因为最近看了不少关于 RDD 的介绍与实践,也重读了论文《Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing》(论文链接),于是简单梳理一下关于 RDD 的核心概念、机制与个人理解。
简述
作为Spark最核心的一个组件和概念,RDD的设计理念是在保留例如MapReduce等数据流模型的框架的优点的同时(自动容错、本地优化分配(locality-aware scheduling)和可拓展性),使得用户可以明确地将一部分数据集缓存在内存中,以大大加速对这部分数据之后的查询和计算过程。
RDD可以被认为是提供了一种高度限制(只读、只能由别的RDD变换而来)的共享内存,但是这些限制可以使得自动容错的开支变得很低。RDD使用了一种称之为“血统”的容错机制,即每一个RDD都包含关于它是如何从其他RDD变换过来的以及如何重建某一块数据的信息,这个在后面会进行一下详细的介绍。
现有的数据流系统对两种应用的处理并不高效:一是迭代式算法,这在图应用和机器学习领域很常见;二是交互式数据挖掘工具。这两种情况下,将数据保存在内存中能够极大地提高性能。为了有效地实现容错,RDD提供了一种高度受限的共享内存,即RDD是只读的,并且只能通过其他RDD上的批量操作来创建。尽管如此,RDD仍然足以表示很多类型的计算,包括MapReduce和专用的迭代编程模型(如Pregel)等。我们实现的RDD在迭代计算方面比Hadoop快20多倍,同时还可以在5-7秒内交互式地查询1TB数据集。
其中,为实现这一目的,RDD采取的是粗颗粒度的事件,使得许多不同的操作能够映射到同一个事件上,通过建立一个数据集dataset而不是实际的数据来记录事件。
弹性分布式数据集(RDD)
我们的目标是为基于工作集(working set)的应用(即多个并行操作重用中间结果的这类应用)提供抽象,同时保持MapReduce及其相关模型的优势特性:即自动容错、位置感知性调度和可伸缩性。RDD比数据流模型更易于编程,同时基于工作集的计算也具有良好的描述能力。
在这些特性中,最难实现的是容错性。一般来说,分布式数据集的容错性有两种方式:即数据检查点和记录数据的更新。我们面向的是大规模数据分析,数据检查点操作成本很高:需要通过数据中心的网络连接在机器之间复制庞大的数据集,而网络带宽往往比内存带宽低得多,同时还需要消耗更多的存储资源(在RAM中复制数据可以减少需要缓存的数据量,而存储到磁盘则会拖慢应用程序)。所以,我们选择记录更新的方式。但是,如果更新太多,那么记录更新成本也不低。因此,RDD只支持粗粒度转换(coarse-grained transformation),即在大量记录上执行的单个操作。将创建RDD的一系列转换记录下来(即lineage),以便恢复丢失的分区。
RDD是只读的记录分区的集合。RDD只能通过在——(1)稳定物理存储中的数据集;(2)其他已有的RDD——上执行确定性(deterministic)操作来创建。这些操作称之为转换(transformation),如map, filter, groupBy, join。(转换不是程序员在RDD上执行的操作。)RDD不需要物化。RDD含有如何从其他RDD衍生(即计算)出本RDD的相关信息(即lineage),据此可以从物理存储的数据计算出相应的RDD分区(partition)。
为了进一步理解RDD是一种分布式的内存抽象,表1列出了RDD与分布式共享内存(DSM,distributed shared memory)的对比。在DSM系统中,应用可以向全局地址空间的任意位置进行读写操作。(注意这里的DSM,不仅指传统的共享内存系统,还包括那些通过分布式哈希表或分布式文件系统进行数据共享的系统,比如Piccolo。)DSM是一种通用的抽象,但这种通用性同时也使得在商用集群上实现有效的容错性更加困难。
| 对比项目 | RDD | 分布式共享内存 |
|---|---|---|
| 读 | 批量或细粒度操作 | 细粒度操作 |
| 写 | 批量转换操作 | 细粒度操作 |
| 一致性 | 不重要(RDD是不可更改的) | 取决于应用程序或运行时 |
| 容错性 | 细粒度,低开销(使用lineage) | 需要检查点操作和程序回滚 |
| 落后任务的处理 | 任务备份 | 很难处理 |
| 任务安排 | 基于数据存放的位置自动实现 | 取决于应用程序(通过运行时实现透明性) |
