这类问题我们一般称之为“长尾问题”, 如按照 class frequency 排序, 可以将 frequency 较高的 class/label 称之为 head label, frequency 较低的 class/label 称之为tail label.
下图是一个例子:
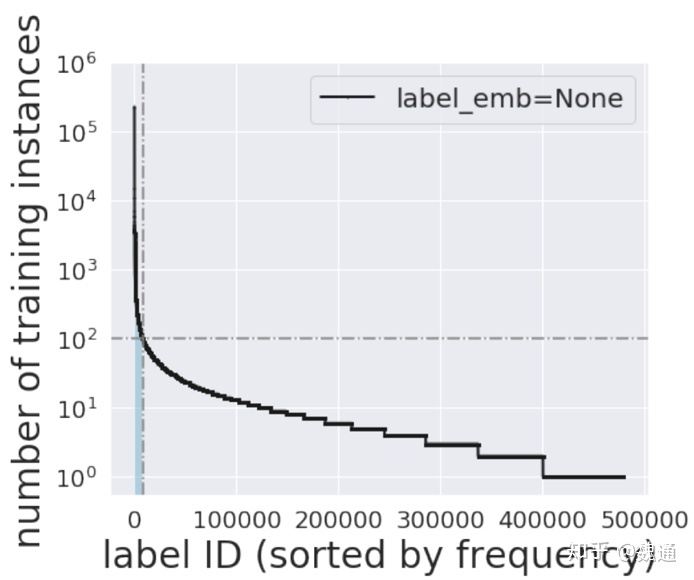
1 - up-sampling 或 down-sampling, 我个人认为在 long tail 的 data 做这两种 sampling 都不是特别好的办法. 由于 tail label 数据非常 scarce, 如果对 head label 做 down-sampling 会丢失绝大部分信息. 同理, 对 tail label 做 up-sampling, 则引入大量冗余数据. 这里有篇文章对比了这两种采样方法: 文章链接.
2 - 第二种方法我称之为 divide-and-conquer, 即将 head label 和 tail label 分别建模. 比如先利用 data-rich 的 head label 训练 deep model, 然后将学到的样本的 representation 迁移到 tail label model, 利用少量 tail label data 做 fine-tune.
3- 对 label 加权, 每个 label 赋予不同的 cost. 如给予 head label 较低的 weight, 而 tail label 则给予较高的 weight, 缺点是每个 label weight 需要启发式的确定. 这里有篇文章对比了这两种采样方法: 文章链接.
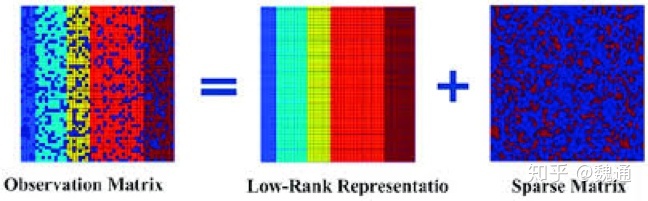
4 - sparse + low rank decomposition: 这种方法可能更适应于 multi-label learning, 学术上常常假设 label matrix 可以分解为 low-rank matrix 和 sparse matrix, 这里的 low-rank matrix 对应 head label, 而 sparse matrix 对应 tail label. 可以参考这篇文章.
最后就是, ensemble 对效果提升具有显著效果.
