Anchor Box最早是在Faster-R-CNN中被提到使用,此后在SSD、YOLOv2、YOLOv3等一系列目标检测网络中被普遍使用。Anchor Boxes实质上是一组人为预先设定的检测尺寸框,各个anchor box之间都有各自不同的尺寸和长宽比,以适应不同的被检物体类别。
Anchor boxes是一组具有一定高度和宽度的预定义边界框。定义这些anchor boxes是为了捕获待检测的具有特定尺寸和长宽比的对象类别,它们自身的尺寸和长宽比通常是根据训练数据集中的对象大小来选择的。在检测期间,预定义的anchor boxes会平铺在图像上。网络会在每一个anchor box上预测出被检测对象的存在概率和其他一些属性,如IOU和偏移量等。这些预测会被用于重新完善每一个特定的anchor box。网络不会直接在anchor box上预测出物体的bounding box位置,但是会预测在这个anchor box上出现物体的可能性和细化结果。网络会为定义的每一个anchor box返回一组唯一的预测。最终的feature map会代表每一类的检测结果。对anchor boxes的使用可以让网络能够检测到多个不同比例以及重叠的对象。
Why use anchor boxes?
在anchor boxes之前,我们常用的物体检测方法有两种:
1,滑动窗口 Sliding Windows
简单而粗糙的遍历轮询方法,使用固定尺寸的窗口,在feature map上每一次移动固定步长,从左往右、从上往下,逐个遍历完整个feature map,把被窗口盖住的内容输入到后续的卷积神经网络里进行计算,得到分类标签和位置信息等。但是滑动窗口的缺陷也非常明显:1,由于窗口尺寸固定,步长固定,因此不适合形变较大的物体;2,窗口总量较多,所以需要的运算量较大。
2,区域建议 Region Proposal
这是R-CNN系列中引入的方法,如Faster R-CNN模型中分别使用CNN和RPN(Regional Proposal)两个网络。其中区域建议网络不负责图像的分类,它只负责选取出图像中可能属于数据集其中一类的候选区域。接下来就是把RPN产生的候选区域输入到分类网络中进行最终的分类。其中Selective Search是更早的一种获得RP的方法,主要依赖的是一些关于图像的先验知识,如颜色、纹理等。可以分为四个步骤:1,将分割的图片画出多个框,把所有框放入列表Region中;2,根据相似程度(颜色,纹理,大小,形状等),计算Region中框之间的俩俩形似度,把相似度放入列表A中;3,从列表A中找出相似度最大的俩个框a,b并且合并;4,把合并的框加入列表Region中,从A中删除和a,b相关的相似度,重复步骤2,直至清空A。
但是无论哪种方法,都无法很好解决两个问题:1,一个窗口只能检测一个目标;2,无法检测尺寸很大或者长宽比很极端的物体。
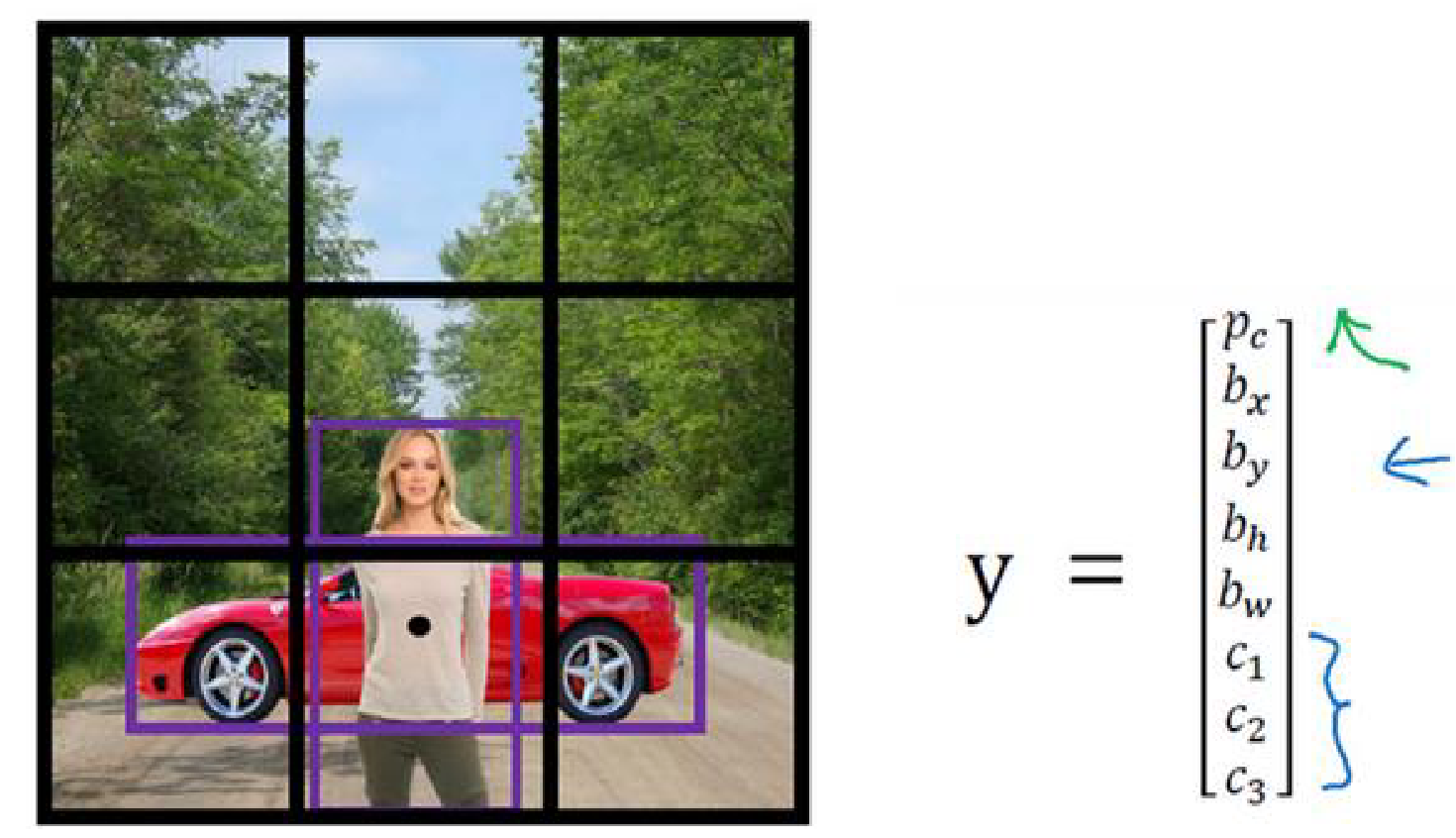
