Deep SORT是多目标跟踪Multiple Object Tracking(MOT)中常用到的一种算法,是一个基于检测的跟踪(Tracking-by-Detection)方法。主要任务是:给定一个图像序列,找到序列中运动的物体,并在不同帧之间保持同一物体的一致身份(ID)。
整个计算架构可以简单地被分为四个主要步骤,当获得一系列待检测的原始视频帧之后:
- 检测:用如 Faster R-CNN、YOLOv3、SSD 等工具进行目标检测,获得对应目标的检测框(BBox),这是其中依赖程度最高的一个步骤;
- 特征提取:提取被检测目标的表观特征或运动特征;
- 相似度计算:构建代价矩阵(Cost Matrix),常见度量包括 IoU(几何重叠)、马氏距离(运动一致性)与余弦距离(表观相似性);
- 关联:计算连续数帧画面中被检测物体的关联程度以确定是否同一物体,常用方法为卡尔曼滤波与匈牙利算法(DeepSORT 中还配合级联匹配)。
其中,SORT 和 DeepSORT 的核心就是卡尔曼滤波和匈牙利算法。
- 卡尔曼滤波分为两个过程:预测与更新。该算法将目标的运动状态定义为 8 维向量。
预测:当目标发生移动时,通过上一帧的目标框和速度等参数,预测出当前帧的目标框位置与速度;更新:将预测值与观测值进行融合,得到当前系统对状态的最优估计。 - 匈牙利算法解决的是一个分配问题:在 MOT 的关联步骤中,先计算“前后两帧”的代价(相似度)矩阵,再通过最小化总代价来得到最佳匹配方案。
而 SORT 算法中只通过前后两帧 IoU 来构建相似度矩阵,所以运行速度很快,但在遮挡、近邻目标等复杂场景下容易出现 ID Switch。

Kalman filter
所谓卡尔曼滤波,简单来说就是在存在一定不确定性噪声的动态系统里,对于目标物体下一步运动进行推测的方法。推测的内容包括之后出现的运动位置以及速度等。
对于卡尔曼滤波而言,目标物体在任意时间点下都有一个状态,与速度、位置相关,且假设变量 p(位置)和 v(速度)都符合随机高斯分布,。卡尔曼滤波通过协方差矩阵来描述速度与位置之间的相关性,即矩阵的 ij 位置上元素的值描述了第 i 个和第 j 个变量之间的相关程度。
因此,在完成建模之前还需要补充两个信息,即 k 时刻下目标物的最佳估计值和协方差矩阵:
在△t 的时间间隔后,假设将位置和速度有如下更新方法:
用矩阵形式表示:
根据协方差矩阵性质,可得:
引入外部影响:
其中 B 为控制矩阵,u 为控制变量;若外部控制可忽略,则该项可置零。
