Mixture of Experts (MoE)架构是一种先进的机器学习模型设计,特别适用于大语言模型(LLM)。在MoE架构中,整个模型被划分为多个专门的子网络(称为“专家Experts”),每个专家针对特定类型的数据或任务进行训练。通过一个门控网络,MoE能够动态选择和激活与输入数据最相关的专家,从而实现稀疏计算。这种方法使得在处理复杂任务时,模型能够显著减少计算成本,同时提高性能和效率。
模型规模是提升模型性能的关键因素之一。在有限的计算资源预算下,用更少的训练步数训练一个更大的模型,往往比用更多的步数训练一个较小的模型效果更佳。
为什么是 MoE
在大语言模型中,MoE架构的优势尤为明显。它允许模型在保持较大参数规模的同时,仅激活部分专家进行计算,从而降低了预训练和推理阶段的计算需求。例如,在某些实现中,MoE可以在一次前向传播中仅激活少数几个专家,这样可以在不牺牲性能的情况下,显著提高计算效率和响应速度。这使得MoE成为处理自然语言处理等领域中多样化数据和高计算需求任务的重要工具。
现有MOE模型汇总
注:下表中带“需核实”的条目表示公开资料不足或厂商未披露完整细节,仅作参考。
| 模型 | 发布 | 规模 | 训练 | 备注 |
|---|---|---|---|---|
| Deepseek | DeepSeek于2024年12月10日发布并持续更新 | 16B (激活2.4B)、236B (激活22B) | 未披露 | 当前最优秀的MoE系列大模型之一 |
| Qwen2.5-54B-A14B | Alibaba于2024年5月发布 | 54B (激活14B) | 包含大规模文本与代码数据 (包含中文和英文数据),采用MOE与密集层结合 | 针对聊天生成任务进行了优化,适合多种应用场景。(HF地址里写的是57B, 需要核实是否为笔误) |
| Mixtral | Mistral AI于2024年1月发布 | 46.7B (8*7B) | 采用稀疏MoE架构 | 8个专家,每次选择2个。 |
| Arctic | Snowflake于2024年4月发布 | 480B (128x3.66B 激活17B) | 动态数据课程,包含代码、文本等数据,强调数据质量和多样性。包含密集MoE混合变换器架构,使用1000张GPU,训练时间约3周 | 开源模型,性能指标与其他LLM相当。 |
| DBRX | Databricks于2024年3月发布 | 132B (36B活跃参数) | 12T文本和代码数据,强调代码数据质量和多样性,包含多种编程语言。包含精细化MoE架构。训练使用3072张H100,约3个月时间,包括了pretraining, post-training, evaluation, red-teaming, and refining | 16个专家,每次选择4个。在多个基准测试中表现优越,尤其在编程任务上超越GPT-3.5。 |
| Grok-1 | xAI于2023年11月发布 | 推测数十亿参数量(未公开) | 可能包含大量社交媒体数据(X 平台)。推测使用 Transformer 架构 | 与 X 平台深度整合;细节未公开(需核实) |
