终于要写Hadoop了,如果说云计算就像teenage sex,大家都在讨论但是很少有人真的接触到,那么Hadoop就像是印度神油,据说效果很好,但是买过的人也不知道自己抹没抹对地方。
概况
其实Hadoop并不是什么技术,只是一个框架,一个工具,而且是一个入门门槛不高的工具,会用Linux,会点虚拟化,再会一点Java就行。应该说,Hadoop是一个能够对大量数据进行分布式处理的软件框架,它是一种技术的实现,是云计算技术中重要的组成部分,现在用Hadoop或者想用Hadoop的公司很多,包括之后的Spark框架,所以我个人觉得,Hadoop还会是之后大数据处理的主流方式。
我们现在常说的Hadoop其实是由四个小伙伴组成的,分别是文件系统HDFS,计算框架Hadoop/MapReduce,Hive和Hbase,下面简单介绍一下。
HDFS
HDFS是一个主/从(Master/Slave)体系结构,从最终用户的角度来看,它就像传统的文件系统一样,可以通过目录路径对文件执行CRUD(Create、Read、Update和Delete)操作。但由于分布式存储的性质,HDFS集群拥有一个NameNode和一些DataNode。NameNode管理文件系统的元数据,DataNode存储实际的数据。客户端通过与NameNode和DataNode的交互访问文件系统。客户端联系NameNode以获取文件的元数据,而真正的文件I/O操作是直接和DataNode进行交互的。 下图为HDFS总体结构示意图
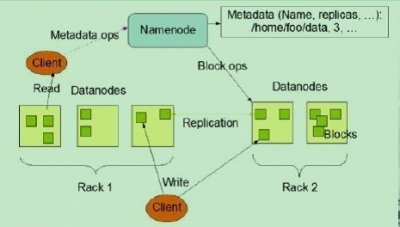
HDFS用流式数据访问模式来存储超大文件,运用于商业集群上,其构建思路是一次写入,多次读取。其中数据块block是HDFS读写的最小单元,默认128MB(早期为64MB)。HDFS有两大节点,并以管理者-工作者模式运行,即一个namenode(管理者)和多个datanode(工作者)。前者管理文件系统的命名空间,维护着整个文件树和树内所有文件和目录,这些信息以命名空间镜像文件和编辑日志文件形式永久保存,没有namenode整个HDFS将难以运行,所以对namenode的容错能力要很强,一般采用的方法是备份namenode到本地文件或者设置一个辅助namenode(注意:SecondaryNameNode不是热备,仅负责定期合并fsimage与edits;生产常用HA NameNode + JournalNodes)。因此,HDFS有以下四个特征:
- 存储极大数目的信息(TB~PB),将数据保存到大量的节点当中。支持很大单个文件。
- 提供数据的高可靠性,单个或者多个节点不工作,对系统不会造成任何影响,数据仍然可用(典型副本因子为3,机架感知副本布局)。
- 提供对这些信息的快速访问,并提供可扩展的方式。能够通过简单加入更多服务器的方式就能够服务更多的客户端。
- HDFS是针对MapReduce设计的,使得数据尽可能根据其本地局部性进行访问与计算。
1, NameNode
NameNode可以看作是分布式文件系统中的管理者,主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等。NameNode会将文件系统的Meta-data存储在内存中,这些信息主要包括了文件信息、每一个文件对应的文件块的信息和每一个文件块在DataNode的信息等。
- 管理HDFS的名称空间
- 管理数据块映射信息
- 配置副本策略
- 处理客户端读写请求
2, Secondary namenode
并非NameNode的热备;辅助NameNode,分担其工作量;定期合并fsimage和fsedits,推送给NameNode;在紧急情况下,可辅助恢复NameNode。
