在探讨GPU如何工作之前,我们首先要回答一个更根本的问题:为什么AI的发展离不开GPU?
答案的核心在于AI,尤其是深度学习,其本质是大规模的矩阵和向量运算。无论是训练一个复杂的神经网络,还是运行一个大语言模型(LLM)进行推理,其底层都涉及海量的、可以被分解为独立部分的数学计算。例如,在神经网络的前向传播中,每一层的输出都是由前一层的输入与权重矩阵相乘,再加上偏置向量得到的。这个过程需要对成千上万个数字进行重复的、模式相同的乘法和加法运算。
这种计算任务的特点是:计算量巨大,但逻辑简单且高度并行。这正是GPU大显身手的舞台。GPU的设计初衷是为了处理图形渲染,而图形渲染本身也是一种高度并行的任务——屏幕上的每个像素点都可以被独立计算。这种为并行而生的架构,恰好与AI的算力需求不谋而合。因此,当我们谈论AI Infra时,GPU便成为了绕不开的基石。
一、 CPU vs. GPU:不同的设计哲学
要理解GPU,最好的方式就是将它与我们更熟悉的CPU(中央处理器)进行对比。它们虽然都是处理器,但设计理念却截然不同,这决定了它们各自擅长的领域。
CPU:精于串行的“瑞士军刀”
CPU被设计成一个通用的、能够处理各种复杂任务的“多面手”。它的核心特点是:
- 少数强大的核心:一个典型的CPU通常只有几个到几十个核心。
- 复杂的控制逻辑:每个核心都配备了复杂的控制单元、分支预测器和大量的缓存,使其能够快速处理各种复杂的指令和逻辑判断。
- 高时钟频率:CPU追求单个任务的极致执行速度。
你可以把一个CPU核心想象成一位经验丰富、能力全面的老教授。他能处理各种疑难杂症,无论是复杂的逻辑推理还是精密的计算,都能应对自如。但他的精力有限,无法同时处理成千上万个简单问题。因此,CPU非常适合处理操作系统、应用程序等需要复杂逻辑判断和串行执行的任务。
GPU:擅长并行的“人海战术”
与CPU不同,GPU的设计目标非常专一:大规模并行计算。它的核心特点是:
- 成千上万的简单核心:一块GPU芯片上集成了数千个甚至更多的计算核心(如NVIDIA的CUDA核心)。
- 简化的控制逻辑:每个核心的控制逻辑和缓存都非常简单,它们被设计用来高效地执行同一条指令。
- 高内存带宽:为了同时喂饱成千上万个核心,GPU配备了高带宽内存(HBM),确保数据能够被快速地传输。
你可以把GPU想象成一个由成千上万名小学生组成的计算方阵。虽然每个小学生的计算能力有限,也无法处理复杂的逻辑问题,但当你给他们下达一个简单的、统一的计算任务时(比如“所有人都计算1+1”),他们能以惊人的速度同时完成成千上万次计算。这正是深度学习所需要的。
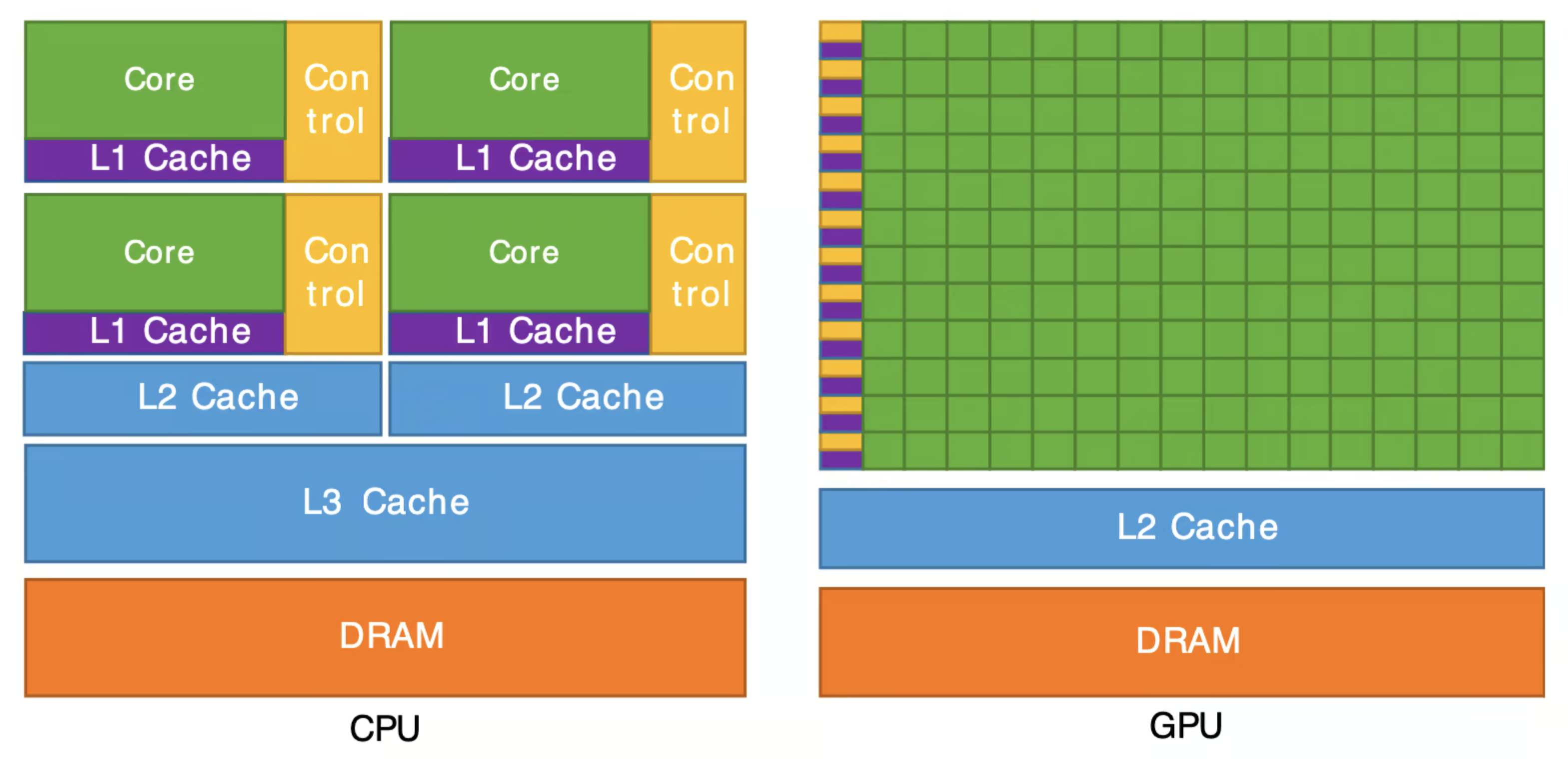 (图注:CPU架构示意图,其特点是拥有强大的ALU(算术逻辑单元)和大量的缓存,但计算核心数量较少;GPU架构示意图,其特点是拥有海量的ALU,控制单元和缓存相对简单)
(图注:CPU架构示意图,其特点是拥有强大的ALU(算术逻辑单元)和大量的缓存,但计算核心数量较少;GPU架构示意图,其特点是拥有海量的ALU,控制单元和缓存相对简单)
总而言之,CPU和GPU的设计差异决定了它们在AI计算中的分工:CPU负责整体的逻辑控制和任务调度,而GPU则专注于执行那些计算密集型、高度并行的核心任务。 理解了这种根本性的差异,我们才能更好地深入GPU的内部,探究其并行计算的奥秘。
二、 深入GPU架构:并行计算的奥秘
理解了GPU“人海战术”的设计哲学后,我们来进一步拆解其内部结构,看看这支庞大的“计算军团”是如何被组织和调度的。
SIMD/SIMT:并行计算的灵魂
GPU之所以能实现大规模并行,核心在于其计算模型。你可能听说过两个术语:SIMD(单指令,多数据)和SIMT(单指令,多线程)。
-
SIMD(Single Instruction, Multiple Data):这是并行计算的一种经典模型。它意味着用一条指令同时对多个数据执行相同的操作。想象一下,老师对一个班的学生说:“请大家把手里的数字都加上5”。在这里,“加5”就是单条指令,而每个学生手里的不同数字就是多份数据。
-