| Grok-2 | xAI于2024年8月发布 | 未知(未公开) | 据称包含多模态数据与改进 MoE 架构 | 官方未披露技术细节(需核实) |
| Grok-3 | xAI于2025年2月18日发布 | 未知(未公开) | 据称使用大规模 GPU 训练 | 官方未披露技术细节(需核实) |
| OLMoE | Allenai于2024年9月24日发布 | 7B(1B激活参数) | 包含大规模英文语料,尝试了对现有MoE算法的改进,并第一次将这个规模的MoE模型在5T tokens的语料上进行训练。使用 256 个 H100 GPU,通过 GPU 间的 NVlink 连接和节点间的InfiniBand 互连,大约进行 10 天的训练。 | 同等规模下最好的MoE模型 |
架构与术语
专家位置与路由粒度
- 专家位置:以 FFN‑only MoE 为主(将 Transformer 的 FFN 层替换为专家层);也有 Attention‑MoE/混合层设计(需谨慎评估通信与稳定性)。
- 路由粒度:token‑wise(常见)、feature‑wise(研究中)、sequence/block‑wise(工程化更复杂)。
- Top‑K:Top‑1(如 Switch Transformer)与 Top‑2(如 Mixtral/GLaM)的权衡:负载均衡、通信开销、表达力。
- 容量(capacity factor):控制每位专家可接收的 token 上限,影响溢出率与显存/通信峰值。
术语统一
- Experts/Router/Combiner:专家/门控网络/输出组合。
- Dropping vs Dropless:是否允许溢出 token 被丢弃;dropless 更稳定但更吃带宽与显存。
- EP/TP/PP/DP:Expert Parallel / Tensor Parallel / Pipeline Parallel / Data Parallel。
MOE的基本组成
- 专家(Experts) 混合专家模型 (MoE) 的理念起源于 1991 年的论文 Adaptive Mixture of Local Experts。这个概念与集成学习方法相似,旨在为由多个单独网络组成的系统建立一个监管机制。在这种系统中,每个网络 (被称为“专家”) 处理训练样本的不同子集,专注于输入空间的特定区域。那么,如何选择哪个专家来处理特定的输入呢?这就是门控网络发挥作用的地方,它决定了分配给每个专家的权重。在训练过程中,这些专家和门控网络都同时接受训练,以优化它们的性能和决策能力。
在 2010 至 2015 年间,两个独立的研究领域为混合专家模型 (MoE) 的后续发展做出了显著贡献:
- 组件专家: 在传统的 MoE 设置中,整个系统由一个门控网络和多个专家组成。在支持向量机 (SVMs) 、高斯过程和其他方法的研究中,MoE 通常被视为整个模型的一部分。然而,Eigen、Ranzato 和 Ilya 的研究 探索了将 MoE 作为更深层网络的一个组件。这种方法允许将 MoE 嵌入到多层网络中的某一层,使得模型既大又高效。