3, DataNode
DataNode是文件存储的基本单元,它将Block存储在本地文件系统中,保存了Block的Meta-data,同时周期性地将所有存在的Block信息发送给NameNode。
- 存储实际的数据块
- 执行数据块读/写
- 周期性发送心跳(heartbeat)与块汇报(block report)
4, Client
文件切分;与NameNode交互,获取文件位置信息;与DataNode交互,读取或者写入数据;管理HDFS;访问HDFS。
5, 文件写入
1) Client向NameNode发起文件写入的请求。 2) NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。 3) Client将文件划分为多个Block,根据DataNode的地址信息,按顺序写入到每一个DataNode块中。
(补充)写入过程采用管道式复制:客户端将数据流分成packet,经pipeline顺序写入副本链(DN1→DN2→DN3);只有当下游副本确认(ack)回到上游后,才视为该packet成功,保证副本一致性与容错。
6, 文件读取
1) Client向NameNode发起文件读取的请求。 2) NameNode返回文件存储的DataNode的信息。 3) Client读取文件信息。
(补充)读取过程中客户端优先选择本地或同机架DataNode以提升吞吐,支持短路读(short-circuit read)与校验和(checksum)校验;发生副本损坏时可自动切换到其他副本。 HDFS典型的部署是在一个专门的机器上运行NameNode,集群中的其他机器各运行一个DataNode;也可以在运行NameNode的机器上同时运行DataNode,或者一台机器上运行多个DataNode。一个集群只有一个NameNode的设计大大简化了系统架构。
MapReduce
解释MapReduce有个经典的例子就是统计过去十年计算机刊物上出现最高的词频。
所谓MapReduce,其实是分为Map函数和Reduce函数两个。map函数和reduce函数是交给用户实现的,这两个函数定义了任务本身。
-
map函数:接受一个键值对(key-value pair),产生一组中间键值对。MapReduce框架会将map函数产生的中间键值对里键相同的值传递给一个reduce函数。
-
reduce函数:接受一个键,以及相关的一组值,将这组值进行合并产生一组规模更小的值(通常只有一个或零个值)。
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
在统计词频的例子里,map函数接受的键是文件名,值是文件的内容,map逐个遍历单词,每遇到一个单词w,就产生一个中间键值对<w, “1”>,这表示单词w咱又找到了一个;MapReduce将键相同(都是单词w)的键值对传给reduce函数,这样reduce函数接受的键就是单词w,值是一串”1”(最基本的实现是这样,但可以优化),个数等于键为w的键值对的个数,然后将这些“1”累加就得到单词w的出现次数。最后这些单词的出现次数会被写到用户定义的位置,存储在底层的分布式存储系统(GFS或HDFS)。
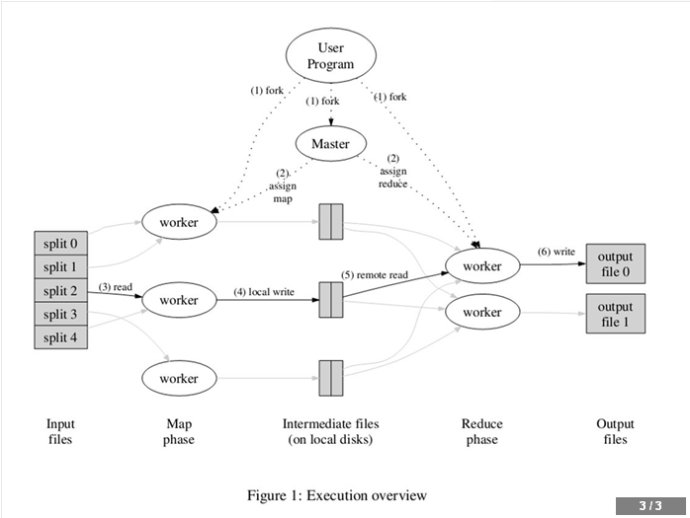
一切都是从最上方的user program开始的,user program链接了MapReduce库,实现了最基本的Map函数和Reduce函数。图中执行的顺序都用数字标记了。
1. MapReduce库先把user program的输入文件划分为M份(M为用户定义),每一份通常有16MB到64MB,如图左方所示分成了split0~4;然后使用fork将用户进程拷贝到集群内其它机器上。