SIMT(Single Instruction, Multiple Threads):这是NVIDIA在CUDA架构中提出的模型,可以看作是SIMD在GPU上的升级版和更灵活的实现。它将成千上万的计算任务包装成线程(Thread),然后将32个线程组成一个线程束(Warp)。同一个Warp中的所有线程在同一个时钟周期内执行相同的指令,但每个线程可以处理不同的数据。SIMT模型的美妙之处在于它对开发者更友好,屏蔽了底层硬件的复杂性。你只需要编写单个线程要执行的程序,GPU的硬件调度器会自动将它映射到成千上万个核心上去并行执行。
在传统的标量计算模型中,CPU的一条指令一次只能操作单个数据。例如,一次浮点加法就是 double + double。当处理如图形、音频或科学计算中常见的大规模数据集时,这种“一次一个”的模式效率极低,因为我们需要对海量数据重复执行完全相同的操作,这暴露了标量处理的瓶颈。为了打破这个瓶颈,现代CPU集成了SIMD(单指令,多数据)架构。CPU增加了能容纳多个数据元素的宽向量寄存器(如256位的YMM寄存器),以及能够并行处理这些数据的执行单元。
无论是SIMD还是SIMT,其本质都是用一条指令驱动海量的计算单元,这是GPU实现超高计算吞吐量的根本。
- Warp/Wavefront 尺寸:NVIDIA 典型 warp=32,AMD wavefront=64。算法与 block 配置需对齐 warp 大小以避免“尾线程”浪费。
- 分支发散(Warp Divergence):同一 warp 内线程走不同分支,会串行化执行各分支路径,直至在重收敛点合流;可通过数据重排、位掩码/谓词化减少发散。
- 内存合并访问(Coalescing):warp 内连续地址访问可合并为更少事务,显著提升带宽利用;未对齐或跨行访问会降低有效带宽。
- 占用度(Occupancy)与隐藏延迟:足够多的活跃 warp 能隐藏访存与流水线延迟;占用度受限于寄存器/共享内存/线程数配额。
- 参考:
- CUDA C++ Programming Guide(SIMT/Thread Hierarchy/Memory Coalescing): https://docs.nvidia.com/cuda/cuda-c-programming-guide/
- CUDA Best Practices Guide: https://docs.nvidia.com/cuda/cuda-c-best-practices-guide/
- Nsight Compute User Guide: https://docs.nvidia.com/nsight-compute/
CUDA Core、Tensor Core与TPU:专业分工的计算单元
GPU的“计算军团”并非由单一兵种构成,而是由不同类型的专业计算单元组成,以应对不同的任务需求。
2007年,NVIDIA正式推出了CUDA平台。CUDA的革命性在于,它提供了一套简单的编程模型,让开发者能用近似C语言的方式,轻松地驾驭GPU内部成百上千个并行核心。 开发者无需再关心复杂的图形接口,可以直接编写在数千个线程上并发执行的程序。至此终结了GPGPU编程的蛮荒时代,让GPU计算真正走下神坛,成为开发者触手可及的强大工具。
-
CUDA Core:这是GPU最基本的计算单元,主要负责执行单精度浮点(FP32)和整数运算。你可以把它看作是GPU里的“普通士兵”,负责执行大部分通用的并行计算任务。
-
Tensor Core:这是NVIDIA从Volta架构开始引入的、专为深度学习打造的“特种部队”。Tensor Core专门用于执行大规模的矩阵乘加运算(Matrix Multiply-Accumulate, MMA),并且在硬件层面直接支持混合精度(FP16/FP32)和低精度(INT8/INT4)计算。在一次操作中,一个Tensor Core可以完成一个4x4的矩阵乘法,其效率远超CUDA核心。对于大模型训练和推理中无处不在的矩阵运算,Tensor Core能够带来数倍的性能提升。
-
