2019年时,在NLP领域,以transformer为代表的一系列革新被应用于非监督学习中,并且衍变生成之后大名鼎鼎的BERT和GPT系列模型。而在CV领域,则没有能与之对应的更新。这时候FAIR的Kaiming He团队提出了Moco v1的构想,一举横扫了包括PASCAL VOC和COCO在内的7大数据集,至此,CV拉开了Self-Supervised的新篇章,与Transformer联手成为了深度学习炙手可热的研究方向。
整体而言MoCo主要设计了三个核心操作:Dictionary as a queue、Momentum update和Shuffling BN。
Moco V1 Method
在非监督学习过程当中,避免学习到的内容退化的方法就是要同时满足准确和均匀两方面,通俗来说就是需要positive pair表示特征相近或类似的sampel,negative pair表示特征不同或相远的sample,然后我们的模型不断从这两侧开始学习到真正需要的特征,这些方法也被称为相对学习contrastive learning。
Comparison with relative works
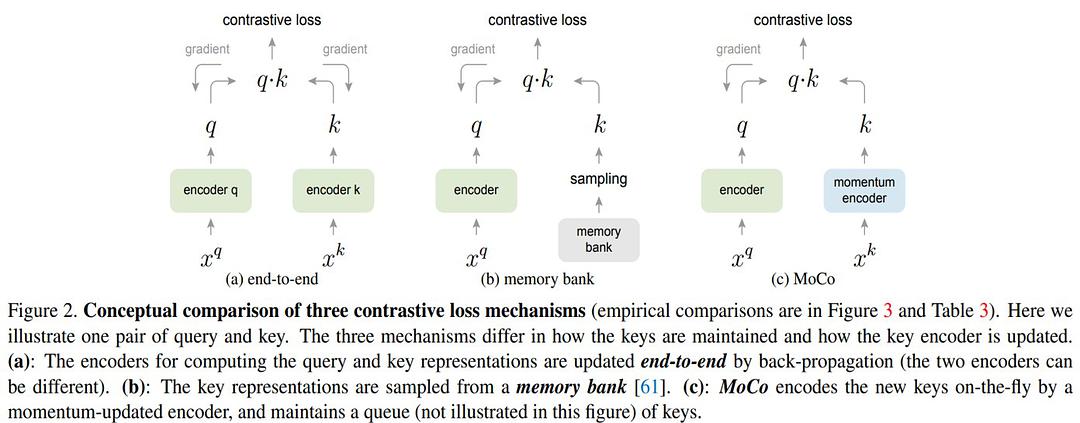
论文中,将现有的Contrastive Learning分为三个类型:
- End-to-end类型,就是一个数据sample,经过不同方法的过滤和增强,生成一组query和key放到两个encoder里,然后算相似程度。如果来自同一个sample,那么我们期望他们的相似程度是高的,而如果来自不同的sample,那么期望他们的相似程度是低的。这种方法对两边的encoder都会做梯度下降的后传递,来不断优化两个encoder,这种方法就跟attention中的机制类似,像是一种左右互搏的方法,它的batch size的大小取决于GPU容量大小。
- Memory Bank类型,跟前一钟不同的在于,锁住一边的key,好像把现在手头datase中获得的所有key都存在一个银行里面,当获得一张新图像的sample时,过encoder得到一个query,就会从memory bank里sampling出一些representations和这个query来做比较,那我们就可以只从query那一侧传递梯度。
- Moco,相对于memory bank的区别就在于加了一个dictionary as queue,也是用于保存key,然后用Momentum update的方法来更新右侧的key encoder,后续会详细讨论。
Detail