- 条件计算: 传统的神经网络通过每一层处理所有输入数据。在这一时期,Yoshua Bengio 等研究人员开始探索基于输入令牌动态激活或停用网络组件的方法。
这些研究的融合促进了在自然语言处理 (NLP) 领域对混合专家模型的探索。特别是在 2017 年,Shazeer 等人 (团队包括 Geoffrey Hinton 和 Jeff Dean,后者有时被戏称为 “谷歌的 Chuck Norris”) 将这一概念应用于 137B 的 LSTM (当时被广泛应用于 NLP 的架构,由 Schmidhuber 提出)。通过引入稀疏性,这项工作在保持极高规模的同时实现了快速的推理速度。这项工作主要集中在翻译领域,但面临着如高通信成本和训练不稳定性等多种挑战。
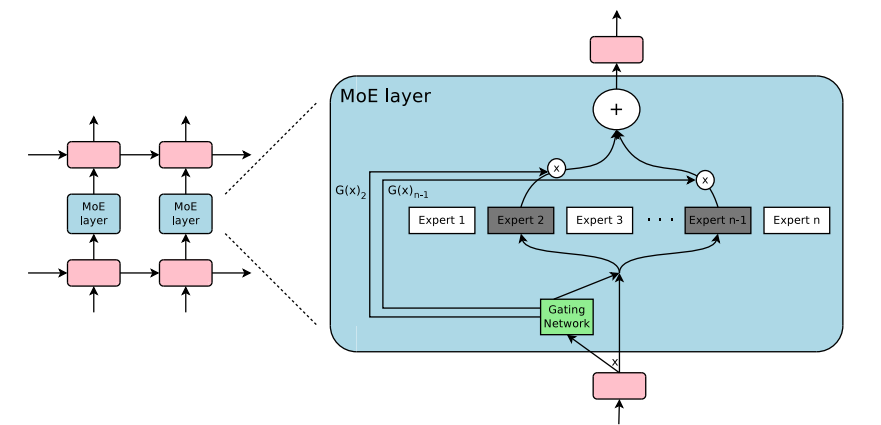
混合专家模型 (MoE) 的引入使得训练具有数千亿甚至万亿参数的模型成为可能,如开源的 1.6 万亿参数的 Switch Transformers 等。这种技术不仅在自然语言处理 (NLP) 领域得到了广泛应用,也开始在计算机视觉领域进行探索。然而,本篇博客文章将主要聚焦于自然语言处理领域的应用和探讨。
- 门控网络(Gating Network)
这个部分用于决定哪些令牌 (token) 被发送到哪个专家。例如,在下图中,“More”这个令牌可能被发送到第二个专家,而“Parameters”这个令牌被发送到第一个专家。有时,一个令牌甚至可以被发送到多个专家。令牌的路由方式是 MoE 使用中的一个关键点,因为路由器由学习的参数组成,并且与网络的其他部分一同进行预训练。
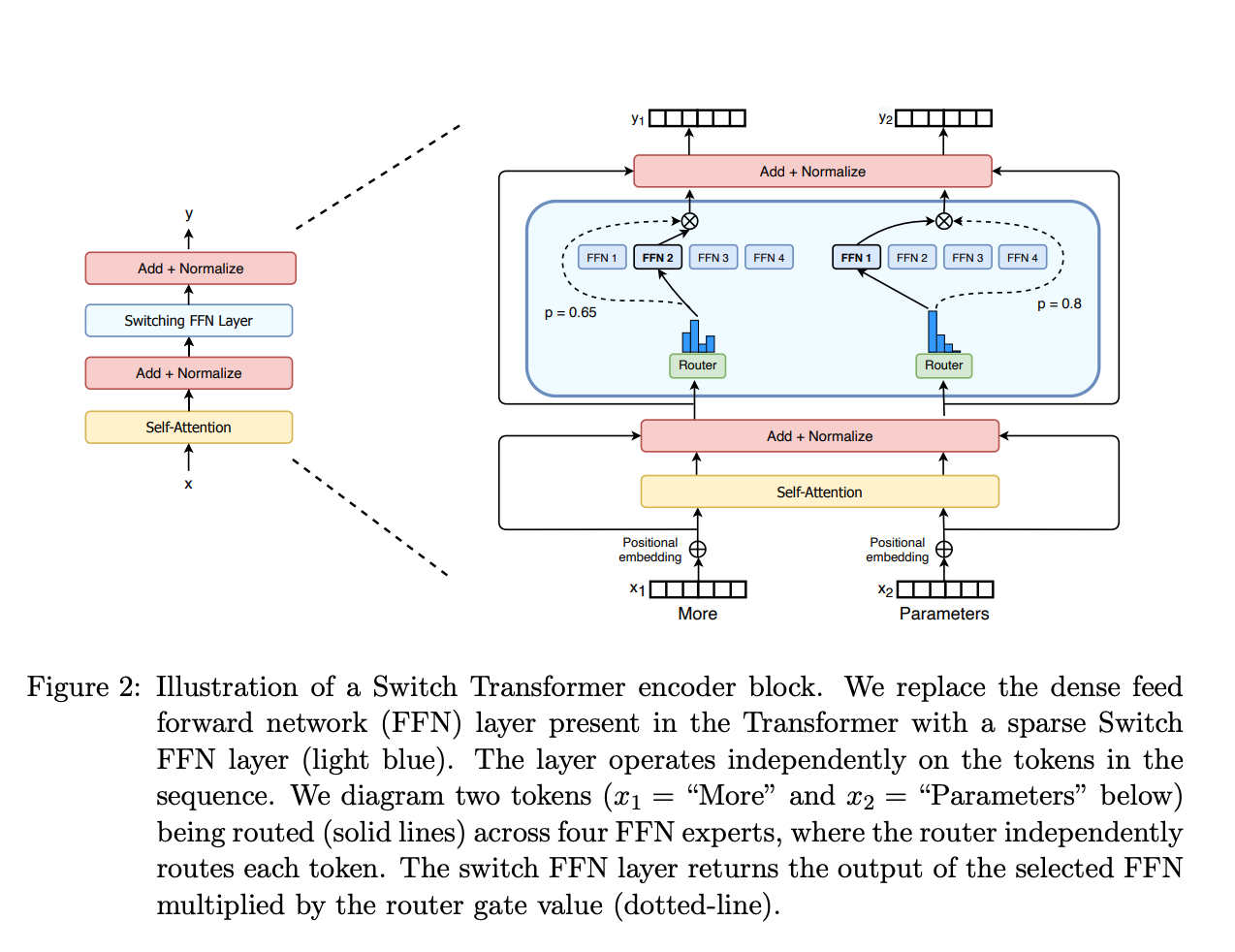
总结来说,在混合专家模型 (MoE) 中,我们将传统 Transformer 模型中的每个前馈网络 (FFN) 层替换为 MoE 层,其中 MoE 层由两个核心部分组成: 一个门控网络和若干数量的专家。门控网络决定了哪些令牌被发送到哪个专家,而专家则负责处理这些令牌。这种方法的引入使得模型能够在保持极高规模的同时实现快速的推理速度。
- 输出组合机制(Combiner)
一般来说,组合器将所有专家模型的输出进行加权融合。
并行与系统
在工程实践里,MoE 的性能上限常由“通信与放置”而非“算力”决定。可以把并行理解为四个层级的协作:专家并行(EP)负责把专家横向切开,张量并行(TP)把单个算子再细分,流水并行(PP)按层级切分网络,数据并行(DP)在最外层复制模型与数据。一般做法是“EP+TP/PP 在内、DP 在外”,既保证专家路由的可扩展,也兼顾总体吞吐。
一次前向的通信路径(直觉版)
1) 路由与分桶:Router 计算每个 token 的 Top‑K 专家,按专家 ID 把 token 重新分桶(bucketing)。 2) AllToAll:各 GPU 交换属于彼此专家的 token(这一步往往是瓶颈,链路越好越有利,如 NVLink/NVSwitch > PCIe > 跨机 RDMA)。 3) 专家计算:每个 GPU 上的本地专家并行执行 FFN;若还叠加了 TP,则每个专家的矩阵乘也被进一步切分。 4) 组合与回传:各 GPU 将专家输出按原序拼回,并通过 Combiner 聚合。可把 AllToAll 与计算分块交错,以重叠通信与计算。