与TPU的对比:Google的TPU(Tensor Processing Unit)是另一个为AI而生的专用处理器。如果说Tensor Core是GPU里的“特种部队”,那TPU就是一支纯粹的“矩阵运算专业军团”,它将整个芯片的设计都聚焦于此,因此在特定任务上能效比极高。而GPU则更像是一个通用平台,既有CUDA核心处理通用并行任务,又有Tensor Core加速AI任务。
进阶要点与参考(数值格式与算子栈):
- TF32/BF16:Ampere 引入 TF32(10-bit mantissa)在不改动 FP32 模型的前提下大幅提速;Hopper 进一步强化 BF16/FP8 的吞吐。
- 低比特推理:INT8/INT4 常配合量化感知训练(QAT)/后量化(PTQ)与校准;2:4 结构化稀疏在 Ampere 支持硬件加速。
- 编程接口:CUDA 的
wmma/mma.sync/cuBLASLt 提供 tile 级 MMA;TensorRT 在图级融合/格式选择上进一步榨干 Tensor Core 性能。 - 参考:
- NVIDIA Ampere Architecture WP: https://resources.nvidia.com/en-us-architecture/ampere-architecture-whitepaper
- NVIDIA Hopper Architecture WP(FP8): https://resources.nvidia.com/en-us-architecture/hopper-architecture-whitepaper
- TensorFloat-32 介绍: https://developer.nvidia.com/blog/tensorfloat-32-precision-format/
- cuBLAS/cuBLASLt 文档: https://docs.nvidia.com/cublas/
- TensorRT 文档: https://docs.nvidia.com/deeplearning/tensorrt/
计算单元
GPU中的计算单元是GPC(Graphics Processing Cluster),而一个GPC包含多个TPC(Texture Processing Cluster),而一个TPC中则包含多个SM(Streaming Multiprocessor),SM是GPU执行计算任务的核心单元,每个SM都是一个高度独立的计算单元。
如果说CUDA核心是士兵,那么SM(Streaming Multiprocessor,流式多处理器)就是军营里的“指挥官”。它包含了:
- 一定数量的CUDA核心和Tensor Core。
- 自己的指令缓存和调度器。
- 一小块高速的共享内存(Shared Memory),寄存器(Register File)和L1缓存(L1 Data Cache / Instruction Cache)。
- Warp调度器(Warp Scheduler)等关键组件。
SM是GPU执行任务的核心单位。当一个计算任务(在CUDA中称为Kernel)被启动时,它会被分解成一个个线程块(Thread Block),然后这些线程块被分配到不同的SM上去执行。SM内部的调度器再将线程块分解成线程束(Warp),并安排它们在CUDA核心或Tensor Core上执行。
SM就像一个自给自足的计算工厂,它接收任务,管理资源,调度执行,并最终产出结果。正是由成百上千个这样的“工厂”协同工作,才构成了GPU强大的并行处理能力。
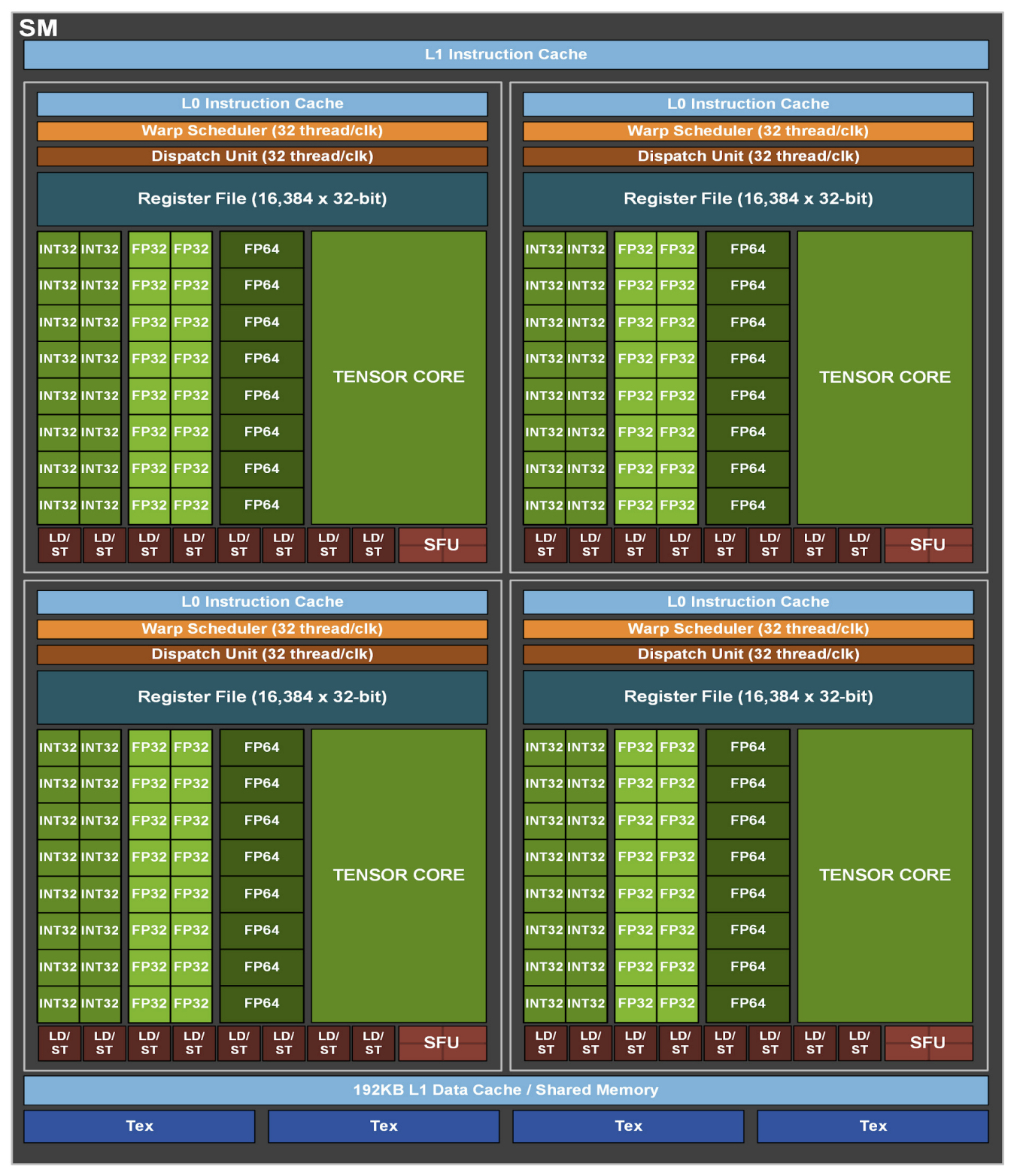 (图注:单个SM的架构图)
(图注:单个SM的架构图)
- 寄存器/共享内存配额:每个 SM 的寄存器数与 Shared Memory 容量是硬上限;单 kernel 的寄存器/SMEM 使用决定了每个 SM 可驻留的 Block/warp 数量。
- 活跃 warp 与吞吐:更高活跃 warp 有助于隐藏访存与流水线延迟,但并非越高越好;请结合 Nsight Compute 的