在实际项目中,还可以考虑以下思路(保持与上文术语一致):
5 - 基于损失的重加权与间隔调节:在交叉熵基础上做 class-balanced 重加权(Effective Number, CB Loss),或使用 LDAM-DRW 为尾类分配更大的间隔;对于检测/多标签任务,常用 Focal Loss/ASL(Asymmetric Loss)抑制易样本与负样本主导。
- 适用场景:分类/检测/多标签任务;
- 代表工作:Class-Balanced Loss (Cui et al., 2019),LDAM-DRW (Cao et al., 2019),Focal Loss (Lin et al., 2017),ASL (Ben-Baruch et al., 2020)。
6 - 先表征、后分类(解耦训练):先用不重加权的损失学习通用表征,再在冻结 backbone 的前提下,仅对 classifier 进行重加权微调(如 τ-normalization、LA/Logit Adjustment)。
- 适用场景:长尾单标签分类;
- 代表工作:Decoupling Representation and Classifier (Kang et al., 2019/2020),Logit Adjustment (Menon et al., 2020)。
7 - 先验/概率校正:在推理阶段按类别先验(频次或估计分布)进行后验校正(如 logit 加偏置);或使用 Balanced Softmax、Post-hoc Calibration 改善置信度与公平性。
- 适用场景:类别后验偏移明显、需要更好校准;
- 代表工作:Balanced Softmax (2020),Temperature Scaling 等校准方法。
8 - 语义/表示层增强与蒸馏:利用 head 类教师模型的知识蒸馏到尾类(或多教师多视图);原型学习(prototypical)与特征正则(如 class-wise center/variance 约束)可稳定尾类表征。
- 适用场景:尾类样本极少、跨域迁移;
- 代表工作:Head-to-Tail Distillation、Prototypical Networks 等。
9 - 多标签与极端多标签(XML)特有方法:面向多标签任务可用分布均衡损失(DB Loss)、ASL/AsL-Focal、负样本筛选;在 XML 场景可用基于 label tree 的方法(如 Parabel/Bonsai),或 propensity-based 重加权与评估。
- 适用场景:多标签/极端多标签;
- 代表工作:Distribution-Balanced Loss (2020),Parabel (2018),Bonsai (2020)。
10 - 数据层与增广:在不破坏语义的前提下做 class-balanced sampling、re-sampling 的“温和版”;MixUp/Manifold MixUp、CutMix、Copy-Paste(检测)等可缓解尾类过拟合;注意与重加权策略的相互作用。
- 适用场景:数据相对充足、希望提升泛化与稳健性;
- 代表工作:MixUp/Manifold MixUp、CutMix、Copy-Paste(检测)。
实用建议(落地侧):
- 指标选择:除总体 Accuracy 外,关注 Macro-F1、Macro-Recall、Mean AP(多标签)、mAP(检测)、各分位数分段指标(Head/Mid/Tail)。
- 验证划分:尽量保证验证/测试集保留长尾结构;必要时报告分布外(OOD)与新类(NCD)表现。
- 训练策略:先表征后调整分类器的“两阶段”做法在多数长尾分类上稳定;多标签任务优先考虑 ASL/DB Loss;检测任务关注 EQL/Seesaw/BAGS。
- 工程权衡:增广与重加权/重采样并用时需小心超参(阈值、比例、温度),避免过度偏置或欠拟合。
参考资料:
- Focal Loss for Dense Object Detection(Lin et al., 2017): https://arxiv.org/abs/1708.02002
- Class-Balanced Loss Based on Effective Number of Samples(Cui et al., 2019): https://arxiv.org/abs/1901.05555
- Learning Imbalanced Datasets with Label-Distribution-Aware Margin Loss(LDAM-DRW, 2019): https://arxiv.org/abs/1906.07413
- Decoupling Representation and Classifier for Long-Tailed Recognition(Kang et al., 2019/2020): https://arxiv.org/abs/1910.09217
- Long-Tail Learning via Logit Adjustment(Menon et al., 2020): https://arxiv.org/abs/2007.07314
- Asymmetric Loss For Multi-Label Classification(Ben-Baruch et al., 2020): https://arxiv.org/abs/2009.14119
- Distribution-Balanced Loss for Multi-Label Long-Tailed Recognition(2020): https://arxiv.org/abs/2007.09654
- Equalization Loss/Seesaw Loss(长尾检测): https://arxiv.org/abs/2003.05176 ,https://arxiv.org/abs/2008.10032
- Parabel/Bonsai(XML): https://arxiv.org/abs/1810.08088 ,https://arxiv.org/abs/2003.04866