推荐系统(Recommender System, RS)本质上解决的是一个信息过载问题:当候选物品的数量从几千膨胀到几百万甚至上亿时,用户既没耐心也没能力逐一浏览。搜索需要用户明确知道自己想要什么,而推荐的价值在于帮用户发现那些符合兴趣、但尚未意识到的物品。
过去十年,推荐系统已经从一套简单的协同过滤算法,演进为一个涵盖数据工程、召回策略、排序模型、在线服务和实验平台的完整工业系统。这篇文章尝试把工程架构与核心算法结合起来,重新梳理推荐系统的全貌。
推荐系统不是单一算法,而是一套流水线
在现代工业实践中,一个完整的推荐系统通常被拆分为四个核心阶段:数据处理与嵌入、多路召回、精准排序、重排与过滤。

| 阶段 | 输入 | 输出 | 核心任务 |
|---|---|---|---|
| 数据处理与嵌入 | 用户画像、物品属性、行为日志 | 特征向量、索引 | 特征工程、Embedding 生成、索引构建 |
| 多路召回 | 全量物料库(百万~亿级) | 千级候选集 | 从海量物品中快速筛选用户可能感兴趣的候选 |
| 精准排序 | 召回候选集 + 精细特征 | 百级有序列表 | 用复杂模型预测点击率/转化率,按分数排序 |
| 重排与过滤 | 排序结果 | 最终展示列表 | 去重、多样性打散、业务规则插入、疲劳度控制 |
这个分层的逻辑非常明确:召回负责“不错过”,排序负责“不排错”,重排负责“看得舒服”。如果跳过召回直接对全库排序,计算成本会高到不可接受;如果只有召回没有精排,推荐结果的精准度又无法满足用户体验。
召回层:协同过滤的核心思想
召回层是推荐系统的“海选”阶段,协同过滤(Collaborative Filtering, CF)是这里最经典、也最常 deployed 的一类方法。它的核心假设是:用户对物品的喜好不是孤立的,而是有规律可循的。
用户-物品评分矩阵
协同过滤的原始数据通常被组织成一个用户-物品评分矩阵。行代表用户,列代表物品,矩阵中的每个单元格是用户对物品的评分(显式反馈,如 1~5 星)或交互信号(隐式反馈,如点击、购买、播放)。
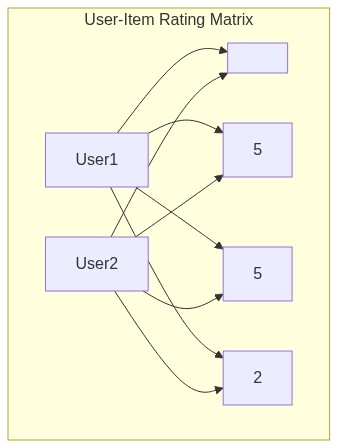
这个矩阵通常是极度稀疏的——没有任何用户会与所有物品产生交互。协同过滤的目标,就是利用已有的评分去预测那些空白单元格的值,从而把预测分数高的物品推荐给用户。
UserCF vs ItemCF
根据“找相似”的对象不同,协同过滤可以分成两条路径:
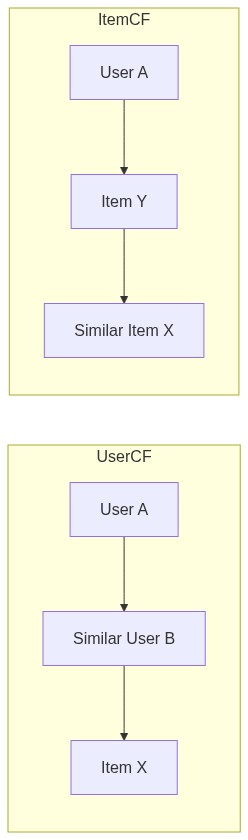
基于用户的协同过滤(UserCF)的思路是”人以群分”:先找到与目标用户兴趣相似的其他用户(邻居),然后把邻居喜欢但目标用户还没接触过的物品推荐给他。它的直觉是”和你品味相似的人喜欢的书,你也可能喜欢”。
基于物品的协同过滤(ItemCF)的思路是”物以类聚”:先计算物品之间的相似度(比如经常被同一批用户喜欢的两件物品被认为是相似的),然后当用户喜欢了一件物品 A,就把与 A 最相似的物品 B、C、D 推荐给他。它的直觉是”看了又看”、”买了也买”。
在工程实践中,ItemCF 往往更受欢迎,原因很简单:物品数量通常远小于用户数量,计算 Item-Item 相似度更轻量;而且用户的兴趣变化快,但物品的相似关系相对稳定,缓存更友好。
相似度度量
