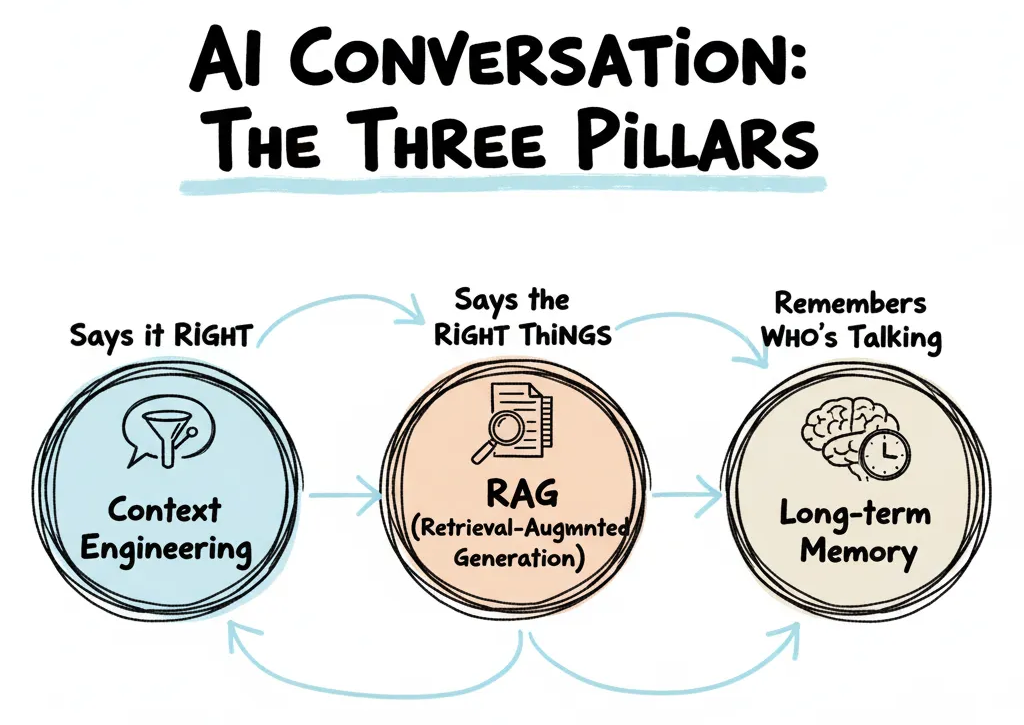
Context、RAG、Memory 不是互斥,而是互补。上下文工程用于会话即时优化,RAG 用于把权威文档注入生成,长期记忆用于跨会话个性化。
Context、RAG、Memory 对比
| 维度 | Context Engineering | RAG | Memory |
|---|---|---|---|
| 本质 | 控制输入 → 激活模型内在能力 | 引入外部证据 → 抑制幻觉 | 持久化状态 → 构建个体认知 |
| 数据 | 会话内示例/摘要 | 外部文档库 | 用户历史/事件/偏好 |
| 持久性 | 临时(策略可存) | 文档持久,检索临时 | 持久+衰减+删除 |
| 检索 | 规则/摘要压缩 | 向量+BM25+重排 | 向量+时间+标签检索 |
| 成本 | 低(仅需索引) | 中(检索+重排) | 高(存储+合规+维护) |
| 延迟 | 几乎无 | 中~高 | 中(取决于索引) |
| 核心价值 | 快、准、可控 | 真、可溯 | 个性、连续、忠诚 |
| 致命风险 | 上下文窗口耗尽 | 检索出错 = 生成出错 | 错误记忆 = 信任崩塌 |
| 总结定位 | 上下文是有限有形状的容器 | 检索是显微镜 | 记忆是大脑皮层 |
简言之,context engineering 是通过控制 prompt 本身的格式和指令来让用户“说对话”,而 RAG 是通过引入外部证据来抑制幻觉,也就是“说对事”。Memory 则是通过持久化状态来构建个体认知,让用户“记得谁在说话”。
常见实现方式
通用的步骤: 1. 先用上下文工程 —— 0成本提效,先跑通闭环 2. 再上RAG —— 只对关键文档启用,避免全库检索 3. 最后建记忆 —— 仅存“用户身份+关键状态+偏好”,非全部对话 4. 缓存+压缩+遗忘 —— 成本杀手三件套 5. 隐私即设计 —— GDPR(欧盟标准真是严格)不是补丁,是架构底座
其中涉及的工具: - 上下文:LangChain(模板)、PromptLayer - RAG:LlamaIndex + Chroma/FAISS + GPT-4-turbo - 记忆:Redis(键值)、Pinecone(向量)、Zep(带策略)
Context 和 Prompt
其中 context 和 prompt 是互补的,context 是会话即时优化,属于 数据,prompt 是会话长期优化,属于 指令。我们给模型的不是 “所有信息”,而是 “怎么用关键信息”。
| 维度 | Context(上下文) | Prompt(提示) |
|---|---|---|
| 本质 | 原始数据(what) | 控制逻辑(how + format + constraint) |
| 来源 | 检索、记忆、API、历史对话 | 模板 + 上下文摘要 + 用户问题 |
| 目标 | 提供证据 | 指导推理、格式、引用、优先级 |
| 处理重点 | 召回质量、去重、摘要、隐私过滤 | 模板稳定、token 节约、来源标注、指令清晰 |
| 存储 | 长期可存(向量库/知识图谱) | 动态构造,模板缓存,实例不存 |
| 风险 | 过时、冗余、冲突、泄露 | 指令模糊、token 超限、角色混淆、注入攻击 |
使用示例:会议议程生成工作流
用户问:“生成下周会议议程,基于上次记录和政策文档,标注来源。”
Context(原材料池,非直接输入)
记忆_2024-05-10:上次会议“预算审批延迟”RAG_003:《差旅报销政策 v3》第 2 条:“超 5k 需 CTO 审批”API_日程:张三 6/3 14:00–15:00 不可用冗余原文:2000字会议纪要全文 (不进 prompt)
Prompt(最终输入模型的文本)
[SYSTEM]
你是一个专业会议助理。输出格式严格为:
1. 每项议程:【标题】(来源:记忆_X / 文档_Y)
2. 总时长≤30分钟
3. 冲突时间自动跳过
4. 无来源内容,禁止生成
[USER]
请基于以下摘要生成议程:
---
记忆_2024-05-10:预算审批因数据缺失延迟,需补充财务报表。
文档_003:超5k预算需CTO审批。