如上图作为输入,如果我们用3x3网格,而需要被检测的人和汽车的中心恰好都落在同一个网格中。假设我们用y作为这个格子的输出向量,y=[p_c, b_x, b_y, b_h, b_w, c_1, c_2, c_3]^T,其中p_c表示检测置信度,[b_x, b_y, b_h, b_w]表示物体bounding box位置(左上角x、y和高h、宽w),[c_1, c_2, c_3]是以one-hot编码形式表示的三种类别(如人、汽车、摩托车)中的一种。因此从一个输出向量y中我们只能选择一种类型作为检测输出。

当我们引入了anchor box的思路后,会首先定义所需要的anchor boxes个数和尺寸,比如在此我们简单地假定使用两个不同的anchor boxes 1 & 2。然后将上述预测结果y跟这两个anchor box关联起来。这一次我们会扩充输出的向量y,由于我们现在有两个anchor boxes,因此我们将它用类似的结构重复两次:
y = [p_c, b_x, b_y, b_h, b_w, c_1, c_2, c_3, p_c, b_x, b_y, b_h, b_w, c_1, c_2, c_3]^T
其中前半段的p_c~c_3参数属于anchor box 1,后半段属于anchor box 2,如果我们有多于两个的anchor boxes,那以此类推,有几个就设置几段,这在我们人眼阅读起来仿佛参数很多很繁杂,但在计算机概念中,却是很容易处理的。当我们获得这个框的输出后,由于人体的形状更接近于anchor box 1,因此前半段的p_c = 1,表示这里有个行人对象,用b_x~b_w输出框住行人,然后用[c_1=1, c_2=0, c_3=0]表示对象标签是行人。同理,汽车更接近anchor box 2的形状,因此后半段的输出可以是[p_c=1, b_x, b_y, b_h, b_w, c_1=0, c_2=1, c_3=0]。
总结一下,之前的做法是在训练图像中,每一个检测目标对象都被关联分配到一个包含该对象中心点的网格中,如上个例子中,如果图像被分割为3x3的网格,那么输出的y尺寸就是3x3x8,其中3x3是网格尺寸,8是[p_c, b_x, b_y, b_h, b_w, c_1, c_2, c_3]八个参数。而当我们给这个训练图像设置了2个anchor boxes之后,每个检测目标对象同样会被关联分配到一个包含该对象中心点的网格以及跟该对象边界框有最大IOU的anchor box。所以每一个输出的y尺寸变成了3x3x8x2。但同样,anchor boxes不是万能的,它们无法很好地区分本身长宽比或形状很相似的物体,也无法在检测与所有设定anchor boxes形状都差距巨大的物体,同样,当我们只预设了两个anchor boxes而待检测的目标有三类以上时,同样需要额外的处理手段来解决。
那么anchor box的尺寸该怎么选择?目前anchor box的选择主要有三种方式:
- 人为经验选取
- k-means聚类
- 作为超参数进行学习
When to use it?