2. user program的副本中有一个称为master,其余称为worker,master是负责调度的,为空闲worker分配作业(Map作业或者Reduce作业),worker的数量也是可以由用户指定的。
3. 被分配了Map作业的worker,开始读取对应分片的输入数据,Map作业数量是由M决定的,和split一一对应;Map作业从输入数据中抽取出键值对,每一个键值对都作为参数传递给map函数,map函数产生的中间键值对被缓存在内存中。
4. 缓存的中间键值对会被定期写入本地磁盘,而且被分为R个区,R的大小是由用户定义的,将来每个区会对应一个Reduce作业;这些中间键值对的位置会被通报给master,master负责将信息转发给Reduce worker。
5. master通知分配了Reduce作业的worker它负责的分区在什么位置(肯定不止一个地方,每个Map作业产生的中间键值对都可能映射到所有R个不同分区),当Reduce worker把所有它负责的中间键值对都读过来后,先对它们进行排序,使得相同键的键值对聚集在一起。因为不同的键可能会映射到同一个分区也就是同一个Reduce作业(谁让分区少呢),所以排序是必须的。
6. reduce worker遍历排序后的中间键值对,对于每个唯一的键,都将键与关联的值传递给reduce函数,reduce函数产生的输出会添加到这个分区的输出文件中。
7. 当所有的Map和Reduce作业都完成了,master唤醒正版的user program,MapReduce函数调用返回user program的代码。
所有执行完毕后,MapReduce输出放在了R个分区的输出文件中(分别对应一个Reduce作业)。用户通常并不需要合并这R个文件,而是将其作为输入交给另一个MapReduce程序处理。整个过程中,输入数据是来自底层分布式文件系统(GFS)的,中间数据是放在本地文件系统的,最终输出数据是写入底层分布式文件系统(GFS)的。而且我们要注意Map/Reduce作业和map/reduce函数的区别:Map作业处理一个输入数据的分片,可能需要调用多次map函数来处理每个输入键值对;Reduce作业处理一个分区的中间键值对,期间要对每个不同的键调用一次reduce函数,Reduce作业最终也对应一个输出文件。
MapReduce的工作机制
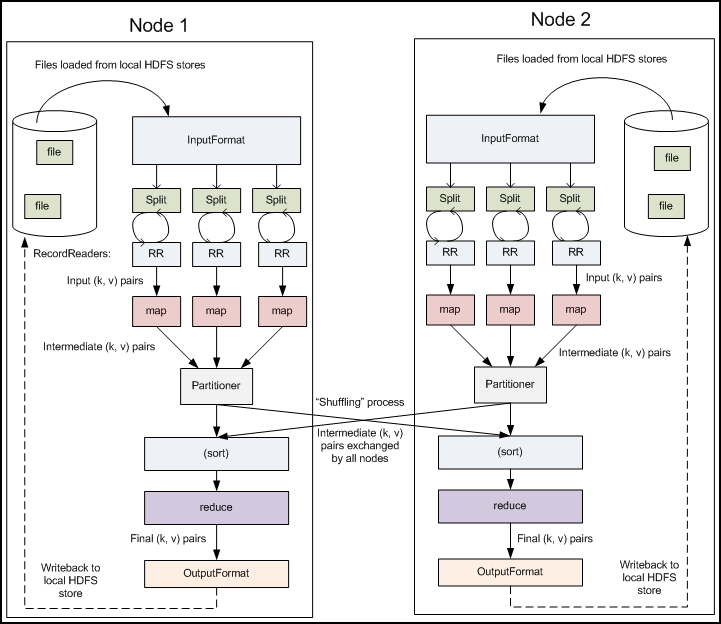
Mapper
Mapper类有四个主要函数,setup,cleanup,map,run,代码如下:
protected void setup(Context context) throws IOException, InterruptedException {
// NOTHING
}
protected void map(KEYIN key, VALUEIN value,
Context context) throws IOException, InterruptedException {
context.write((KEYOUT) key, (VALUEOUT) value);
}
protected void cleanup(Context context) throws IOException, InterruptedException {
// NOTHING
}
public void run(Context context) throws IOException, InterruptedException {
setup(context);
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
cleanup(context);