Moco的基本原理是我们在一个batch里面的图像,经过多种图像增强的手段,左边这支我们称之为query,右边这支称之为key,它们各自通过一个encoder,只不过key所经过的encoder是一个momentum encoder,然后我们就得到了它们相对应的representations。而对于key所对应的representation而言,它们不光包含了这个mini-batch的key representation,也包含了一些之前处理过的mini-batch中的key representation。这些key representation管理方式是维护了一个队列,相对于之前一些contrastive learning中只在本batch内对key representation做比较的方法而言,moco能用较小的管理开销来获得更多的samples。最后也还是将两个representation之间计算一个相似度,最后得到一个contrastive loss。
Contrastive Loss Function & Momentum Encoder

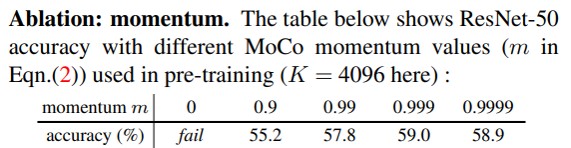
Moco所用的contrastive loss是contrastive learning中非常常见的一种形式,其中分子部分是一个query和它对应的positive key representation的相似程度,分母是query和剩余其他的negative key representation的相似程度的和,各自除以一个temperature系数,用于控制loss的分布。 Momentum Encoder就是当更新了左边query的encoder后,并不是直接就复制到key encoder中使用,而是用一定的比例去更新这个key。这么做的目的是因为不同epoch之间,encoder的参数有可能会发生突变,不能将多个epoch的数据特征近似成一个静止的大batch数据特征,因此就使用了这么一个类似于滑动平均的方法来更新key encoder。
Pseudo Code
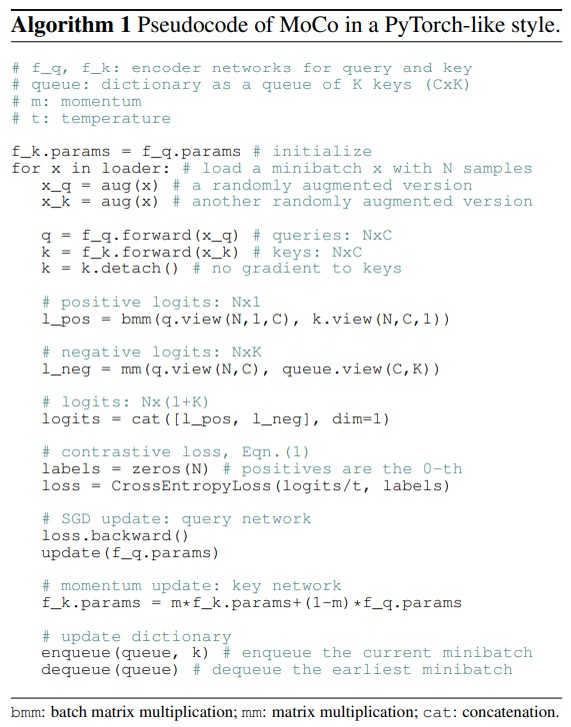
最初的时候,query和key的encoder的参数在初始化的时候是一样的。然后对载入的这一批sample进行操作,对于每一个sample,都进行同样操作的图像增强aug(x)后得到query和key的sample,再分别送到两个encoder里面forward(),因为key是不需要计算梯度的,所有这边有个detach。得到了query和key之后,我们来看对应样本的相似程度,这边先将query和key做了个变形,就是这个注释里的batch matrix multiplication和matrix multiplication,也就是我们query的vector和key对应的vector做内积,得到了positive logits,用query和队列中的key samples进行矩阵乘法,得到了negative logits,最后把这辆个连起来,得到了一个N行K+1列的矩阵,这个矩阵的第一列都是我们的positive sample,后K列都是negative sample的相关程度。然后拿到正负sample的logits做一下交叉熵loss,得到我们需要的对比损失。接着根据损失进行后向传递,通过梯度更新一下query的encoder,然后再用momentun udpdate的方法更新一下key encoder。最后维护一下key的队列,把当前mini-batch的key入队,把队列中最早的key出队。