API_日程:张三 6/3 14:00–15:00 不可用。
---
请生成30分钟议程,按优先级排序,每项标注来源。
在后面的内容中,简略使用 Context 来替代 “context+prompt” 的组合,实际指输入给 AI/Agent 的内容。
Context、RAG、Memory 在有限资源下的取舍
原则
Context/RAG/Memory→ 对应可控性 | 可验证性 | (记忆)连续性可控性 | 可验证性 | 连续性→ 先选其二,三者全满必“费钱&费事&费人”- 限制:上下文窗口、语义冲突、延迟成本、合规摩擦
- 三者全部进步,需要技术底层全面革新
每对组合 = 一种系统架构
| 组合 | 核心策略 | 放弃什么 | 适用场景 |
|---|---|---|---|
| 可控 + 可验证 | 严格 Prompt + 白名单 RAG | 长期记忆 | 合规问答、法律/金融审计 |
| 可控 + 记忆 | 策略化摘要回填 + 信任分级 | 极致事实验证 | 个人助理、CRM、项目跟踪 |
| 可验证 + 记忆 | 分层检索 + 冲突打分 + UI 溯源 | 输出精确控制 | 医疗/金融顾问助手 |
其中记忆是“主观历史”,RAG 是“客观事实”,可控是“规则约束”——三者在语义层天然对抗
折中的办法 - 是“逼近”,不是“解决”
分层召回:先记忆,再RAG,择优注入(不全塞)动态摘要:记忆压缩为语义标签,减少 token 消耗,过多反而质量下降(也是一种通胀)可信度引擎:给每条证据打分(来源权威性 + 时间新鲜度 + 用户确认)异步预载:后台缓存高频记忆/文档,不卡用户响应后处理控制:模型输出后,用规则层过滤/重写,保留可控性
所有方案共性:不追求“同时全量”,而追求“智能选择”
产品在一定条件下,实现“可接受解”的路线图
| 阶段 | 优先级 | 动作 |
|---|---|---|
| MVP | 控制 + 可验证 | 无记忆,RAG+模板,100%可审计 |
| 成长期 | 控制 + 记忆 | 可控摘要记忆,禁用自动 RAG 回填 |
| 成熟期 | 可验证 + 记忆 | 多源融合 + 冲突提示 + 用户决策 UI |
永远保留一层策略审计层(极大可能性是类Excel的产品呈现形式) —— 即使选了“可验证+记忆”,也别让模型自由发挥。
Context、RAG、Memory 三元结构
S = (C, R, M)—— 会话上下文、外部证据、长期记忆 ——三者并行检索 → 融合裁剪 → 有痕写回
伪代码表示核心流程和接口
用户提问 → 并行查C/R/M → 按分数和token预算裁剪 → 拼成带来源的prompt → 生成 → 选中结果触发写M(需确认)
retrieve_c() # 会话内最近对话/API结果
retrieve_r(query, k) # 外部知识库:检索
retrieve_m(user, query, k) # 个人记忆:语义/时序双模式
assemble_prompt(context, rag, mem, budget) # 按分数+预算拼prompt(带来源标签)
write_mem(user, item, confirm=False) # 默认需用户确认,否则不写
示例说明 Context/RAG/Memory
客服+产品手册+个人偏好场景
[SYSTEM]
你是一个智能客服助手。回答必须:
- 仅使用下方标注来源的信息
- 无法确认时,回答“根据现有信息无法确定”
- 每个结论后标注来源(如:记忆_3 / 文档_P12)
- 避免重复、避免假设、避免情感化语言
[USER]
用户问题:{user_query}
[CONTEXT]
--- 记忆_1(用户偏好) ---
{user_preference_summary}
--- 文档_P12(产品手册) ---
{doc_snippet_1}
--- 文档_P15(FAQ) ---
{doc_snippet_2}
--- 记忆_5(历史工单) ---
{ticket_summary}
--- (最多再加 1 条 Top-k 检索结果) ---
请按上述信息作答,不要扩展。
回填优先级策略:
- 用户偏好(影响语气/定制)
- 当前问题直接相关文档
- 历史相似工单
- RAG 检索 Top-k(仅当匹配度 > 阈值)