无论是 UserCF 还是 ItemCF,都需要一个度量相似性的函数。常见的选择有三种:
-
余弦相似度(Cosine Similarity):把两位用户对共同物品的评分看作两个 n 维向量,计算它们夹角的余弦值。取值范围 [-1, 1],值越大越相似。这是最通用、最常用的度量。
-
皮尔逊相关系数(Pearson Correlation):在余弦相似度的基础上,先减去各自的平均分,消除不同用户评分尺度差异的影响(比如有人习惯给高分,有人习惯给低分)。在显式评分数据上,皮尔逊通常比余弦表现更好。
-
杰卡德相似系数(Jaccard Similarity):计算两个集合的交集大小除以并集大小。它只关心”有没有交互”,不关心评分高低,因此非常适合处理隐式反馈(点击流、浏览记录)。
从协同过滤到矩阵分解
协同过滤的一个明显瓶颈是可扩展性:当用户和物品数量达到千万甚至亿级时,直接计算全量用户或物品之间的相似度会变得非常昂贵。而且稀疏矩阵中大量空白单元格也会干扰相似度的准确估计。
矩阵分解(Matrix Factorization, MF)提供了一个更优雅的解法。它的核心思想是:把庞大的用户-物品评分矩阵,分解为两个低维稠密矩阵的乘积。
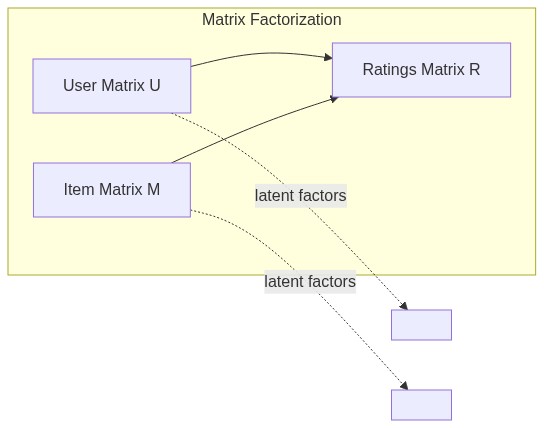
假设原始评分矩阵为 R(m 个用户 × n 个物品),我们希望找到:
- 一个用户隐因子矩阵 U(m 个用户 × k 个隐因子)
- 一个物品隐因子矩阵 M(k 个隐因子 × n 个物品)
使得 U × M ≈ R。这里的 k 是远小于 m 和 n 的维度(比如 50~200)。
这些”隐因子”(Latent Factors)没有显式的物理意义,但它们捕捉了用户兴趣和物品属性的抽象特征。比如某个隐因子可能同时对应”科幻”+”宏大叙事”,那么喜欢《星际穿越》的用户在这个因子上的得分会很高,而《2001太空漫游》在这个因子上的得分也会很高。通过两个向量的点积,我们就能预测用户对任意物品的评分。
工业界常用的矩阵分解算法包括:
- SVD(奇异值分解):通过数学方法直接分解矩阵,适用于稠密或填充后的数据。
- ALS(交替最小二乘法):固定一个矩阵,优化另一个,交替迭代直到收敛。Spark MLlib 中的推荐算法就是基于 ALS 实现的。
- 隐语义模型(LFM):专门处理隐式反馈数据,通过引入置信权重来区分”没看过”和”不喜欢”。
矩阵分解的优势在于:它把推荐问题从”在高维稀疏空间中寻找邻居”,转化为了”在低维稠密空间中的向量点积”,计算效率大幅提升,同时也更容易与向量检索系统(如 Redis、Faiss、Milvus)结合部署。
排序层:从 LR 到深度学习
召回层从海量物品中筛选出几百到几千的候选集,接下来排序层要做的就是给这些候选精确打分,并按分数从高到低排列。
排序问题可以被形式化为一个函数 F(user, item, context) → score,其中 score 通常是点击率(CTR)、转化率(CVR)或综合收益的预期值。
从线性模型到深度模型
-
逻辑回归(Logistic Regression, LR):早期最基础的排序模型。将用户画像向量、物品特征向量和上下文特征向量拼接在一起,输入一个广义线性模型,输出 0~1 之间的概率。LR 的优点是可解释性强、训练和预测都很快;缺点是难以自动捕捉特征之间的交叉关系。
-
