所谓的大海捞针实验(The “Needle In a Haystack” test)是设计用来评估LLM RAG系统在不同长短的上下文中的表现。它的工作原理是将特定的、有针对性的信息“针”(“Needle”)嵌入更大、更复杂的文本主体“草垛”(“Haystack”),目标是评估LLMs在大量数据中识别和利用这一特定信息的能力。
通常在RAG系统中,上下文窗口往往是信息溢出的状态,从矢量数据库返回的大量上下文与语言模型、模板和prompt中可能存在的其他内容的指令混杂在一起。大海捞针测试可以评估测试LLMs在这一混乱中找出具体细节的能力。
大海捞针实验的要点是什么?
- 不是所有的LLMs都是相同的,模型可以被以不同的目的和要求来训练得到;
- Prompt的细微差别都可能导致模型间的结果大不相同,一些LLMs需要更有针对性的prompt才能在特定的任务中表现出色;
- 在LLMs基础上构建模型时(尤其是当这些模型与私有数据相连时),有必要在整个开发和部署过程中评估检索和模型性能,看似微不足道的差异可能会导致性能的巨大差异。
如何创建大海捞针实验?
最早的大海捞针实验是被用在评测ChatGPT-4和Claude2.1这两个模型的召回率。其中一段这样的声明被放置在Paul Graham的文章中不同长度的片段的不同深度内:“The best thing to do in San Francisco is eat a sandwich and sit in Dolores Park on a sunny day”,例如:

然后模型会仅根据当前这段上下文内容,来回答“what the best thing to do in San Francisco was”这个问题。然后针对文章的0%(文档顶部)和 100%(文档底部)之间的不同深度中每1K个tokens代表的内容或每个模型的tokens数限制之间的不同上下文长度(GPT-4 为 128k,Claude 2.1 为 200k)重复此操作。下图记录了这两个模型的性能:
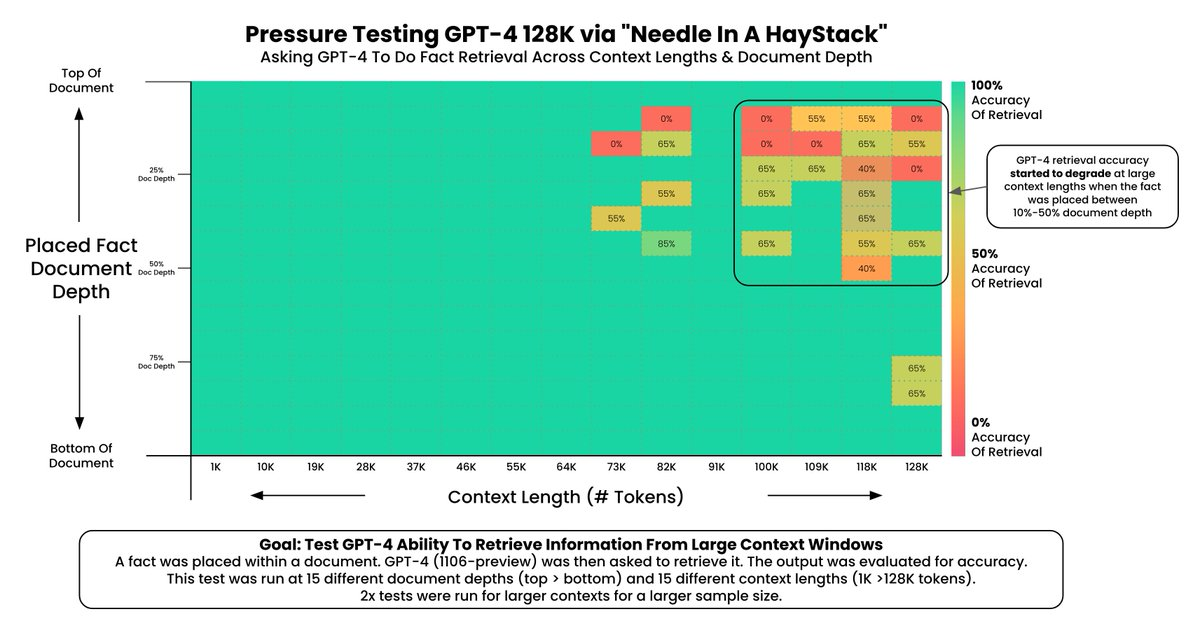
正如所见,ChatGPT 的性能在少于64k个tokens时开始下降,而在100k及以上时急剧下降。有趣的是,如果“针”(needle)位于整段上下文的开头,模型往往会忽略或“忘记”它,而如果它位于结尾或作为第一个句子,模型的性能仍然稳定。

至于Claude,最初的测试并不顺利,最终检索准确率仅为27%。我们也观察到了类似的现象,随着上下文长度的增加,性能会下降,当针头隐藏在文档底部附近时,性能通常会提高,如果针头是上下文的第一句话,则检索准确率为100%。
为了应对这些发现,Claude的作者Anthropic对测试做了一些修改。