| 如果内存不够 | 与已有的数据流系统类似 | 性能较差(交换?) |
RDD与DSM主要区别在于,不仅可以通过批量转换创建(即“写”)RDD,还可以对任意内存位置读写。也就是说,RDD限制应用执行批量写操作,这样有利于实现有效的容错。特别地,RDD没有检查点开销,因为可以使用lineage来恢复RDD。而且,失效时只需要重新计算丢失的那些RDD分区,可以在不同节点上并行执行,而不需要回滚(roll back)整个程序。
Spark 编程接口
Spark用Scala[5]语言实现了RDD的API。Scala是一种基于JVM的静态类型、函数式、面向对象的语言。我们选择Scala是因为它简洁(特别适合交互式使用)、有效(因为是静态类型)。但是,RDD抽象并不局限于函数式语言,也可以使用其他语言来实现RDD,比如像Hadoop[2]那样用类表示用户函数。
要使用Spark,开发者需要编写一个driver程序,连接到集群以运行Worker,如图2所示。Driver定义了一个或多个RDD,并调用RDD上的动作。Worker是长时间运行的进程,将RDD分区以Java对象的形式缓存在内存中。
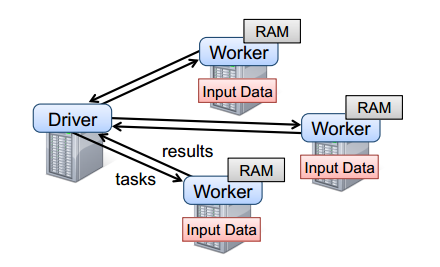
图2 Spark的运行时。用户的driver程序启动多个worker,worker从分布式文件系统中读取数据块,并将计算后的RDD分区缓存在内存中。
再看看2.4中的例子,用户执行RDD操作时会提供参数,比如map传递一个闭包(closure,函数式编程中的概念)。Scala将闭包表示为Java对象,如果传递的参数是闭包,则这些对象被序列化,通过网络传输到其他节点上进行装载。Scala将闭包内的变量保存为Java对象的字段。例如,var x = 5; rdd.map(_ + x) 这段代码将RDD中的每个元素加5。总的来说,Spark的语言集成类似于DryadLINQ。
RDD本身是静态类型对象,由参数指定其元素类型。例如,RDD[int]是一个整型RDD。不过,我们举的例子几乎都省略了这个类型参数,因为Scala支持类型推断。
虽然在概念上使用Scala实现RDD很简单,但还是要处理一些Scala闭包对象的反射问题。如何通过Scala解释器来使用Spark还需要更多工作,这点我们将在第6部分讨论。不管怎样,我们都不需要修改Scala编译器。
以下列出了Spark中的RDD转换和动作。每个操作都给出了标识,其中方括号表示类型参数。前面说过转换是延迟操作,用于定义新的RDD;而动作启动计算操作,并向用户程序返回值或向外部存储写数据。
Transaction
- map(f : T ) U) : RDD[T] ) RDD[U]
- filter(f : T ) Bool) : RDD[T] ) RDD[T]
- flatMap(f : T ) Seq[U]) : RDD[T] ) RDD[U]
- sample(fraction : Float) : RDD[T] ) RDD[T] (Deterministic sampling)
- groupByKey() : RDD[(K, V)] ) RDD[(K, Seq[V])]
- reduceByKey(f : (V; V) ) V) : RDD[(K, V)] ) RDD[(K, V)]
- union() : (RDD[T]; RDD[T]) ) RDD[T]
- join() : (RDD[(K, V)]; RDD[(K, W)]) ) RDD[(K, (V, W))]
- cogroup() : (RDD[(K, V)]; RDD[(K, W)]) ) RDD[(K, (Seq[V], Seq[W]))]
- crossProduct() : (RDD[T]; RDD[U]) ) RDD[(T, U)]
- mapValues(f : V ) W) : RDD[(K, V)] ) RDD[(K, W)] (Preserves partitioning)
- sort(c : Comparator[K]) : RDD[(K, V)] ) RDD[(K, V)]
- partitionBy(p : Partitioner[K]) : RDD[(K, V)] ) RDD[(K, V)]
Action
- count() : RDD[T] ) Long