achieved_occupancy与sm_efficiency评估瓶颈。 - 调度:多 Warp 调度器/发射端口可以每拍发射多个指令;指令依赖、结构冲突与内存等待共同决定实际 IPC。
- 参考:
- Nsight Compute 指标说明: https://docs.nvidia.com/nsight-compute/ProfilingGuide/index.html
- CUDA Occupancy Calculator: https://developer.nvidia.com/cuda-occupancy-calculator
- CUDA C++ Programming Guide(Occupancy/Execution Resources): https://docs.nvidia.com/cuda/cuda-c-programming-guide/
内存层次
想象一下,你拥有一个成千上万人的计算军团,但如果后勤补给(数据供应)跟不上,这支军团的战斗力将大打折扣。这就是所谓的“内存墙”问题——计算单元的速度远超内存访问速度,导致计算单元不得不花费大量时间等待数据。
为了解决这个问题,现代高端GPU普遍采用HBM(High Bandwidth Memory,高带宽内存)。与传统的DDR内存不同,HBM通过以下方式实现了超高的带宽:
- 3D堆叠:HBM将多个DRAM芯片垂直堆叠起来,并通过硅通孔(TSV)技术进行连接,极大地增加了数据传输的并行度。
- 宽位宽接口:HBM拥有极宽的内存接口(如1024-bit或更高),远超DDR内存的64-bit。
你可以把DDR想象成一条普通的双车道公路,而HBM则是一条拥有32条车道的超级高速公路。通过HBM,GPU能够以极高的速度从显存中读取和写入数据,从而“喂饱”其内部成千上万个嗷嗷待哺的计算核心。
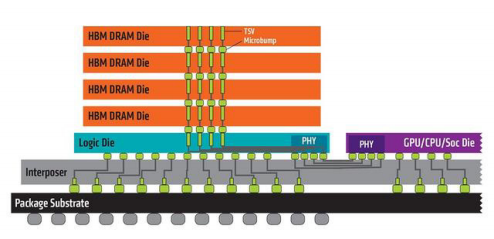 (图注:HBM通过3D堆叠和宽位宽接口技术实现超高内存带宽)
(图注:HBM通过3D堆叠和宽位宽接口技术实现超高内存带宽)
在一块GPU中,HBM和L2 Cache是整个GPU共享的,而L1 Cache/Shared Memory则是SM维度独享的。Shared Memory是每个SM内部的一块高速、可编程的片上缓存。同一线程块(Block)内的所有线程都可以访问它,速度远快于访问全局显存(HBM)。它是实现Block内线程高效协作和数据交换的核心,对于矩阵乘法等需要数据复用的算法至关重要。
- 合并访问与对齐:按 32/64/128B 对齐的顺序访问最友好;跨 stride 或散乱访问会放大事务数。
- Shared Memory 冲突:注意 bank 冲突;通过交错/转置/向量化降低冲突,或使用
cp.async(支持的架构)做块状搬运。 - L2/L1 策略:合适的 cache hint(如
ld.global.ca/cg)与预取可改善带宽利用;Host↔Device 侧使用 pinned memory/cudaMallocHost提升 H2D/D2H 吞吐。 - 参考:
- CUDA C++ Programming Guide(Memory Hierarchy/Coalescing/Shared Memory): https://docs.nvidia.com/cuda/cuda-c-programming-guide/
- Ampere 异步拷贝与 cp.async: https://developer.nvidia.com/blog/boosting-application-performance-with-the-new-nvidia-ampere-architecture/
- Pinned Memory(Page-Locked): https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#pinned-memory
异构计算
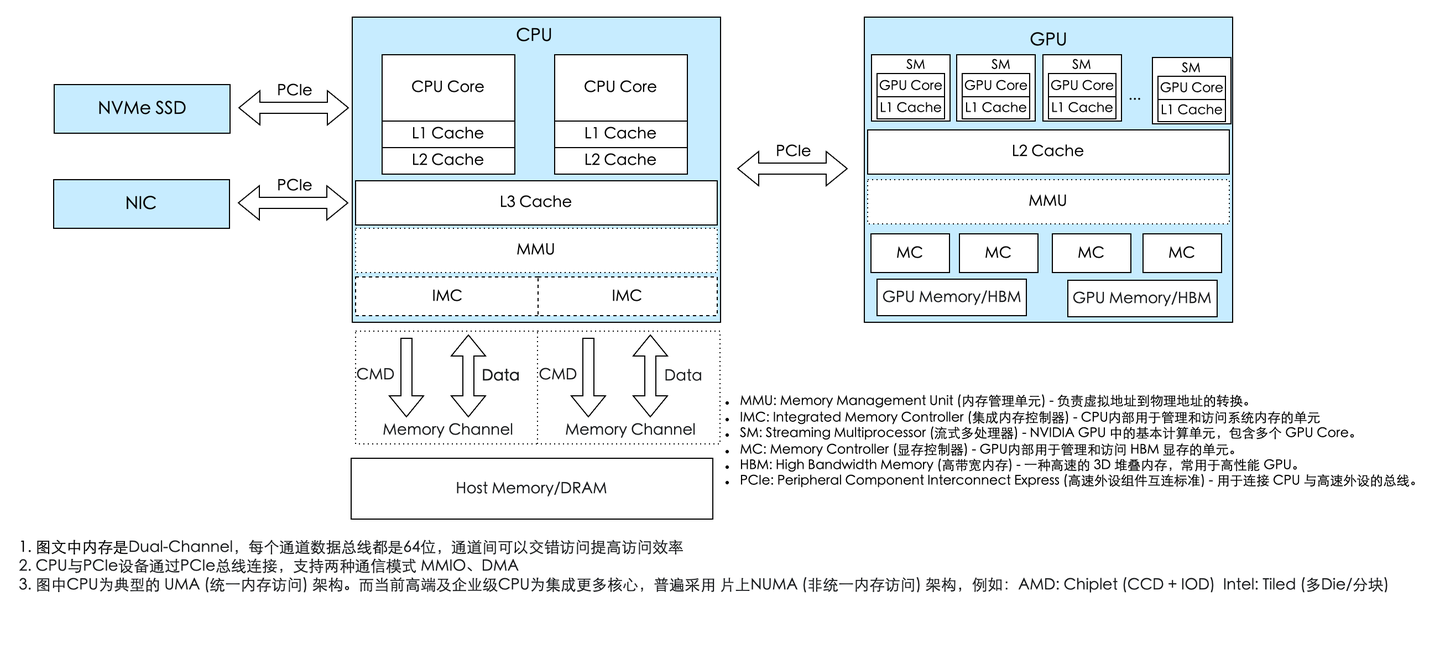 (图注:CPU/GPU异构计算架构)
(图注:CPU/GPU异构计算架构)