首先他们改变了needle,使其更贴近haystack的主题。Claude2.1被训练成“如果文档中没有足够信息来证明答案,则不会回答基于文档的问题”。因此,Claude可能正确地将在Dolores Park吃三明治这件事情确定为在旧金山最值得做的事情。但是这一小段信息可能显得没有太大根据,这会导致Claude给出非常冗长的回答,解释称Claude 无法确认在旧金山吃三明治是最值得做的事情,或者完全忽略这个细节。在重新进行实验时,研究人员发现将needle改成文章中最初提到的一个小细节,可以显著提高结果。
其次,对prompt模版进行了一些调整,在Assistant中加入了一句:”Here is the most relevant sentence in the context: “。可见在模版最后添加的这个改动,指示模型仅返回上下文中提供的最相关句子。与第一个类似,此更改允许我们通过指示模型仅返回一个句子而不是做出断言来规避模型避免未经证实的主张的倾向。
最终这些修改导致Claude的整体检索准确率显著提高:从27%提高到98%。
在实际测试中还有一些修改。使用的needle是一个每次迭代都会改变的随机数,从而消除了缓存的可能性。此外还用了自定义的评估库,可以将测试时间从三天缩短到两小时,并且使用rails直接搜索输出中的随机数,消除任何可能降低检索分数的冗长内容。最后考虑到系统无法检索结果的负面情况,将其标记为无法回答。然后针对这个负面情况进行了单独的测试,以评估系统在无法检索数据时识别能力如何。这些修改使我们能够进行更严格和全面的评估。
得到的实验结果:
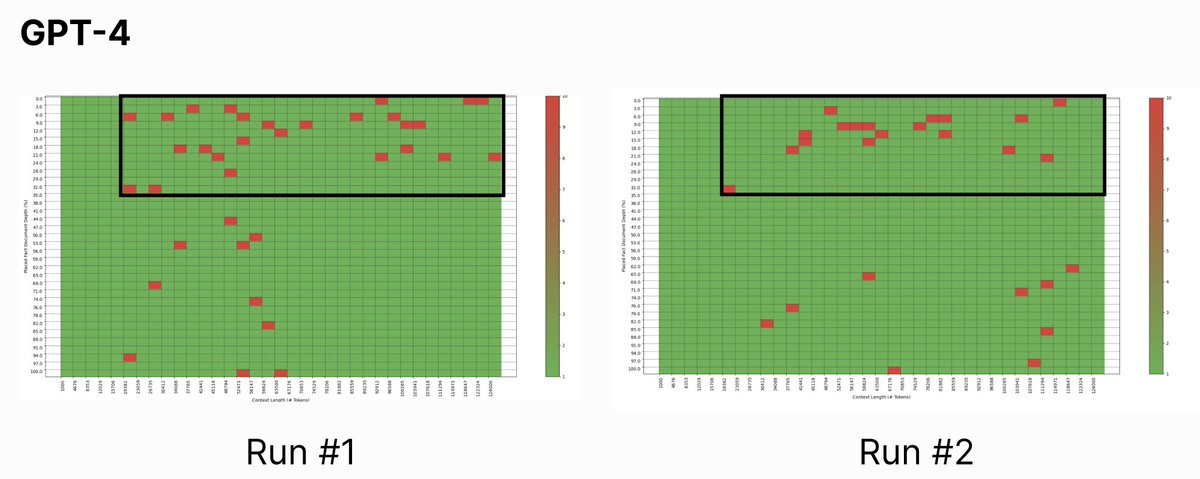
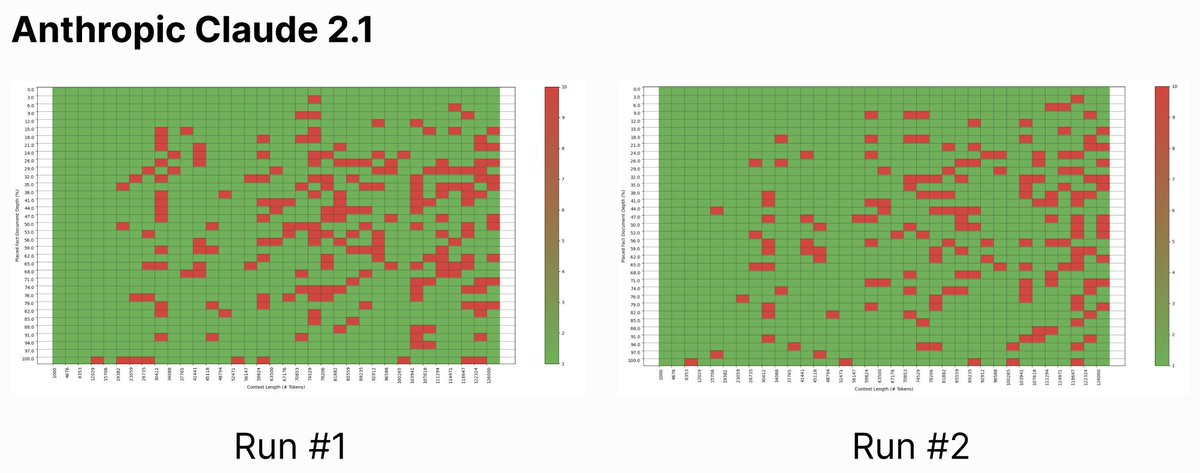
针对ChatGPT和Claude的结果和之前Kamradt的发现差别不大,并且生成的图表看起来相对相似:右上方(长上下文,指针位于上下文开头附近)是 LLM 信息检索出现问题的地方。
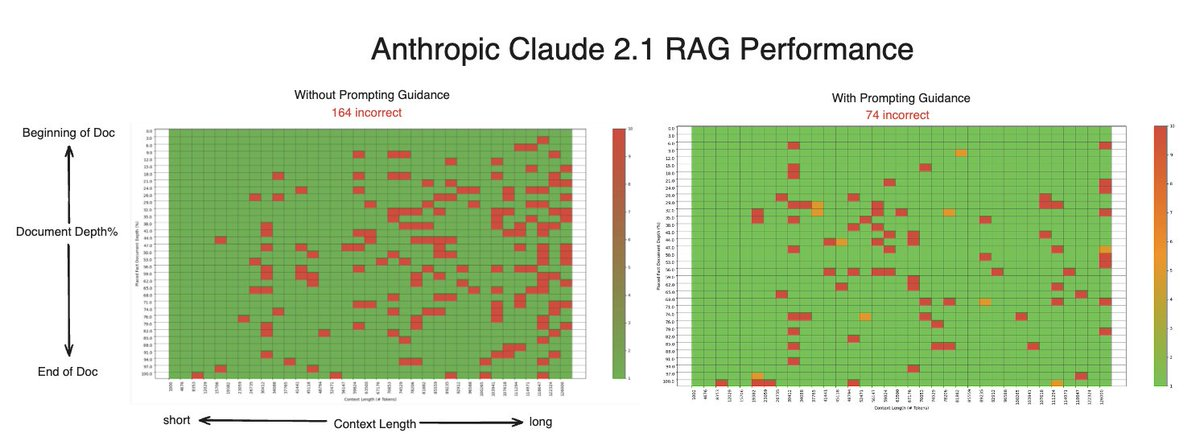
至于带有prompt guidance的Claude 2.1,虽然无法复制Anthropic 98%的检索准确率,但确实看到提示更新后总未命中率显著下降(从165降至74)。这一飞跃是通过在现有prompt末尾添加10个字的说明来实现的,这突显出提示的细微差异可能会对LLMs产生截然不同的结果。
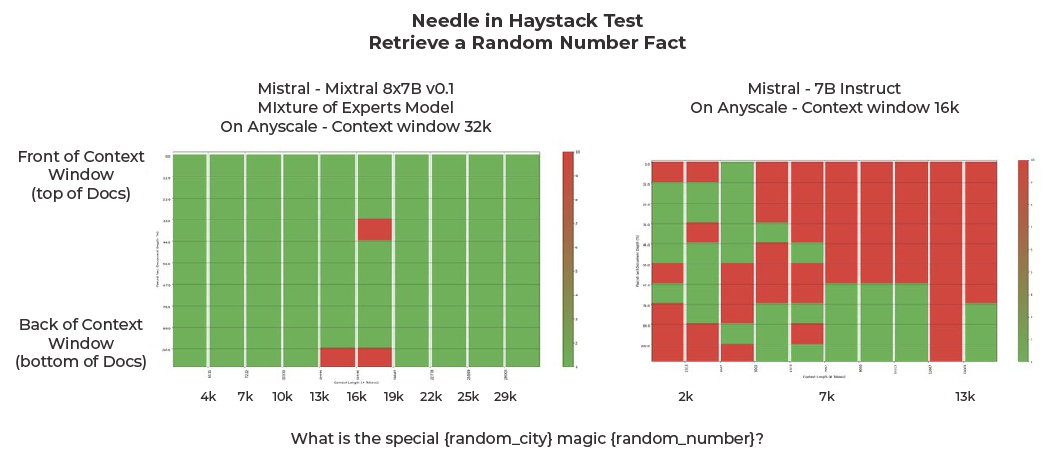
最后但同样重要的一点是,尽管Mixtral是迄今为止测试的最小模型,但有趣的是,它在这个任务中表现得非常出色。MOE模型比7B-Instruct好得多,而且发现MOE在检索评估方面表现更好。