容量与放置的经验法则
- capacity factor(如 1.2–1.5)决定专家能接纳的 token 峰值。过小会频繁溢出、过大则放大显存与 AllToAll 压力。小批次宜适当上调 capacity 以降低随机不均;大批次可略收紧以控显存。
- 专家亲和(affinity):固定专家→设备的映射,避免训练中频繁迁移;把“热门专家”优先放在互联更好的 GPU 上。
- 拓扑感知:单机优先 NVLink/NVSwitch 直连对;多机优先 IB/RDMA 并尽量让通信域与专家分组一致,减少跨交换芯片跳数。
不同规模下的常见策略
- 单机单卡:无需 EP,小规模验证可直接用 Top‑1/Top‑2 路由与 dropless 训练,专注稳定性。
- 单机多卡:启用 EP;若还有大型层,可叠加 TP;AllToAll 基本依赖 NVLink/NVSwitch,通信‑计算重叠收益明显。
- 多机多卡:EP+DP 为主,必要时叠加 TP/PP。跨机 AllToAll 成本高,建议增大微批、分块交换、减少不必要的激活回传。
工具链与实现选择
- Megatron‑Core/Megatron‑LM、DeepSpeed‑MoE、Fairseq‑MoE 在 EP 与通信调度上各有实现差异,均可与 ZeRO‑3 的参数/梯度/优化器分片协同使用。
- 诊断与优化:用 Nsight Systems/Compute 观察通信‑计算时间线;
NCCL_DEBUG=INFO与nccl-tests校验带宽与拓扑;根据火焰图定位 AllToAll 热点,再决定是否分块、分桶、或调整专家数与 capacity。
一句话记忆:把“专家”放在带宽好的地方,把“通信”藏到计算背后。
训练配方与稳定性
- 学习率/权重衰减/梯度裁剪:给出 MoE 常见区间与与密集模型的差异偏好(如更强正则)。
- 负载均衡:aux loss、z‑loss、温度/噪声 schedule;从 dropping 逐步过渡到 dropless 的策略。
- 路由初始化与早期稳定:均匀初始化、warmup、路由温度退火、容量 factor 曲线。
推理与部署
- 动态路由工程化:批内路由冲突、KV Cache 跨专家;连续批处理(continuous batching)与延迟/吞吐权衡。
- 专家放置与亲和:冷热专家、固定映射,跨节点路由代价;MoE 与张量并行共存限制。
- 量化与蒸馏:MoE‑aware 的量化策略;从稀疏蒸馏到稠密的知识转移。
评测与数据
- 数据构成:多域/多语/代码对专家专化的影响与偏置;数据均衡与去重。
- 指标体系:任务指标 + 效率指标(TFLOPs、有用算力占比、通信占比)+ 稳定性指标(负载均衡、溢出率)。
- 公开基线:提供一组可复现实验配置(N_experts、Top‑K、capacity、EP 并行度)。