CPU是整个系统的核心,是总指挥,GPU的任务指令是由CPU分配的。CPU通过PCIe总线给GPU发送指令和数据交互。
- 互联:
PCIe为通用路径;NVLink/NVSwitch提升 GPU↔GPU/CPU 带宽;封装内NVLink‑C2C/UMA进一步降低延迟。而PCIe支持DMA和MMIO两种通讯模式:- MMIO(内存映射I/O,Memory Mapping I/O)由CPU直接控制数据读写,操作系统会把设备地址映射到CPU的虚拟空间中,适合小数据量的指令交互
- DMA(直接内存访问,Direct Memory Access)则允许设备绕过CPU直接访问系统内存,专为大数据块的高效传输设计。 CPU通过IMC和Memory Channel访问内存,为了提升数据传输带宽,高端CPU通常会支持多内存通道,即多IMC和Memory Channel的组合,以满足日益增长的数据处理需求。
- 内存:
UVM提供单一地址空间(配合预取/访问提示);Pinned/Zero‑copy降低拷贝开销;GPUDirect(P2P/RDMA/GDS)减少绕行。 - 编程:多
stream与events重叠拷贝与计算;CUDA Graphs降低小内核启动开销;NCCL负责多 GPU 集体通信。 - 并行:
DP/TP/PP/EP可组合扩展超大模型。 - 部署:
MIG分片、MPS并发,容器与 K8s 做拓扑感知调度。
进阶要点与参考(互联/内存/编程):
- 互联拓扑:多 GPU 拓扑(双路 NVLink 对接、NVSwitch 全互连)影响带宽对称性与 AllReduce 性能;NCCL 会自适应拓扑构建环/树。
- UVM 迁移:按页迁移(page migration)可能带来缺页中断与 TLB 抖动;使用
cudaMemAdvise/cudaMemPrefetchAsync预取可降低抖动。 - Pinned 与可分页内存:可分页内存通常经隐式 staging;显式
cudaMallocHost可减少一次拷贝并提升吞吐;多 copy 引擎支持并发 H2D/D2H。 - 默认流语义:建议开启 PTDS(Per-Thread Default Stream) 避免旧式全局同步;利用 流优先级 与 事件 管理核间依赖。
- MPS/MIG:MPS 通过命令队列复用提高小核吞吐;MIG 将 SM/HBM/L2 切片隔离以实现多租户 QoS。
- 参考:
- NVLink/NVSwitch: https://developer.nvidia.com/nvlink
- NCCL 文档: https://developer.nvidia.com/nccl
- Unified Memory/UVM: https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#um-overview
- Default Stream/PTDS: https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#stream-ordered-memory-operations
- CUDA MPS: https://docs.nvidia.com/deploy/mps/index.html
- NVIDIA MIG User Guide: https://docs.nvidia.com/datacenter/tesla/mig-user-guide/
三、 简易的一个例子
以下这个demo是实现两个长度为 $2^{30}$ (约10亿) 的浮点数数组的相加。其中,一个数组 $(x)$ 的所有元素初始化为 $1.0$,另一个数组 $(y)$ 的所有元素初始化为 $2.0$,我们计算 $y[i] = x[i] + y[i]$。
CPU实现
#include <iostream>
#include <math.h>
#include <chrono>
// function to add the elements of two arrays