GBDT + LR:用梯度提升树(GBDT)自动挖掘有效的特征组合,再把树输出的叶子节点作为新特征输入 LR。这在 2014~2016 年间是工业界的主流方案之一。
-
深度模型(DeepFM / DIN / BERT-based):随着算力提升,深度神经网络逐渐成为排序层的主流。DeepFM 同时学习低阶特征交叉和高阶非线性关系;DIN(Deep Interest Network)引入注意力机制,根据候选物品动态加权用户历史行为序列;更现代的系统甚至用 BERT 类模型对物品标题、描述进行语义编码,融入排序特征。
在工程上,排序模型通常是推荐系统里最”重”的模块:特征最多、模型最复杂、延迟要求最严格。因此很多公司会把排序服务拆分为”粗排”(轻量模型,快速筛选)和”精排”(复杂模型,精确打分)两个子阶段。
工程架构中的关键问题
把算法跑通只是第一步,真正上线一个推荐系统,还需要解决一系列工程问题。
冷启动
冷启动分为三种:新用户冷启动(没有历史行为)、新物品冷启动(没有交互记录)、新系统冷启动(平台初期数据稀疏)。
常见的应对策略包括:
- 用热门榜单或编辑精选作为兜底
- 利用用户的注册信息、社交关系、设备属性做内容-based 推荐
- 新物品给予一定的流量扶持(探索机制)
- 多模态内容理解(标签、文本、图像),在行为数据不足时直接用内容特征做匹配
多路召回融合
工业系统很少只依赖单一召回通道。常见的召回路径包括:
- 协同过滤召回(UserCF / ItemCF / MF)
- 向量Embedding召回(双塔模型、Graph Embedding)
- 热门/地域/新品策略召回
- 用户历史行为触发召回
多路召回的结果需要融合在一起,再交给排序层。融合策略可以是简单的加权去重,也可以是用一个小模型做召回间的二次筛选。
实时性与缓存
推荐系统的响应延迟直接影响用户体验。工程上通常采用”离线预计算 + 在线实时补全”的混合架构:
- 用户Embedding、物品相似度、热门榜单可以离线批量计算,写入缓存或向量数据库
- 用户最近几分钟的点击、收藏等行为,通过实时流处理(如 Flink)快速更新到在线特征中
- 排序模型本身通常以 TFServing / TorchServe 等模型服务框架部署,要求 P99 延迟在几十毫秒以内
AB 测试与指标体系
推荐系统的优化是持续迭代的过程,AB 测试是评估新算法效果的必备手段。常见的核心指标包括:
- 点击率(CTR):点击次数 / 曝光次数
- 转化率(CVR):转化次数 / 点击次数
- 人均曝光时长 / 人均点击次数:反映用户粘性
- 多样性(Diversity)和新颖性(Novelty):避免推荐结果过于同质化
- 覆盖率(Coverage):有多少长尾物品被推荐出去
写在最后
从 2014 年写下这篇博客的初稿到现在,推荐系统已经发生了巨大的变化。早期的关注点可能是”欧氏距离和皮尔逊系数哪个更好”,而今天工业界更关心的是”如何把十亿级别的向量检索做到毫秒级延迟”、”如何用多目标模型同时优化点击和停留时长”、”如何在召回阶段就把内容语义和用户长期兴趣对齐”。
但底层逻辑并没有变:推荐系统始终是在信息过载的场景下,通过算法和工程手段,把”用户可能最感兴趣的内容”高效、准确地送到他们面前。理解召回、排序、重排的分层架构,掌握协同过滤和矩阵分解的核心思想,是进入这个领域的坚实起点。