常见问题与排错
- 症状 → 成因 → 对策:热门专家过载/负载失衡/溢出严重/训练发散/通信瓶颈/显存爆。
- 定位顺序:先看路由统计与溢出,再看通信火焰图,最后做算子级 Profile。
参考与延伸阅读
- Switch Transformer、GShard/GLaM、BASE Layers、Mixtral 8×7B。
- DeepSpeed‑MoE、Megatron‑LM/Core MoE、Fairseq‑MoE。
- OLMoE、Llama‑MoE 等开源实现与报告。
路由与正则化
- 条件计算与稀疏激活
稀疏性的概念采用了条件计算的思想。在传统的稠密模型中,所有的参数都会对所有输入数据进行处理。相比之下,稀疏性允许我们仅针对整个系统的某些特定部分执行计算。这意味着并非所有参数都会在处理每个输入时被激活或使用,而是根据输入的特定特征或需求,只有部分参数集合被调用和运行。
让我们深入分析 Shazeer 对混合专家模型 (MoE) 在翻译应用中的贡献。条件计算的概念 (即仅在每个样本的基础上激活网络的不同部分) 使得在不增加额外计算负担的情况下扩展模型规模成为可能。这一策略在每个 MoE 层中实现了数以千计甚至更多的专家的有效利用。
这种稀疏性设置确实带来了一些挑战。例如,在 MoE 中,尽管较大的批量大小通常有利于提高性能,但当数据通过激活的专家时,实际的批量大小可能会减少。比如,假设我们的输入批量包含 10 个令牌, 可能会有五个令牌被路由到同一个专家,而剩下的五个令牌分别被路由到不同的专家。这导致了批量大小的不均匀分配和资源利用效率不高的问题。下面补充稳定训练常用的正则与损失。
那我们应该如何解决这个问题呢?一个可学习的门控网络 (G) 决定将输入的哪一部分发送给哪些专家 (E):
\[y = \sum_{i=1}^{n} G(x)_i E_i(x)\]在这种设置下,虽然所有专家都会对所有输入进行运算,但通过门控网络的输出进行加权乘法操作。但是,如果 G(门控网络的输出)为 0 会发生什么呢?如果是这种情况,就没有必要计算相应的专家操作,因此我们可以节省计算资源。那么一个典型的门控函数是什么呢?一个典型的门控函数通常是一个带有 softmax 函数的简单的网络。这个网络将学习将输入发送给哪个专家。
\[G_\sigma(x) = Softmax(x \cdot W_g)\]Shazeer 等人的工作还探索了其他的门控机制,其中包括带噪声的 TopK 门控 (Noisy Top-K Gating)。这种门控方法引入了一些可调整的噪声,然后保留前 k 个值。具体来说:
- 添加一些噪声 \(H(x)_i=(x \cdot W_g)_i + StandardNormal() \cdot Softplus((x \cdot W_{noise})_i)\)
- 选择保留前k个值 \(KeepTopK(v, k)_i = \begin{cases} v_i, & \text{if $v_i$ is in the top $k$ elements of $v$} \\ -\infty, & \text{Otherwise} \end{cases}\)
