的应用和开发模式当中。举个不是很恰当的例子,比如有人在大学上课接受教育,有人在幼儿园学唱歌画画接受教育,还有人在新东方学挖掘机或者厨师接受教育,当这三个人聚在一起的时候,都觉得别人的教育方式和自己的不太一样,然后开始怀疑到底是自己的教育方式不对还是别人的不对。其实关于云计算最提纲挈领的理解可以总结为一句话:通过网络以自助服务的方式获得所需要的IT资源的模式。
其中有三个关键点:获取路径:通过网络;获取方式:自助服务;获取对象:IT资源。
另外,NIST还定义了三种服务模式(SaaS\PaaS\IaaS)和四种实施模式(公有云、私有云、社区云和混合云)。
总而言之,我其实不是很认可把云计算归为一门独立的计算机技术,因为其技术架构其实是集成了一系列现有的技术理念和实现方法,我更认可把它归类为计算机科学和网络技术发展过程中,一个较为高层次的集成化商业模式,是在通讯和信息技术不断发展的未来中,面临个人终端计算能力瓶颈所采取的必然的解决方案。单纯从技术架构上讲,整个云计算模式可以被视作这样三横一竖的结构:
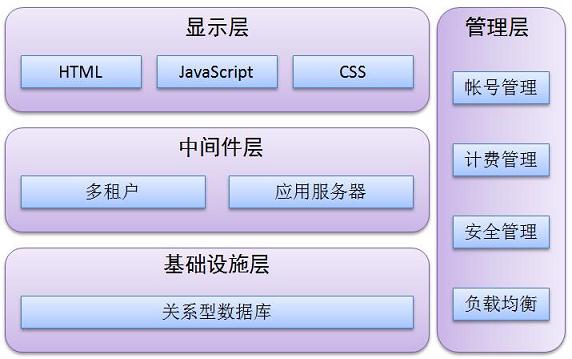
当然,我个人对这个分层方法也持保留态度,比如在显示层中,不仅仅只有web浏览器这一种反馈方式,因为对于云计算来说,广义上的B/S和C/S模式都有,所以仅有web-browser显示方式是远不够的。在现在的学术研究中,三层的重视程度是由上往下递增的,可以说对于云计算来讲,绝大多数的科研经历还是放在最底层的基础设施层,而且系统虚拟化,NoSQL以及分布式计算(含处理和存储)都会是云计算未来发展的主攻方向。
关于虚拟化和云计算的关系,包括其间还有一层的虚拟机监视器(VMM)之间的关系,推荐去看婉君的博客,写的思路非常清楚,结构很整洁,我之后有空了想详细罗列一下做个阅读笔记。
关于NoSQL,推荐NoSQL精粹一书,寒假时候刚刚看完,入门不错,把NoSQL里几个主要概念都罗列的很清楚,以后有空也会详细做个阅读笔记。
最后是分布式计算和云计算的关系,这两者之前其实很微妙,很多道行不深的同学往往会把二者混为一谈,或者简单认为OpenStack那样的就是云计算,Hadoop那样的分布式计算,其实不然。对于分布式计算来说,最完整也最学术的概述应该是这样的:
分布式计算是一门计算机科学,主要研究分布式系统。一个分布式系统包括若干通过网络互联的计算机。这些计算机互相配合以完成一个共同的目标(我们将这个共同的目标称为“项目”)。具体的过程是:将需要进行大量计算的项目数据分割成小块,由多台计算机分别计算,再上传运算结果后统一合并得出数据结论。在分布式系统上运行的计算机程序称为分布式计算程序;分布式编程就是编写上述程序的过程。
简言之就是一卡车可乐我一个人搬不动,即使搬得动我也要花很久时间才能够把它们全搬完,于是我找了很多力气跟我差不多的小伙伴,每人搬一两箱,于是很快就搬完了。登登登登~这种做法很像我们算法中的分治法,将大问题化成若干个相似或者相同的子问题,还可以然后递归分化,直到分到的子问题足够小能够直接解决,最后把各个子问题的结果汇总合并,得到大问题的计算结果。也有人认为分布式运算是一种特殊形式的并行计算方法,简单说来,如果处理单元共享内存,就称为并行计算,反之就是分布式计算。
所以云计算和分布式计算二者的区别还是比较明显的,北航的钱德沛教授有过比较,在此我总结一下:
- 虚拟化:分布式计算主旨是聚合分布资源,支持虚拟组织,提供高层次的服务。而云计算的资源相对集中,主要以数据中心的形式,通过网络提供底层资源的使用,并不强调虚拟组织(VO)的概念。
- 资源使用的初衷:分布式计算是针对单点高性能资源不够用所以要继承多处资源,任何节点既可以使用别的节点的资源,也必须贡献出自己资源;而云计算更具有普适性,对资源数量和质量要求更低,可以有自己的专属资源,更不要求贡献自己本机的资源。
- 异构性:在对待异构性方面,二者理念上有所不同。分布式计算用中间件屏蔽异构系统,力图使用户面向同样的环境,把困难留在中间件,让中间件完成任务。而云计算实际上承认异构,用镜像执行,或者提供服务的机制来解决异构性的问题。当然不同的云计算系统还不太一样,像Google一般用比较专用的自己的内部的平台来支持。
- 任务形式:分布式计算用执行作业形式使用,在一个阶段内完成作用产生数据。而云计算支持持久服务,用户可以利用云计算作为其部分IT基础设施,实现业务的托管和外包。
- 用途:分布式计算更偏向于科研方向,云计算一开始出来就是明确的企业用途,而且商业模型清晰。
- 所谓大数据什么的,不是说你把几GB或者几TB或者几PB的数据往那一丢随便做点处理就可以了的!