}
}
当调用到map时,通常会先执行一个setup函数,最后会执行一个cleanup函数。而默认情况下,这两个函数的内容都是nothing。因此,当map方法不符合应用要求时,可以试着通过增加setup和cleanup的内容来满足应用的需求。
Reducer
Reducer是所有用户定制Reducer类的基类,和Mapper类似,它也有setup,reduce,cleanup和run方法,其中setup和cleanup含义和Mapper相同,reduce是真正合并Mapper结果的地方,它的输入是key和这个key对应的所有value的一个迭代器,同时还包括Reducer的上下文。系统中定义了两个非常简单的Reducer,IntSumReducer和LongSumReducer,分别用于对整形/长整型的value求和。Reducer有四个阶段:
-
Shuffle:Reducer把来自Mapper的已排序的输出数据通过网络经Http拷贝到本地来
-
Sort:MapReduce框架按关键字(key)对Reducer输入进行融合和排序(因为不同的Mapper可能会输出同样的key给某个reducer)。shuffle和sort阶段可以同时进行,例如map输出数据在传输时可以同时被融合。
-
Reduce:在reduce这个阶段会为已排序reduce输入中的每个<key, (collection of values)>调用reduce(Object, Iterable, Context)。通常情况下,reduce任务的输出会通过TaskInputOutputContext.write(Object, Object)写入到一个RecordWriter中,reducer的输出是不会重排序的。
其中前两步是Reducer中奇迹发生的地方,发生在Map和Reduce之间,将map端的输出和reduce端的输入对接。
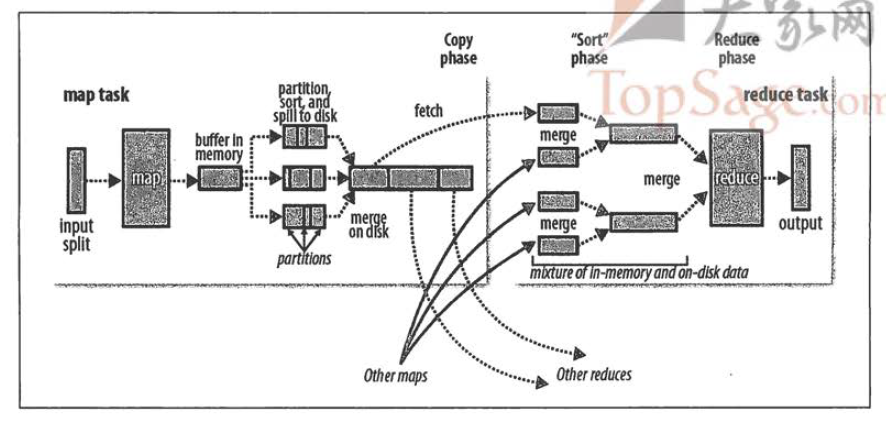
- map 端
map函数开始产生输出时,并不是简单地将它输出到磁盘。这个过程更复杂,利用缓冲的方式写到内存,并出于效率的考虑进行预排序。shuffle原理图就看出来。 每个map任务都有一个环形内存缓冲区,用于存储任务的输出。默认情况是100MB,可以通过io.sort.mb属性调整。一旦缓冲内容达到阀值(io.sort.spill.percent,默认0.80,或者80%),一个后台线程开始把内容写到磁盘中。在写磁盘过程中,map输出继续被写到缓冲区,但如果在此期间缓冲区被填满,map会阻塞直到写磁盘过程完成。在写磁盘之前,线程首先根据数据最终要传送到reducer把数据划分成相应的分区,在每个分区中,后台线程按键进行内排序,如果有一个combiner,它会在排序后的输出上运行。 reducer通过HTTP方式得到输出文件的分区。用于文件分区的工作线程的数量由任务的tracker.http.threads属性控制,此设置针对每个tasktracker,而不是针对每个map任务槽。默认值是40,在运行大型作业的大型集群上,此值可以根据需要调整。
- reducer端
map端输出文件位于运行map任务的tasktracker的本地磁盘,现在,tasktracker需要为分区文件运行reduce任务。更进一步,reduce任务需要集群上若干个map任务完成,reduce任务就开始复制其输出。这就是reduce任务的复制阶段。reduce任务有少量复制线程,所以能并行取得map输出。默认值是5个线程,可以通过设置mapred.reduce.parallel.copies属性改变。
在这个过程中我们由于要提到一个问题,reducer如何知道要从那个tasktracker取得map输出呢?