- 应用softmax函数 \(G(x)=Softmax(KeepTopK(H(x), k))\)
这种稀疏性引入了一些有趣的特性。通过使用较低的 k 值(例如 1 或 2),我们可以比激活多个专家时更快地进行训练和推理。为什么不仅选择最顶尖的专家呢?最初的假设是,需要将输入路由到不止一个专家,以便门控学会如何进行有效的路由选择,因此至少需要选择两个专家。Switch Transformer 在这方面有更多研究。
我们为什么要添加噪声呢?这是为了专家间的负载均衡!
负载均衡与正则
- 负载均衡损失(aux loss):鼓励路由概率与实际 token 落地分布更均匀,缓解热门专家过载。
- Router z-loss:约束路由 logits 的尺度,防止极端自信导致的过拟合与不稳定。
- 熵正则/温度 schedule:提高路由探索性,训练早期配合温度退火;Noisy Top‑K 的噪声强度随训练逐步降低。
-
容量与溢出:合理设置 capacity factor;溢出 token 策略(随机丢弃/最小负载回填/回退默认专家)。
- 混合专家模型中token的负载均衡
正如之前讨论的,如果所有的令牌都被发送到只有少数几个受欢迎的专家,那么训练效率将会降低。在通常的混合专家模型 (MoE) 训练中,门控网络往往倾向于主要激活相同的几个专家。这种情况可能会自我加强,因为受欢迎的专家训练得更快,因此它们更容易被选择。为了缓解这个问题,引入了一个 辅助损失,旨在鼓励给予所有专家相同的重要性。这个损失确保所有专家接收到大致相等数量的训练样本,从而平衡了专家之间的选择。接下来的部分还将探讨专家容量的概念,它引入了一个关于专家可以处理多少令牌的阈值。在 transformers 库中,可以通过 aux_loss 参数来控制辅助损失。
结语:从原理到实践
MoE 的核心是“稀疏激活”:通过门控将每个 token 路由到少量专家,在不显著增加 FLOPs 的前提下扩大有效参数量,进而提升模型上限。围绕这一点,路由策略(Top‑K、容量因子)和正则化(负载均衡损失、z‑loss、温度/噪声调度)决定了训练是否稳定、专家是否各司其职。专家自身多为 FFN 变体,但其规模、数量和分组会直接影响到通信与显存的压力。
真正把 MoE 跑“好”的关键在系统层:一次前向/反向的主瓶颈往往是 AllToAll 带来的跨设备数据交换,而不是算子本身的算力。工程上通常采用“EP 为核心、TP/PP 补强、DP 套外层”的并行组合,并以拓扑感知的放置策略减少跨交换芯片或跨机通信的代价。配合分桶/分块与通信‑计算重叠,才能把带宽压力藏到计算背后。
训练与推理阶段的关注点有所不同:训练更看重负载均衡、收敛稳定与显存/带宽占用;推理则强调路由一致性、KV Cache 管理与专家放置的亲和性。评测也应既看任务指标,也看效率与稳定性指标(如通信占比、溢出率),并结合数据配方来理解专家“专化”的来源与边界。
一句话总结:MoE 让参数规模与有效算力解耦,但要把潜力兑现,既要在路由与正则上“管好专家”,也要在并行与拓扑上“摆好专家”。