Shuffling Batch Normalization
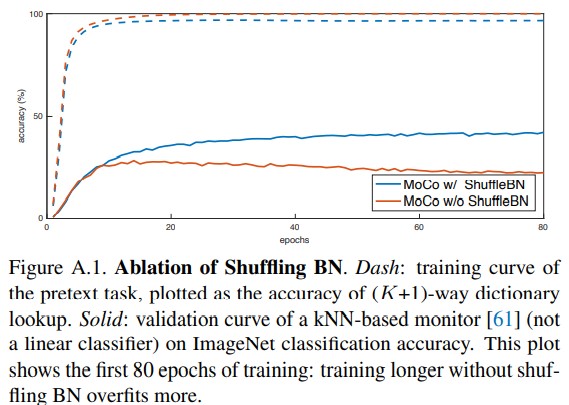
关于BN的过程,作者做了一些有趣的试验,他认为之前的一些方法中的BN其实是会损害无监督的学习,导致模型最后没有学到最优解的representation。其中可能的原因就是模型在做BN的时候,应用到了一个batch中所有样本的信息,在Normalization的过程中,不同样本的信息可能会互相泄露,导致我们的contrastive loss更容易被达成。为了克服这一点,作者就使用了shuffling BN。具体来说就是作者在多块gpu上训练模型,然后在每一块GPU上做BN,但是query和key是打乱顺序送到不同gpu里,也就是说到最后对应的query和key不是从同一个BN里出来的。最后实验结果也证明这个shuffling是有正向效果的。
Result
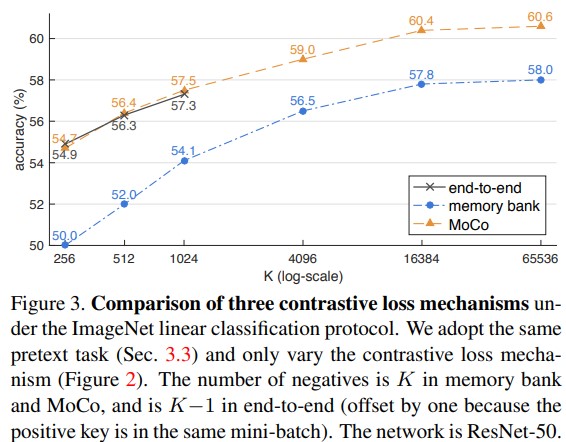
作者比较了三种不同学习器在ImageNet linear Classification上的表现,随着key的negative sample的增加,准确率越来越好,其中moco明显是好于memory bank的表现,而end-to-end模型由于key scale受制于gpu内存大小,因此在横坐标1024处就停止了更新,因为key scale已经限制了它继续向外扩展的可能。
Moco V2
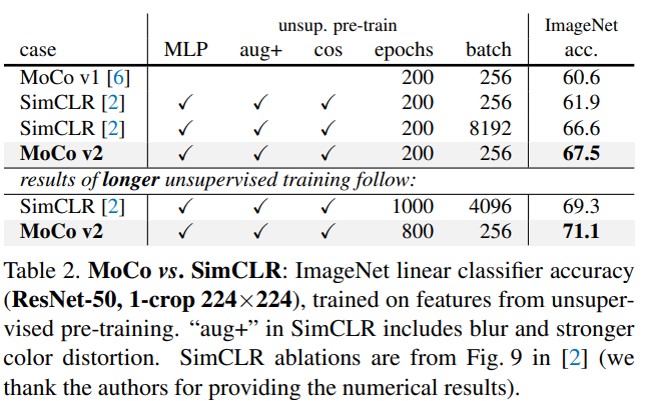
Moco V2全文非常短小,只有两页实际内容,更像是一篇实验报告。诞生的原因是在Moco v1之后,google也发了一个自己的cv上非监督学习方法,叫SimCLR,其本质还是一个end-to-end的结构,之前我们说到这种结构的缺陷在于算力要求大,key数量受限于GPU内存。但是财大气粗的google不管这个,直接拿成捆的TPU堆上去,活生生拿计算资源优势抹平了这个缺陷,然后取得了比Moco v1要好的成绩。
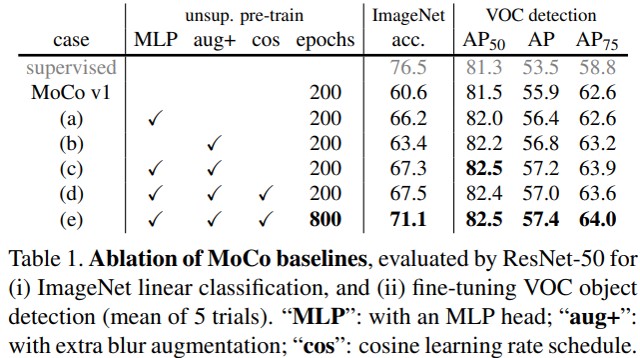
主要的措施可以看上图这个表格,v2在v1的基础上,先是加了多层感知机MLP,效果提升了很多,然后加了数据增强,也提升了一些,最后增加了一些epoch,也获得了一些提升。最后还得出了结论,在更小的batch size下,能够获得比SimCLR更好的表现,算是宣布了自己的胜利。