图像分割任务是将一张图中的像素按其语义或实例归属加以区分并赋予标签,本质上可视为一种“像素级分类”。分割常见两类:语义分割(Semantic Segmentation)与实例分割(Instance Segmentation)。语义分割为同类目标赋予相同类别;实例分割则需区分同类中的不同实例。深度学习之前,常见方法包括阈值化、直方图、区域生长、K‑均值、分水岭,及更复杂的活动轮廓、图割(Graph‑based)、马尔可夫随机场与稀疏模型等。

基于深度学习的图像分割模型多采用编码器‑解码器(Encoder‑Decoder)结构:编码器提取特征并逐步下采样,将高分辨率低通道的输入映射为低分辨率高通道的特征;解码器逐步上采样恢复空间分辨率并输出分割掩膜。常见技巧包括 skip 连接、多尺度特征融合与空洞卷积(Dilated/Atrous Convolution)。
任务类型与数据集
- 语义分割:Cityscapes、ADE20K、PASCAL VOC、COCO‑Stuff
- 实例/全景分割:COCO、Mapillary、Panoptic‑DeepLab 数据配置
评测指标
- 语义分割:mIoU(mean Intersection over Union)、像素准确率(PA)
- 实例分割:AP(mask AP,按 IoU 阈值分档)
- 全景分割:PQ(Panoptic Quality = SQ × RQ)
常见损失函数
- 交叉熵(Cross‑Entropy)与加权交叉熵(类不平衡)
- Dice/F1 Loss、Tversky/Focal‑Tversky(针对小目标与前景稀疏)
- Focal Loss(难样本重加权)
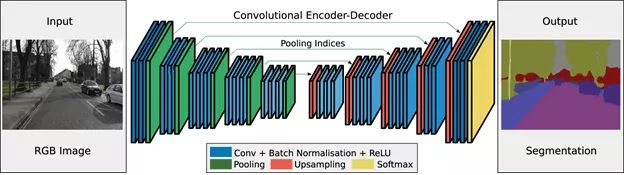
FCN(Fully Convolutional Network)
这是将深度学习应用于图像分割中的一大基石,证明了可以在可变大小的图像上以端到端的方式训练深层网络进行语义分割。FCN模型具有非常可观的有效性和普遍性,然而却存在推理性能较慢,无法有效考虑全局上下文信息,也不容易转换为3D图像。FCN的核心贡献在于:
- 全卷积(convolutional):采样端对端的卷积网络,将普通分类网络的全连接层换上对应的卷积层(FCN)
- 上采样(upsample):即反卷积(deconvolution),恢复图片的位置信息等,反卷积层可以通过最小化误差学习得到。
- 跳跃连接(skip layer):通过连接不同卷积层的输出到反卷积层,来改善上采样很粗糙的问题。
相比于普通 CNN,FCN 允许整张原图直接作为输入且尺寸可变。其去除了分类网络尾部的全连接层(FC),保留空间位置信息,并通过反卷积(上采样)恢复分辨率,输出 C+1 通道的类别概率图(含背景)。
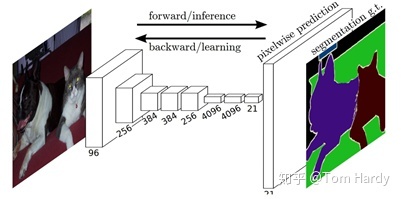
RCNN‑Based Model
RCNN 及其系列(Fast‑RCNN、Faster‑RCNN)将 region proposal 与 CNN 结合,是两阶段(Two‑Stage)目标检测的经典范式。其核心流程:
- 通过 Selective Search 或 RPN 产生候选区域;
- 使用分类/回归头对候选区域进行分类与框回归。
U‑Net

以 U‑Net 为代表的编码‑解码结构相较常见 CNN,会在尾部使用转置卷积(Transpose Conv)或上采样以恢复到输入分辨率(约为 (n_H \times n_W)),并通过多条 skip 连接融合浅层细节与深层语义。转置卷积可视为卷积的“逆过程”,用于高效地进行分辨率提升并保留上下文信息。
在 U‑Net 的下采样路径中,常用卷积与最大池化逐步减小宽高并增加通道;在上采样路径中,使用转置卷积/插值上采样恢复分辨率并减少通道,左右对齐的 skip 连接提供细粒度边界信息。
DeepLab 系列(Atrous + ASPP)
DeepLab 系列通过空洞卷积在不降低感受野的前提下保持较高分辨率特征,并使用多尺度空洞率的 ASPP(Atrous Spatial Pyramid Pooling)聚合上下文。DeepLabv3+ 进一步引入轻量解码器,常在 Cityscapes/ADE20K 上取得领先的 mIoU。早期版本还结合 CRF 精化边界。
PSPNet(Pyramid Pooling Module)
PSPNet 通过金字塔池化在多尺度上全局汇聚上下文,然后与局部特征融合,显著改善大场景与大目标的语义一致性。
实例与全景分割简述
- Mask R‑CNN:在 Faster‑RCNN 的基础上增加 mask 分支,实现实例级掩膜预测。
- Panoptic Segmentation:同时输出“事物(things)”与“背景(stuff)”,指标使用 PQ;可采用 Panoptic‑FPN/Panoptic‑DeepLab 等方法。
训练与工程实践
- 数据与增广:多尺度、随机裁剪/旋转/翻转、颜色抖动;注意类别不平衡与长尾问题(重采样/加权)。
- 优化与正则:AdamW/SGD,余弦退火或 Poly 学习率;SyncBN、Dropout、Label Smoothing(可选)。
- 轻量与实时:MobileNet、BiSeNet、DDRNet 等骨干;蒸馏与量化便于部署。
- 推理:多尺度/左右翻转测试 TTA;部署到 TensorRT/ONNX,关注延迟与显存。
Conclude
如果只关注图像分割,我个人实践中尝试过FCN和UNet两种模型,其核心思想还是有很多类似之处,比如对于反卷积上采样和跳跃连接的应用。但是现在单纯以分割为目的的结构和应用其实是非常少的,因为首先这个领域整体发展就非常缓慢,几乎已经陷入瓶颈期,而且消耗算力较大,而我们工程上往往采取end-to-end的结构,把分割过程融入于目标识别的过程当中。但是其中一些特殊难点方面如小尺寸目标分割、轻量级语义分割、点云分割、实时分割等,仍具有一定挖掘价值。