- collect() : RDD[T] ) Seq[T]
- reduce(f : (T; T) ) T) : RDD[T] ) T
- lookup(k : K) : RDD[(K, V)] ) Seq[V] (On hash/range partitioned RDDs)
- save(path : String) : Outputs RDD to a storage system, e.g., HDFS
RDD描述
我们希望在不修改调度器的前提下,支持RDD上的各种转换操作,同时能够从这些转换获取Lineage信息。为此,我们为RDD设计了一组小型通用的内部接口。
简单地说,每个RDD都包含:(1)一组RDD分区(partition,即数据集的原子组成部分);(2)对父RDD的一组依赖,这些依赖描述了RDD的Lineage;(3)一个函数,即在父RDD上执行何种计算;(4)元数据,描述分区模式和数据存放的位置。例如,一个表示HDFS文件的RDD包含:各个数据块的一个分区,并知道各个数据块放在哪些节点上。而且这个RDD上的map操作结果也具有同样的分区,map函数是在父数据上执行的。下表总结了RDD的内部接口。
- partitions():返回一组Partition对象
- preferredLocations(p):根据数据存放的位置,返回分区p在哪些节点访问更快
- dependencies():返回一组依赖
- iterator(p, parentIters):按照父分区的迭代器,逐个计算分区p的元素
- partitioner():返回RDD是否hash/range分区的元
设计接口的一个关键问题就是,如何表示RDD之间的依赖。我们发现RDD之间的依赖关系可以分为两类,即:(1)窄依赖(narrow dependencies):子RDD的每个分区依赖于常数个父分区(即与数据规模无关);(2)宽依赖(wide dependencies):子RDD的每个分区依赖于所有父RDD分区。例如,map产生窄依赖,而join则是宽依赖(除非父RDD被哈希分区)。另一个例子见图。
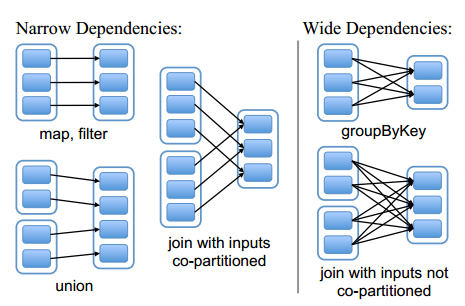
区分这两种依赖很有用。首先,窄依赖允许在一个集群节点上以流水线的方式(pipeline)计算所有父分区。例如,逐个元素地执行map、然后filter操作;而宽依赖则需要首先计算好所有父分区数据,然后在节点之间进行Shuffle,这与MapReduce类似。第二,窄依赖能够更有效地进行失效节点的恢复,即只需重新计算丢失RDD分区的父分区,而且不同节点之间可以并行计算;而对于一个宽依赖关系的Lineage图,单个节点失效可能导致这个RDD的所有祖先丢失部分分区,因而需要整体重新计算。
RDD实现举例
-
HDFS文件:目前为止我们给的例子中输入RDD都是HDFS文件,对这些RDD可以执行:partitions操作返回各个数据块的一个分区(每个Partition对象中保存数据块的偏移),preferredLocations操作返回数据块所在的节点列表,iterator操作对数据块进行读取。
-
map:任何RDD上都可以执行map操作,返回一个MappedRDD对象。该操作传递一个函数参数给map,对父RDD上的记录按照iterator的方式执行这个函数,并返回一组符合条件的父RDD分区及其位置。
-
union:在两个RDD上执行union操作,返回两个父RDD分区的并集。通过相应父RDD上的窄依赖关系计算每个子RDD分区(注意union操作不会过滤重复值,相当于SQL中的UNION ALL)。
-
sample:抽样与映射类似,但是sample操作中,RDD需要存储一个随机数产生器的种子,这样每个分区能够确定哪些父RDD记录被抽样。
-
join:对两个RDD执行join操作可能产生窄依赖(如果这两个RDD拥有相同的哈希分区或范围分区),可能是宽依赖,也可能两种依赖都有(比如一个父RDD有分区,而另一父RDD没有)。
Spark任务调度器
调度器根据RDD的结构信息为每个动作确定有效的执行计划。调度器的接口是runJob函数,参数为RDD及其分区集,和一个RDD分区上的函数。该接口足以表示Spark中的所有动作(即count、collect、save等)。