map任务成功完成之后,它们通知其父tasktracker状态已更新,然后tasktracker通知jobtracker。这些通知都是通过心跳机制传输的。因此,对于指定作业,jobtracker知道map输出和tasktracker之间的映射关系。reduce中的一个线程定期询问jobtracker以便获得map输出的位置,直到它获得所有输出位置。 由于reducer可能失败,因此tasktracker并没有在第一个reducer检索到map输出时就立即从磁盘上删除它们。相反,tasktracker会等待,直到jobtracker告知它可以删除map输出,这是作业完成后执行的。
如果map输出相当小,则会被复制到reduce tasktracker的内存(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制),否则,map输出被复制到磁盘。一旦内存缓冲区达到阀值大小(由mapred.job.shuffle.merge.percent决定)或达到map输出阀值(mapred.inmem.merge.threshold控制),则合并后溢出写到磁盘中。
随着磁盘上副本的增多,后台线程会将它们合并为更大的、排好序的文件。这会为后面的合并节省一些时间。注意,为了合并,压缩的map输出都必须在内存中被解压缩。
复制完所有map输出被复制期间,reduce任务进入排序阶段(sort phase 更恰当的说法是合并阶段,因为排序是在map端进行的),这个阶段将合并map输出,维持其顺序排序。这是循环进行的。比如,如果有50个map输出,而合并因子是10 (10默认值设置,由io.sort.factor属性设置,与map的合并类似),合并将进行5趟。每趟将10个文件合并成一个文件,因此最后有5个中间文件。 在最后阶段,即reduce阶段,直接把数据输入reduce函数,从而省略了一次磁盘往返行程,并没有将5个文件合并成一个已排序的文件作为最后一趟。最后的合并既可来自内存和磁盘片段。
在reduce阶段,对已排序输出中的每个键都要调用reduce函数。此阶段的输出直接写到输出文件系统中。
Hive
Hive和HBase我现在还接触的不多,简单介绍以下以后有空再仔细学习。 Hive 是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 QL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
Hive构建在 Hadoop 之上,
-
HQL 中对查询语句的解释、优化、生成查询计划是由 Hive 完成的
-
所有的数据都是存储在 Hadoop 中
-
查询计划被转化为 MapReduce 任务,在 Hadoop 中执行(有些查询没有 MR 任务,如:select * from table)
-
Hadoop和Hive都是用UTF-8编码的
HBase
hbase是bigtable的开源山寨版本。是建立的hdfs之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统。
它介于nosql和RDBMS之间,仅能通过主键(row key)和主键的range来检索数据,仅支持单行事务(可通过hive支持来实现多表join等复杂操作)。主要用来存储非结构化和半结构化的松散数据。
与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
HBase中的表一般有这样的特点:
1 大:一个表可以有上亿行,上百万列
2 面向列:面向列(族)的存储和权限控制,列(族)独立检索。
3 稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
进一步说明与实践建议
- HDFS 高可用与纠删码:生产部署多采用 NameNode HA(Active/Standby + JournalNodes),避免单点;Hadoop 3 引入 Erasure Coding 降低存储开销(以计算换空间),适合冷数据;
- HDFS 写入与副本:写入采用 pipeline + ack 链路,副本布局遵循机架感知策略,周期性 re-replication 修复数据;
- 数据均衡:使用 Balancer/移动策略在节点间均衡块分布,避免热点;
- MapReduce on YARN:本文叙述的 JobTracker/TaskTracker 属于 MRv1;在 YARN 中对应 ResourceManager/NodeManager + MRAppMaster 的职责划分更清晰、伸缩更好;
- Shuffle 与倾斜:Map 端 combiner/分区器可有效降低网络与磁盘开销;对倾斜 key 可做 salting 或在 SQL 场景启用 AQE;
- Hive 引擎与存储:现代 Hive 多以 Tez/Spark 执行引擎为主,建议使用列式存储 Parquet/ORC 与分区/分桶(bucketing),启用 CBO 优化器;
- HBase 架构:建议理解 WAL→MemStore→HFile 的写入路径、Region/RegionServer 的分裂与合并、BloomFilter 与压缩策略;HBase Master/RegionServer 借助 ZooKeeper 做协调;
- 集群与资源:Hadoop 3 提供更丰富的容器调度(GPU/FPGA)、路由联邦(Router-based Federation)与更好的 Timeline Service;
参考资料
- HDFS Architecture: https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
- HDFS High Availability: https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
- Erasure Coding in HDFS: https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/ECOverview.html
- MapReduce Tutorial: https://hadoop.apache.org/docs/stable/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html
- YARN Architecture: https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html
- Hive Language Manual: https://cwiki.apache.org/confluence/display/Hive/LanguageManual
- HBase Reference Guide: https://hbase.apache.org/book.html