Optical Character Recognition(OCR),直译为光学字符识别,是从文本资料的图片或影印件当中进行文字内容识别,从而获得文字内容和版面信息的过程。早在DL热潮之前就有了一定研究,但依靠人工设定的中低层特征提取的方法所提取到的特征,往往处于一种低维度的粗糙状态,并且受到繁琐的前后处理过程影响。而DL带来的最大提升也是在于解决了特征提取的困境。在实践过程中,具体会体现在以下三个方面:
- 自然场景中文本的多样性和可变性:如一段文字可以以不同的语言、颜色、字体、尺寸、方向、形状、长宽比来展示;
- 背景的复杂性和干扰:背景可能跟文字的模式非常接近,或者存在一些挤压和遮挡;
- 图片成像条件不完善:当时采集图片时成像过曝、光线不足或失焦模糊导致像素丢失等,都会给文字识别带来挑战。
近年来,对上述困难所取得的研究成果,也可以归纳为三点:
- 深度学习(DL)的协助;
- 更加具有挑战性的算法和数据集的建立;
- 辅助技术的进步。
Methodology
当前研究趋势:
- 检测:
- 简化流水线:Anchor-based: EAST,Region-proposal: R2-CNN;
- 差异化预测单元:Text-instance: TextBoxes, Sub-text:pixel components;
- 特殊目标:Long Text, Multi-orientation, Irregular shapes, Easy instance segmentation, Retrieving designated text, Against complex background;
- 识别:
- CTC:CNN+RNN, Conv Sequence Learning, Sliding window;
- 注意力机制:Attention-based decoding, Supervised Attention, Edit Probability-Based Training, Rectification;
- 端到端:
- 集成化Multi-Step:Separately Training, Passing cropped images;
- 端到端可训练两步:Jointly trained, Passing cropped feature maps,gradients propagate end-to-end;
- 辅助技术:
- 合成数据: Synthesize cropped images, Rendering with nature images, Selective semantic segmentation;
- Bootstrapping: Bootstrapping for character boxes, Bootstrapping for word boxes;
- 其他: Deblurring, Leveraging Context, Adversarial Attack.
Pipeline Simplification
早先的基于传统特征提取和某些基于深度学习的方法将文本检测任务分为多个步骤。近期的方法则尝试简化流水线,将多个子任务放到一个端到端的网络中完成,只在前面加上必要的预处理。这样做的好处是使得整个流水线更加简单方便训练,同时也可以增加预测的效率。