总的来说,我们的调度器跟Dryad类似,但我们还考虑了哪些RDD分区是缓存在内存中的。调度器根据目标RDD的Lineage图创建一个由stage构成的无回路有向图(DAG)。每个stage内部尽可能多地包含一组具有窄依赖关系的转换,并将它们流水线并行化(pipeline)。stage的边界有两种情况:一是宽依赖上的Shuffle操作;二是已缓存分区,它可以缩短父RDD的计算过程。例如图6。父RDD完成计算后,可以在stage内启动一组任务计算丢失的分区。
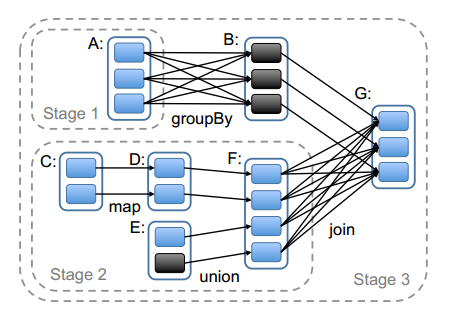
以上Spark怎样划分任务阶段(stage)的例子。实线方框表示RDD,实心矩形表示分区(黑色表示该分区被缓存)。要在RDD G上执行一个动作,调度器根据宽依赖创建一组stage,并在每个stage内部将具有窄依赖的转换流水线化(pipeline)。 本例不用再执行stage 1,因为B已经存在于缓存中了,所以只需要运行2和3。
调度器根据数据存放的位置分配任务,以最小化通信开销。如果某个任务需要处理一个已缓存分区,则直接将任务分配给拥有这个分区的节点。否则,如果需要处理的分区位于多个可能的位置(例如,由HDFS的数据存放位置决定),则将任务分配给这一组节点。
对于宽依赖(例如需要Shuffle的依赖),目前的实现方式是,在拥有父分区的节点上将中间结果物化,简化容错处理,这跟MapReduce中物化map输出很像。
如果某个任务失效,只要stage中的父RDD分区可用,则只需在另一个节点上重新运行这个任务即可。如果某些stage不可用(例如,Shuffle时某个map输出丢失),则需要重新提交这个stage中的所有任务来计算丢失的分区。
最后,lookup动作允许用户从一个哈希或范围分区的RDD上,根据关键字读取一个数据元素。这里有一个设计问题。Driver程序调用lookup时,只需要使用当前调度器接口计算关键字所在的那个分区。当然任务也可以在集群上调用lookup,这时可以将RDD视为一个大的分布式哈希表。这种情况下,任务和被查询的RDD之间的并没有明确的依赖关系(因为worker执行的是lookup),如果所有节点上都没有相应的缓存分区,那么任务需要告诉调度器计算哪些RDD来完成查找操作。
接口更规范示例(不改变原意,仅作格式化参考)
- Transformations(延迟计算,返回新的 RDD):
map[T, U](f: T => U): RDD[T] => RDD[U]filter[T](f: T => Boolean): RDD[T] => RDD[T]flatMap[T, U](f: T => Seq[U]): RDD[T] => RDD[U]sample[T](fraction: Double, withReplacement: Boolean, seed: Long): RDD[T] => RDD[T]groupByKey[K, V](): RDD[(K, V)] => RDD[(K, Iterable[V])]reduceByKey[K, V](f: (V, V) => V): RDD[(K, V)] => RDD[(K, V)]union[T](other: RDD[T]): RDD[T]join[K, V, W](other: RDD[(K, W)]): RDD[(K, (V, W))]cogroup[K, V, W](other: RDD[(K, W)]): RDD[(K, (Iterable[V], Iterable[W]))]cartesian[T, U](other: RDD[U]): RDD[(T, U)]mapValues[K, V, W](f: V => W): RDD[(K, V)] => RDD[(K, W)]sortByKey[K: Ordering, V](ascending: Boolean = true): RDD[(K, V)] => RDD[(K, V)]partitionBy[K, V](p: Partitioner): RDD[(K, V)] => RDD[(K, V)]
- Actions(触发计算,返回结果或进行输出):
count[T](): RDD[T] => Longcollect[T](): RDD[T] => Array[T]reduce[T](f: (T, T) => T): RDD[T] => Tlookup[K, V](k: K): RDD[(K, V)] => Seq[V](仅限哈希/范围分区)saveAsTextFile(path: String)/saveAsObjectFile/saveAsSequenceFile