实验设计与评价指标
一个稳定、可复现的“大海捞针”实验,关键在于把“针”与“草垛”的要素设计清楚,并用统一指标刻画模型的提取能力。
- 针(Needle):可被客观判定的短句或短语,最好与语境相关,避免与常识或训练记忆混淆。可采用“随机但语义贴合”的句式,或嵌入唯一标识(hash/数字)。
- 草垛(Haystack):来自同一主题域的长文档或多文档拼接。控制变量包括总长度(如 8k/32k/128k tokens)、针的深度(以文档百分位计)与针出现次数(建议 1 次)。
- 判定标准:
- 严格匹配:对答案做规范化(大小写、空白、标点),判断是否精确命中针的关键片段;
- 语义匹配:用小模型/向量相似做余弦阈值判断,仅在严格匹配不适用时采用,并记录阈值。
- 指标建议:
- 准确率曲线 Acc(depth):不同位置百分位的命中率;
- 长度‑性能曲线 Acc(length):不同上下文长度的命中率;
- 面积指标 AUC(对 depth 的 Acc 积分)作为总体概览;
- 稳健性:按随机种子重复 ≥3 次,报告均值与方差。
实施建议与常见陷阱
为了让实验结论“只反映模型的提针能力”,而非提示词或评审策略的噪声,落地时建议:
- 模板与温度固定:对比不同模型时保持同一提示模板与采样设置(温度/Top‑k/Top‑p),必要时使用贪婪解码以减少随机性。
- 指令对齐:在系统与用户提示中明确“仅基于给定上下文回答”,并提供“无法回答”的出口,避免模型幻觉掩盖提针失败。
- 位置偏置控制:在每个长度档位随机多个深度(如 10%、30%、50%、70%、90%),避免只测“文首/文末”。
- 去缓存与泄漏:针内容需动态生成或至少多样化,避免被模型记忆;禁用外部检索或联网能力。
- 评审一致性:统一答案抽取与匹配规则,优先严格匹配;语义匹配需额外报告阈值敏感性。
与 RAG 评估的结合
在 RAG 场景,失败可能来自“检索不到”或“读不出来”。大海捞针可以自然拆分两段评测:
- 检索层(Retriever):在检索索引中埋针,统计针所在文档被召回的概率(Recall@k);
- 阅读层(Reader/LLM):在“已包含针的上下文”前提下复现本文的提针测试,衡量模型从冗余上下文中抽取关键信息的能力。
通过“召回×提取”分解,可以定位瓶颈:若召回足够但提取差,应优化提示、指令约束或使用“最相关句子”模板;若召回不足,应优化索引、分块与重排序策略(如改良 chunking、BM25+向量融合、学习排序)。
复现实用清单(Checklist)
- 数据:选 1–2 个主题域,准备 8k/32k/128k 三档草垛语料;
- 造针:按域模板生成 50–200 条针,附随机标识,按 5 个深度比例随机插入;