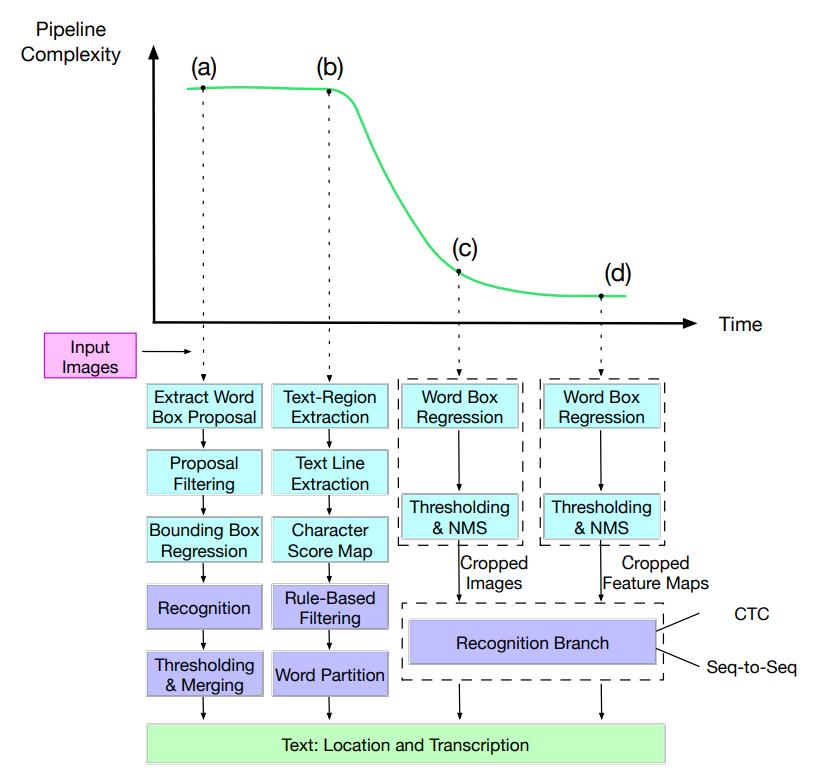
其中, (a)和(b)是具有代表性的多步骤方法,而(c)和(d)是简化的流水线。在(c)中,检测器和识别器是分开的。在(d)中,检测器将裁剪后的特征图(feature map)传递给识别器,可以进行端到端的训练。
Detection
基于文本场景上的检测,主要经历了三个步骤:
- 在最初,一些基于先验知识预先学习得到的方法会被配置于多步骤的流水线中,但这些方法往往会复杂而缓慢;
- 之后,一些原本用于通用物体检测的方法被成功地应用于这一领域;
- 第三阶段,研究者基于子文本组件设计的一些特殊的repre-sentations,可以用来解决长文本和特殊文本所带来的的挑战。
在应用DL的初期,往往会使用CNN来预测局部的片段,然后使用一些启发式的后处理方法,将这些片段合并入检测流程当中。这些方法往往只能将一张图片块分类成文字patch和非文字patch。之后,CNN可以把整张图片应用于全卷积,以获得文字区域的位置,甚至判断某一个特定的像素是否属于文字的一部分,或在文字内部,或在文字周围。这一阶段虽然摆脱了一些人工预定义的先验知识在特征处理上的困境,但仍然依赖于一个较长的流水线且效率较低,整个方法的设计依然自下而上地依赖于关键要素,比如单个字符或者本文中心线等。
然而,快速发展的通用物体检测给这一任务带来了启发,人们开始通过修改region proposal和bounding box回归模块来设计算法直接定位到图像中文本位置。这些方法主要由堆叠的卷积层组成,这些卷积层将输入图像编码为特征图。 特征图上的每个空间位置都对应于输入图像的一个区域。 然后将特征图输入到分类器中,以预测每个此类空间位置处文本实例的存在和定位。这些方法很大程度上将流水线简化成一个端到端能被训练的网络组件,且更容易被训练和推理。
其中较为有代表性的就是EAST,通过采用U型设计简化了基于anchor的的检测,进一步集成了不同层面的特征。输入图像被编码为一个多通道特征图,而不是SSD中的不同空间大小的多层特征。每个空间位置处的要素都用于直接使基础文本实例的矩形或四边形边界框回归,以此预测文本的存在和位置信息。
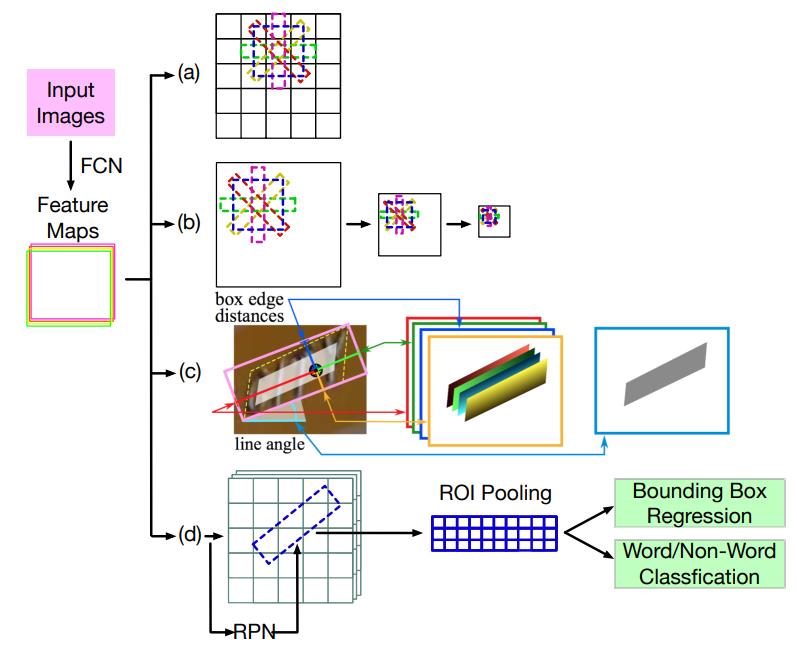
(a)与YOLO类似,基于每个anchor位置的默认边界框回归偏移量。(b)SSD的变体,在不同比例的特征图上进行预测。(c)预测每个anchor的位置并直接使边界框回归。(d)分两个阶段的方法,并有一个额外的阶段来校正初始回归结果。
简化流水线的方法也有局限性,在遇到复杂场景和长文本的时候往往检测效果不佳。于是多步骤的检测方法又被重新提起来解决这类问题,其思路往往是在基于神经网络的检测后加上后处理来构造文本实例,这种多步骤的方法跟传统的多步骤方法的区别在于其对神经网络依赖度更高,整个流水线也更加简洁。
文本检测与一般对象检测之间的主要区别在于,文本在整体上是同质的,同时有具有文本本身的局部性,这与常规对象检测不同。 通过同质性和局部性,我们可以认为文本实例的任何部分仍然是文本的属性。 我们不需要看到整个文本实例就知道它属于某些文本。这就衍生出了另一种方法,即只对文本中的一部分sub-text的检测,然后假定其就属于某一组文本实例。这一类方法更依赖于神经网络,同时拥有更短小的流水线,适应于弯曲、较长和方向不一致的文本识别问题。