RDD 容错、缓存与检查点(Checkpoint)
- Lineage:通过记录“如何由父 RDD 推导”来进行故障恢复,重算丢失分区;
- 缓存/持久化:
cache/persist(StorageLevel)可减少重复计算,注意内存不足时的溢写策略与序列化格式(Kryo); - 检查点:对超长 lineage 或需跨作业复用的中间结果落盘(HDFS),降低故障时重算代价;与
persist并用时先持久化再做 checkpoint 可避免重复计算; - 建议:对迭代/交互式作业,优先评估热点 RDD 的存储级别、序列化与分区粒度。
窄/宽依赖与 Shuffle 机制
- 窄依赖可在单节点流水线;宽依赖需 Shuffle,Spark 采用 Sort-Based Shuffle(Tungsten 以后)以降低磁盘文件数与内存峰值;
- 外部 Shuffle 服务(ESS)可在 executor 退出后保留 shuffle 数据,减少失败重试开销;
- Skew 处理:可通过 salting、自定义 partitioner 或 Spark 3 的 AQE(Adaptive Query Execution)自动拆分倾斜分区。
任务调度与推测执行(Speculation)
- 调度层级:
Job -> Stage -> TaskSet -> Task;Stage 边界多由宽依赖决定; - 数据本地性:
PROCESS_LOCAL > NODE_LOCAL > NO_PREF > RACK_LOCAL > ANY;本地性等待时间可调; - 推测执行:对慢 Task 做副本以缩短尾部时延,注意幂等与输出冲突(如输出到相同路径需要原子写)。
内存管理与 Tungsten 引擎
- UMM(Unified Memory Manager)统一管理 execution/storage;
- Tungsten:二进制内存布局、off-heap、代码生成(whole-stage codegen)降低 GC 与提升 CPU 利用。
Spark 3/3.2+ 的关键优化(简述)
- AQE:动态合并小分区、倾斜 join 拆分、重新选择 join 策略;
- 动态分区裁剪(DPP):在 join 期间利用维表过滤事实表扫描;
- 更完善的 GPU 加速生态(Rapids Accelerator for Spark)。
实践建议(工程侧)
- 分区与并行度:保证每个 Task 的处理时间在数十秒级,避免过细/过粗分区;
- I/O:优先列式存储(Parquet/ORC)、合理压缩;
- 序列化:优先 Kryo,并注册常见类型;
- 监控与诊断:使用 Spark UI/History Server,结合事件日志分析 Stage/Task 时间分布与数据倾斜;
- 资源与隔离:YARN/K8s 上合理配置 executor/cores/memory 与 Shuffle 服务,避免 executor 过大引发 GC;
- 容错:关键中间结果 checkpoint;外部 Shuffle 服务与过期策略;
- 参数基线:
spark.sql.adaptive.enabled=true(SQL/AQE 场景),本地性等待、推测执行阈值按集群基线调整。
参考资料
- RDD 论文(NSDI’12):http://www.cs.berkeley.edu/~matei/papers/2012/nsdi_spark.pdf
- Spark 官方文档(RDD/编程指南):https://spark.apache.org/docs/latest/rdd-programming-guide.html
- Spark SQL 与 AQE:https://spark.apache.org/docs/latest/sql-performance-tuning.html
- Sort-Based Shuffle 与 External Shuffle Service 说明:Spark 源码/官方设计笔记
- Rapids Accelerator for Spark(GPU):https://nvidia.github.io/spark-rapids/