- 模板:提供“仅基于上下文回答/无法回答”的指令,必要时附“Here is the most relevant sentence …”;
- 推理:固定温度与采样,或使用贪婪解码;每档长度×深度×随机种子至少 3 次重复;
- 评审:严格匹配为主,记录 Acc(depth)、Acc(length)、AUC 与方差;
- 报告:附失败样例与定位(是否因位置、长度或模板导致),便于改进。
针对长上下文理解能力的提升
以下简要介绍三个发布于2024年的轻量级训练方法能快速给LLMs解锁长上下文能力。
支持128k上下文的数据工程
- 论文:Data Engineering for Scaling Language Models to 128K Context(2024年2月)
这篇论文认为,在<=4k窗口长度完成预训练的模型,其实就已经基本具备在128k或者更大的上下文窗口进行推理的能力,只需要进行轻量级的继续预训练(e.g. <5B token),就能够解锁这种能力。
而针对继续训练,本文着重切入点在于数据工程。实验基于Llama,数据集基于SlimPajama。提出了几种数据处理策略用于实验对比:
- Cut at 4k:所有数据按4k长度分chunk,不影响领域分布,是llma这类4k预训练模型所采样的方法;
- Cut at 128k:截断长度提升到128k,保留长文本内部信息依赖关系,如LongLoRA就是这么做的;
- Pre-Source Upsampling:在保持各个领域的比例不变的前提下,对长文本进行上采样,提高长文本的比例,在实验中效果最好;
- Global Upsampling:不管领域,直接对长文本进行上采样;
- Upsample Arxiv/ Book/ Github:提高特定领域的数据比例,对长文本进行上采样。
结论:
- 在0-4k长度上,除了Per-source Upsampling以外,各种数据策略都会对模型效果有损害;
- 在一些领域上的提升,并不能很好地迁移到其他领域,比如Book和Github之间就有点跷跷板效应,其中一个效果好了,另一个可能就有损失
- 在4k-128k,Per-source Upsampling在各个领域的效果相对较为平衡(绿色的数量最多)
此外,length upsampling很重要。Per-source Upsampling的策略在领域上可以和源数据保持一致,而提升长文本的比例。
Paraphrasing
- 论文:Training With “Paraphrasing the Original Text” Improves Long-Context Performance(2023年12月)
这篇论文提出了一个叫检索相关度(retrieval relevance)的指标,一个token(或者n-gram)$x$ 的相关度 $R(x)$定义如下:
\[R(x)=\frac{n'}{n}log\frac{N}{N'+1}\]这个指标跟TF-IDF很像,其中$n’$表示$x$在gold-chunk中的频率,而$n$是gold-chunk中的总tokens数目;$N$表示整个上下文中的chunk数目,$N’$是包含$x$的chunk数量。
基于token $x$的检索相关度$R(x)$,定义训练样本$S$的检索相关度如下:
\[\mathcal{R}(S)=\frac{1}{|S_a|}\sum_{x\in S_a}R(x)\]其中$S_a$表示$S$的答案部分。通过$\mathcal{R}(S)$这个指标可以反映出一个训练样本对模型提高检索能力的贡献。$\mathcal{R}(S)$越高,这个样本对提高模型检索能力的贡献越大。
PoSE
- 论文:PoSE: Efficient Context Window Extension of LLMs via Positional Skip-wise Training(2023年9月)
解决RoPE位置旋转编码在长输入文本上效果不好的现象,本文提出Positional Skip-wisE,PoSE,通过在短的训练窗口模拟长距离的位置编码,提升模型处理长上下文的能力。模型可以在2k的训练窗口进行训练,而在128k的长度进行推理。相比直接训练128k模型效率更高。
PoSE提出两个设计原则:
- 模拟所用的位置编码index要覆盖目标长度的范围。如果我们想在128k的窗口进行推理,那就要保证训练的时候,模型从1-128k的位置编码都见过。
- 为了不损害原模型的能力,位置编码应该尽量保持原来预训练的结构,即尽量连续,和保持顺序关系。
PoSE的一个优势是可以在没有任何成本增加的情况下,支持更长的推理长度。比如可以通过简单修改采样策略的参数,PoSE就可以支持到1M,甚至更大的窗口长度,这是其他方法难以做到的。
有了FlashAttention等方案之后,在128k这个长度,我们也有能力在合理的成本下,进行继续预训练,使用5B左右的token解锁模型的长上下文能力。预训练中,长文本对模型的远距离建模能力很重要,要提高长文本的比例才有更好的效果。此外,领域的分布也是一个需要关注的点。在长窗口的微调上,精心设计输入输出形式能带来一些收益。对于更长的窗口,比如M级别这种几乎无法直接训练/微调的长度,PoSE这种模拟的方案能够在不增加成本的情况下,在效果上达到接近直接训练/微调的表现。
结语
“大海捞针”并非只是一张好看的曲线图,它提供了一面镜子,映照出长上下文下模型“能否从噪声中抓住关键句”的本质能力。把实验设计、指标与实现细节打磨扎实,才能让结果真正可比、可解释、可用于优化 RAG 系统与长上下文模型。