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1<<30;
float *x = new float[N];
float *y = new float[N];
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
auto start = std::chrono::high_resolution_clock::now();
// Run kernel on 1M elements on the CPU
add(N, x, y);
auto stop = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(stop - start);
std::cout << "CPU 'add' function execution time: " << duration.count() << " ms" << std::endl;
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
delete [] x;
delete [] y;
return 0;
}
性能表现:
g++ add.cpp -o add
time ./add
CPU 'add' function execution time: 3740 ms
Max error: 0
real 0m21.418s
user 0m15.798s
sys 0m4.400s
- 计算耗时: 核心的add函数耗时 3740毫秒。
- 总耗时: 整个程序从启动到结束(real time)耗时 21.4秒。这额外的时间主要消耗在分配8GB内存(new float[N])以及初始化数组上。
GPU实现
包含步骤:
- 分配内存: 分别在CPU(Host)和GPU(Device, cudaMalloc)上分配内存。
- 数据传输 (H2D): 将CPU上的输入数据 (h_x, h_y) 拷贝到GPU显存 (d_x, d_y)。
- 执行Kernel函数: 在GPU上启动addKernel函数,利用其大规模并行能力进行计算。
- 数据传回 (D2H): 将GPU计算完成的结果 (d_y) 拷贝回CPU内存 (h_y) 以便后续使用或验证。
#include <iostream>
#include <math.h>
#define CUDA_CHECK(call) \
do { \
cudaError_t err = call; \
if (err != cudaSuccess) { \
fprintf(stderr, "CUDA Error in %s at line %d: %s\n", __FILE__, __LINE__, cudaGetErrorString(err)); \
exit(EXIT_FAILURE); \
} \
} while (0)
// __global__ 关键字声明的函数被称为Kernel函数
__global__
void add(int n, float *x, float *y)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
if (index < n) {
y[index] = x[index] + y[index];
}
}
int main(void)
{
int N = 1 << 30;
size_t bytes = N * sizeof(float);
float *h_x, *h_y;
h_x = new float[N];
h_y = new float[N];
float *d_x, *d_y;
CUDA_CHECK(cudaMalloc(&d_x, bytes));
CUDA_CHECK(cudaMalloc(&d_y, bytes));
for (int i = 0; i < N; i++) {
h_x[i] = 1.0f;
h_y[i] = 2.0f;
}
CUDA_CHECK(cudaMemcpy(d_x, h_x, bytes, cudaMemcpyHostToDevice));