首先我想说的是,之所以把大数据和云计算这两个词放在一起说,不仅因为这两个词在当今不管你是不是搞计算机科学的听到都会觉得挺热门,更重要的一点是,这两个词经常被误用和曲解。云计算的误用多存在于将一些传统的B/S、C/S服务或者一些简单的Internet服务都被称为是云计算,但大数据的误用可着实是多了去了。对大数据的误读主要有以下几种情况:一种是数据不够大,比如我见过某地政府自称使用大数据技术分析了某几个月群众关于其工作的电邮反馈,得出了人民群众最关心的政府热点是神马云云,然后我发现他们一个月连email带短信,撑死不会超过一万条反馈记录,虽然到底多大的数据量才能够得上“大数据”还没有非常明确的界定,但这么点数据压力显然不够,至于微博上其他一些打着“大数据”旗号搞得常规化“样本统计”就更多了,如果一定要从规模上做界定的话,截止2012年,单一数据集至少在TB以上才能够得上所谓的“大数据”。第二种是数据集足够大,但没有后续了,这也是比较尴尬的一点,因为所谓的“大数据”技术其实是一种非常宽泛的称呼,其中不仅包括对于大量数据的存储,更包括了对这样大量数据的前期收集,中期过滤、分析、管理、操作,以及短期或长期的储存。甚至可以说,到目前为止,储存和一些相对基础的计算早已不是大数据发展的瓶颈了。早期的各类OLAP工具已经足够给力了,后来类似海杜普这样的东西彻底降低了分布式数据的架构成本和门槛,就彻底将大数据带入了一个普及的领域。现在真正的瓶颈实际上是在于前端的数据收集过程和之后的商业模型建立以及后续使用方法。所以我们常说,数据本身是没有任何价值的,价值是通过对数据的合理使用得到的。跟传统的数据分析、数理统计相比,大数据处理往往没有特定的方向和标准,需要数据不断建立新的模型,再不断调整处理算法,而传统的统计往往会有具体的方向,甚至会得出一个特定的、真实的结论。举个例子,数字是我瞎编的,淘宝网上一年卖出了很多很多bra(数据量够大了吧!),然后我们算出来平均每个女性淘宝用户一年要买5个bra,小伙伴们撕的真勤快,其中,又数东北爷们撕的最勤快,一年撕4.5个,西藏朋友比较厚道,一年撕2.5个,然后浙江姑娘喜欢在夏天买bra,而冬天绝大多数的bra都被广东和海南两地的姑娘买走了等等……这些都是属于传统的数理统计就可以解决的问题,包括对之后的一些预测或者分类,如我们知道有个姑娘size是C,喜欢在年初买好一整年的bra,平均每年是4.1个,那么我们也能通过传统数理统计和模式识别来进行预测这个姑娘可能是哪个地方的。所以传统数理统计都基于这种粗颗粒度的特征,又可以用传统的计算方法和模型较为直接得得到结论。但如果是要去探讨一个在工作压力下会选择男性化生活方式的姑娘是否会因为某品牌的电视广告来改变她的bra购买习惯,或者要去探讨一个是由于传统伦理作用而对同性恋持反对态度的姑娘是否会在某一段恋爱结束后突然对bra的购买能力增强,这就可以勉强视作一种大数据计算和处理的思想。所以说大数据的计算方法,更着重于一些细颗粒度的特征值(无法直接从数据中观察得到,属于数据间相对深层次的潜在联系,更多的是指在某一信息或者条件作用下主体的反应等),同时具有较高的直接或间接的使用价值,比如让淘宝多为工作压力大上班族女性用户推荐某特定品牌bra,或者为情绪波动大的女性用户在某一个流行韩剧结束后推荐同款bra等能更好地引诱其购买。
从理论上来讲,最早定义大数据这个概念的IBM将大数据的特征归纳为4个“V”(量Volume,多样Variety,价值Value,速Velocity),或者说特点有四个层面:第一,数据体量巨大,当时认为至少要PB起步;第二,数据类型繁多,比如,网络日志、视频、图片、地理位置信息等等。第三,价值密度低,商业价值高。第四,处理速度快。入门性读物大数据时代提到大数据带来的三大数据处理的改变:“不要随机样本,而是全体数据”、“不是精确性,而是混杂性”、“不是因果关系,而是相关关系”,但是我个人对其持保留意见,因为大数据并非简单的用普查代替抽样,否定精确性又只关注相关关系。
最后,从大数据的价值链条来分析,存在三种模式:
1. 手握大数据,但是没有利用好;比较典型的是金融机构,电信行业,政府机构等。
2. 没有数据,但是知道如何帮助有数据的人利用它;比较典型的是IT咨询和服务企业,比如,埃森哲,IBM,Oracle等。
3. 既有数据,又有大数据思维;比较典型的是Google,Amazon,Mastercard等。
先就写到这里,断断续续写了两天,之后有想到什么新的再往上加吧。
贴几个国内关于大数据和云计算的资讯