Anchor Box会在训练和预测的阶段被使用到。
训练阶段
标注
在训练阶段,是把anchor box作为训练样本,为了训练样本我们需要为每个锚框标注两类标签:一是锚框所含目标的类别,简称类别;二是真实边界框相对锚框的偏移量,简称偏移量(offset)。在目标检测时,我们首先生成多个锚框,然后为每个锚框预测类别以及偏移量,接着根据预测的偏移量调整锚框位置从而得到预测边界框,最后筛选需要输出的预测边界框。我们使用每个目标和ground truth之间的最大IOU来对anchor box标注,找到与每个anchor box具有最大IOU的ground truth,并以此作为该anchor box的标签,将其相对于ground truth真实bounding box之间的偏移量标注入anchor box。
训练
在经过一系列卷积和池化之后,在feature map层使用anchor box,以上文中的3x3图像为例,经过一系列的特征提取,最后针对3x3的网格会得到一个3x3x2x8的特征层,其中2是anchor box的个数,8代表每个anchor box包含的变量数,分别是1个anchor box标注(如果anchor box与真实边框的交并比最大则为1,否则为0)、4个位置偏移量、3个类别(one-hot标注方式)。到了特征层之后对每个cell映射到原图中,找到预先标注的anchor box,然后计算这个anchor box与ground truth之间的损失,训练的主要目的就是训练出用anchor box去拟合真实边框的模型参数。看一下损失函数会更加有助于理解这个概念,Faster R-CNN原文中采用的损失函数为:

预测阶段
首先在图像中生成多个anchor box,然后根据训练好的模型参数去预测这些anchor box的类别和偏移量,进而得到预测的边界框。由于阈值和anchor box数量选择的问题,同一个目标可能会输出多个相似的预测边界框,这样不仅不简洁,而且会增加计算量,为了解决这个问题,常用的措施是使用非极大值抑制(non-maximum suppression,NMS)。
附:非极大值抑制NMS
非极大值抑制(Non-Maximum Suppression, NMS), 顾名思义就是抑制那些不是极大值的元素, 可以理解为局部最大值搜索。对于目标检测来说, 非极大值抑制的含义就是对于重叠度较高的一部分同类候选框来说, 去掉那些置信度较低的框, 只保留置信度最大的那一个进行后面的流程, 这里的重叠度高低与否是通过 NMS 阈值来判断的。
其中两个box之间的IOU计算可以是:
- x_1 = max(x1_box1, x1_box2) // 右边界
- y_1 = max(y1_box1, y1_box2) // 下边界
- x_2 = min(x2_box1, x2_box2) // 左边界
- y_2 = min(y2_box1, y2_box2) // 上边界
- area1 = (x1_box1 - x2_box1 + 1) * (y1_box1 - y2_box1 + 1) // box1面积
- area2 = (x1_box2 - x2_box2 + 1) * (y1_box2 - y2_box2 + 1) // box1面积
- intersection = (x_2 - x_1 + 1) * (y_2 - y_1 + 1) // 相交区域面积
- IOU = intersection / (area1 + area2 - intersection) // 计算IOU
算法逻辑:
- 输入: n 行 4 列的候选框数组, 以及对应的 n 行 1 列的置信度数组.
- 输出: m 行 4 列的候选框数组, 以及对应的 m 行 1 列的置信度数组, m 对应的是去重后的候选框数量
算法流程:
- 计算 n 个候选框的面积大小
- 对置信度进行排序, 获取排序后的下标序号, 即采用argsort
- 将当前置信度最大的框加入返回值列表中
- 获取当前置信度最大的候选框与其他任意候选框的相交面积
- 利用相交的面积和两个框自身的面积计算框的交并比, 将交并比大于阈值的框删除.
- 对剩余的框重复以上过程
import cv2
import numpy as np
def nms(bounding_boxes, confidence_score, threshold):
if len(bounding_boxes) == 0:
return [], []
bboxes = np.array(bounding_boxes)
score = np.array(confidence_score)
# 计算 n 个候选框的面积大小
x1 = bboxes[:, 0]
y1 = bboxes[:, 1]
x2 = bboxes[:, 2]
y2 = bboxes[:, 3]
areas =(x2 - x1 + 1) * (y2 - y1 + 1)
# 对置信度进行排序, 获取排序后的下标序号, argsort 默认从小到大排序
order = np.argsort(score)
picked_boxes = [] # 返回值
picked_score = [] # 返回值
while order.size > 0:
# 将当前置信度最大的框加入返回值列表中
index = order[-1]
picked_boxes.append(bounding_boxes[index])
picked_score.append(confidence_score[index])
# 获取当前置信度最大的候选框与其他任意候选框的相交面积
x11 = np.maximum(x1[index], x1[order[:-1]])
y11 = np.maximum(y1[index], y1[order[:-1]])
x22 = np.minimum(x2[index], x2[order[:-1]])
y22 = np.minimum(y2[index], y2[order[:-1]])
w = np.maximum(0.0, x22 - x11 + 1)
h = np.maximum(0.0, y22 - y11 + 1)
intersection = w * h
# 利用相交的面积和两个框自身的面积计算框的交并比, 将交并比大于阈值的框删除
ratio = intersection / (areas[index] + areas[order[:-1]] - intersection)
left = np.where(ratio < threshold)
order = order[left]
return picked_boxes, picked_score