引入外部不确定性(过程噪声) Q_k:
概况而言就是:
新的最佳估计是基于原最佳估计和已知外部影响校正后得到的预测;新的不确定性是基于原不确定性和外部环境的不确定性得到的预测。
SORT
SORT的目标建模是一个八维的模型:
前三个变量分别表示当前目标在坐标轴的横轴值、纵轴值、BBox 的尺寸比例和高,后四个变量为下一帧预测的位置横坐标、纵坐标和 BBox 尺寸上的相对速度。
SORT 使用匈牙利指派算法进行数据关联,使用的 cost 矩阵为原有目标在当前帧中的预测位置和当前帧目标检测框之间的 IoU。当然,小于指定 IoU 阈值的指派结果是无效的。作者发现使用 IoU 能够处理目标的短时遮挡:当目标被遮挡时,检测器可能检测到遮挡物而漏检原目标;若误将遮挡物与原目标关联,在遮挡结束后,因相近大小目标间 IoU 较大,较易恢复正确关联(前提是遮挡物面积大于目标)。如果连续 T_lost 帧没有实现已追踪目标预测位置和检测框的 IoU 匹配,则认为目标消失。实验中设置 T_lost=1,原因有二:一是匀速运动假设不总是合理,二是主要关注短时目标追踪;此外,尽早删除已丢失的目标有助于提升追踪效率。
但是在 SORT 中,目标仅仅根据 IoU 来进行匹配,必然会导致 ID Switch 非常频繁。
Deep SORT
Deep SORT 相比 SORT,通过集成表观信息来提升 SORT 的表现。通过这个扩展,模型能够更好地处理目标被长时间遮挡的情况,将 ID switch 指标降低约 45%。Deep SORT 沿用了上述的八维特征来对目标物建模,但新增了对轨迹的状态管理(新增/确认/删除)与级联匹配策略。
在 SORT 中,我们直接使用匈牙利算法去解决预测的卡尔曼状态和新来的状态之间的关联度;在 Deep SORT 中,需要将目标运动和表观特征信息相结合,通过融合两个度量指标来提高鲁棒性。首先使用马氏距离来评价预测的卡尔曼状态与新观测之间的一致性:
等价地,严格书写应为:
\[d^{(1)}(i,j)=(d_j-y_i)^T S_i^{-1} (d_j-y_i)\]表示第 j 个检测结果和第 i 条轨迹之间的运动匹配度,其中 S_i 是轨迹由卡尔曼滤波器在当前时刻预测观测空间的协方差矩阵,y_i 是轨迹在当前时刻的预测观测量,d_j 是第 j 个检测结果的状态 (u, v, r, h)。
可以用指示器形式描述马氏距离与阈值之间的关系:
论文中默认阈值 t^(1)=9.4877(4 自由度卡方分布 0.95 分位)。
为弥补不确定性较高时马氏距离度量可能失效的问题,还会使用第 i 个轨迹与第 j 个检测之间的最小余弦距离作为第二个度量:
余弦距离也有一个指示器:
默认阈值 t^(2)=0.2。综合匹配程度可以将上述二者加权求和(实际常用 (\lambda\approx 0.98),表观主导):
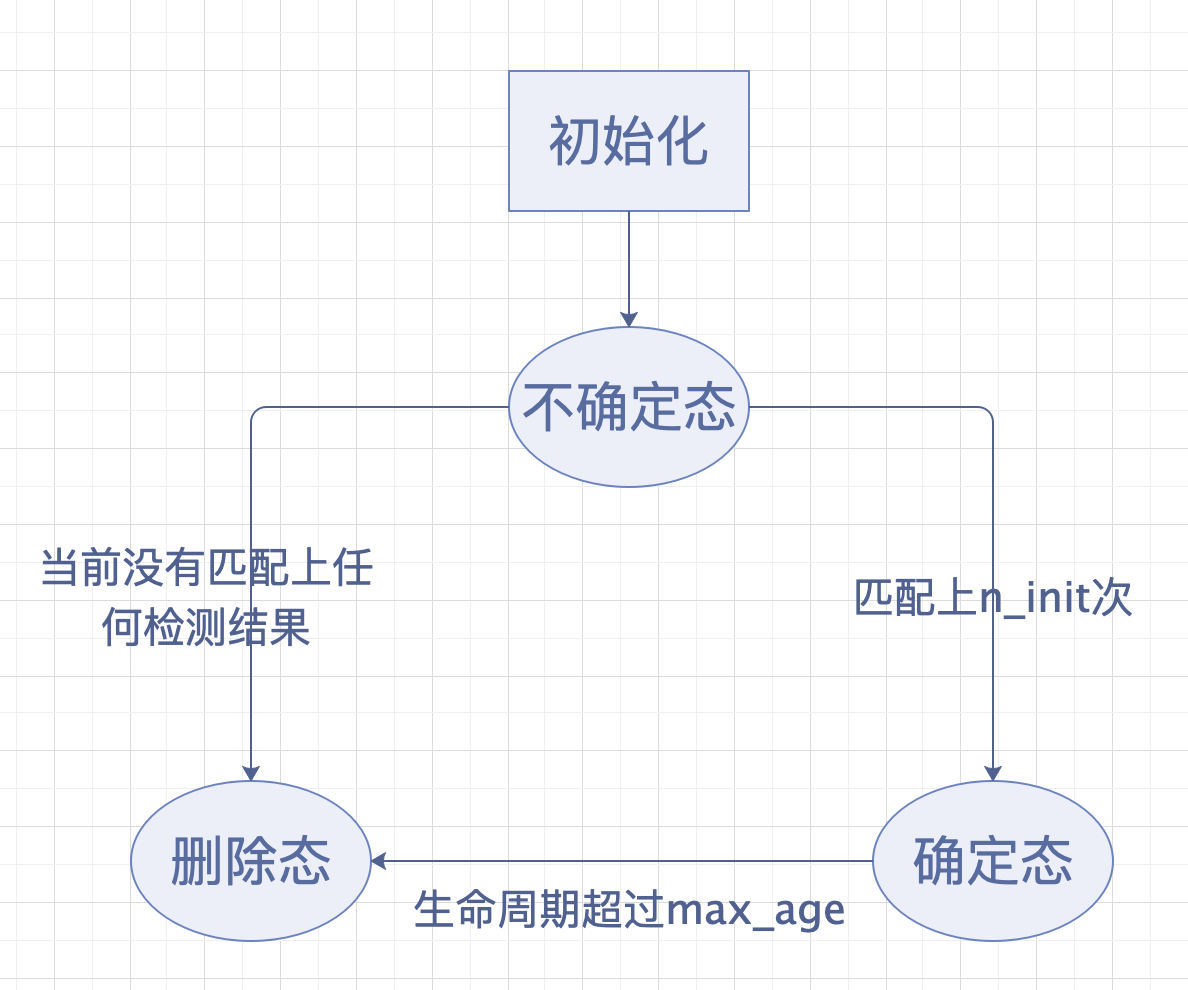
对于每一个轨迹,都计算当前帧距离上次匹配成功的差值。如果产生新的检测结果和现有轨迹无法匹配,则初始化生成一组新的轨迹,新生成的轨迹赋予 不确定态。而当新轨迹连续三帧都匹配成功,则转换为 确定态;当某一个轨迹生命周期超过最大阈值后认为轨迹离开画面区域,或连续多帧未匹配成功,则转换为 删除态,从当前轨迹集合中删除。
级联匹配是 Deep SORT 区别于 SORT 的一个核心算法,致力于缓解目标被遮挡带来的错误关联。为了让当前检测结果优先匹配上“最近刚消失”的轨迹,匹配时按轨迹的消失时长(age)从小到大分批进行(age=1 优先,直到 max_age)。当目标被长时间遮挡之后,卡尔曼滤波预测结果的不确定性会增大,此时若与“路过”的新目标竞争同一检测框,容易误配。分批匹配可显著降低这种风险。
因此引入了级联匹配的思路(流程要点):

- 分配轨迹索引和检测结果索引;
- 计算基于余弦距离的 cost matrix;
- 计算基于卡尔曼滤波预测的每个轨迹的平均位置和实际检测获得的 BBox 之间的平方马氏距离 cost matrix;
- 对于大于阈值的对应项(判为不可能匹配),将其设置为无穷大以禁止匹配;小于阈值的对应项保留原值以允许匹配;
- 使用匈牙利算法对检测结果和轨迹进行匹配,并返回匹配结果;
- 对匹配结果进行筛选,删去外观信息差距过大(即余弦距离过大)的配对;
- 得到初步的匹配结果和未匹配成功的检测结果及轨迹。
实践建议与评价指标(可选)
- 参数建议:
max_age(如 30~70)、min_hits(如 3)、λ(DeepSORT 中常取 0.98),t^(1)与t^(2)采用论文默认即可; - 检测器质量强相关:提升检测召回与定位精度,往往比调参更有效;
- 适度的 NMS 与置信度阈值可降低误检对关联的扰动;
- 评价指标:MOTA、IDF1、ID Switch、Mostly Tracked(MT)/Mostly Lost(ML)等,可综合评估跟踪性能与身份保持能力。