CUDA_CHECK(cudaMemcpy(d_y, h_y, bytes, cudaMemcpyHostToDevice));
cudaEvent_t start, stop;
CUDA_CHECK(cudaEventCreate(&start));
CUDA_CHECK(cudaEventCreate(&stop));
CUDA_CHECK(cudaEventRecord(start));
int blockSize = 256;
int numBlocks = (N + blockSize - 1) / blockSize;
add<<<numBlocks, blockSize>>>(N, d_x, d_y);
CUDA_CHECK(cudaEventRecord(stop));
CUDA_CHECK(cudaEventSynchronize(stop));
float milliseconds = 0;
CUDA_CHECK(cudaEventElapsedTime(&milliseconds, start, stop));
std::cout << "GPU Kernel 'add' execution time: " << milliseconds << " ms" << std::endl;
CUDA_CHECK(cudaEventDestroy(start));
CUDA_CHECK(cudaEventDestroy(stop));
CUDA_CHECK(cudaMemcpy(h_y, d_y, bytes, cudaMemcpyDeviceToHost));
float maxError = 0.0f;
for (int i = 0; i < N; i++) {
maxError = fmax(maxError, fabs(h_y[i] - 3.0f));
}
std::cout << "Max error: " << maxError << std::endl;
delete[] h_x;
delete[] h_y;
CUDA_CHECK(cudaFree(d_x));
CUDA_CHECK(cudaFree(d_y));
return 0;
}
性能表现:
nvcc add.cu -o add_cu -gencode arch=compute_75,code=sm_75
time ./add_cu
GPU Kernel 'add' execution time: 48.6738 ms
Max error: 0
real 0m19.413s
user 0m15.308s
sys 0m4.014s
- 计算耗时: GPU Kernel 函数的执行耗时仅为 48.7 毫秒。
- 总耗时: 程序总耗时为 19.4秒。
性能分析
单看核心计算任务,GPU (48.7ms) 的速度是CPU (3740ms) 的 约75倍。这完美体现了GPU在处理数据并行任务时的绝对优势。CPU需要串行执行10亿次加法(此处只考虑单核场景),而GPU则将任务分配给成千上万个线程同时处理。
但是虽然GPU计算本身极快,但程序的总耗时 (19.4s) 却和CPU版本 (21.4s) 相差无几。这是为什么呢?主要是CPU和GPU通讯的开销。
进阶要点与参考(端到端性能):
- 使用 pinned host 内存:用
cudaMallocHost/cudaHostAlloc替代可分页内存,减少隐式 staging 拷贝。 - 拷贝与计算重叠:用多个流(streams)与事件,将 H2D/D2H 与计算重叠;对巨数组分块流水化。
- 合理网格配置:block 尺寸取 warp 倍数(如 128/256/512),结合
numBlocks≈SM×(blocks/SM)与占用度计算器微调。 - 核内优化:向量化(float4)、显式共享内存缓存、
__ldg/cache hint、避免分支发散与非合并访问。 - 编译与架构:为目标架构编译(
-gencode),关注-use_fast_math的数值影响;用 Nsight Systems/Compute 定位瓶颈。 - 参考:
- Nsight Systems: https://docs.nvidia.com/nsight-systems/
- Nsight Compute: https://docs.nvidia.com/nsight-compute/
- CUDA Best Practices Guide: https://docs.nvidia.com/cuda/cuda-c-best-practices-guide/
GPU上一次任务执行的步骤
1) 编译阶段(主机侧)
- 使用
nvcc add.cu -o add_cu -gencode arch=compute_75,code=sm_75:生成可执行文件,内部可能包含cubin/ptx等设备代码。若只含 PTX,运行时会进行 JIT 编译到目标 GPU 的 SASS。 - 可打包多个
-gencode以兼容多代架构;-lineinfo便于性能分析;--cudart shared影响运行时装载方式。
2) 程序加载与进程启动
- OS 加载可执行文件,进入
main。首次触发任意 CUDA Runtime API(如cudaMalloc)时,运行时进行懒初始化。 - Windows WDDM 与 Linux/TCC 在设备独占与 watchdog 上差异显著;服务器侧 TCC 可避免桌面 watchdog 触发。
3) 启动 CUDA 调用(初始化与上下文)
- 硬件准备与唤醒:驱动检查设备、上电与功耗状态切换(空闲→P0/性能态),建立与设备的管理通道(通常经 PCIe/NVLink)。
- 运行时/驱动初始化:加载 NVIDIA 驱动模块,创建与设备通讯所需的数据结构。
- 选择设备:默认设备为
device 0(也可通过cudaGetDevice/cudaSetDevice指定)。 - 上下文创建:获取或创建该设备的 Primary Context,并将其设为当前线程的 active context(Runtime API 使用 Primary Context)。
- 上下文就绪:完成流、事件、内存分配器、JIT 缓存等必要子系统的初始化。
- 多线程程序应避免在多个线程反复创建/销毁 context;可使用 MPS 复用上下文提高吞吐。
4) 模块与函数准备
- 若可执行中包含 PTX:驱动在首次使用时对 PTX 做 JIT → SASS,并缓存。
- 解析出要执行的 Kernel 符号
add<<<...>>>(),生成启动描述符(grid/block/共享内存大小/实参/流)。 - JIT 缓存可落磁盘(
~/.nv/ComputeCache),不同驱动版本与PTX/SASS兼容性会影响命中。
5) 内存与数据阶段
- Host 侧内存:示例使用
new float[N]分配并初始化h_x/h_y。 - Device 侧内存:
cudaMalloc(&d_x, bytes)、cudaMalloc(&d_y, bytes)。 - H2D 拷贝:
cudaMemcpy(d_x, h_x, ...)、cudaMemcpy(d_y, h_y, ...)。- 若主机内存为 pageable,驱动会使用隐式 pinned staging 做分段 DMA;显式
cudaMallocHost可减少一次拷贝并提升吞吐。
- 若主机内存为 pageable,驱动会使用隐式 pinned staging 做分段 DMA;显式
- 现代 GPU 支持多 copy engine(如 2×DMA)以实现 H2D/D2H 并行;
cudaMemcpyAsync+ streams 才能与计算重叠。
6) Kernel 启动
- 配置:
int blockSize=256; int numBlocks=(N+blockSize-1)/blockSize; - 记录时间戳:
cudaEventRecord(start)。 - 启动:
add<<<numBlocks, blockSize, 0, /* default stream */ 0>>>(N, d_x, d_y); - 运行时打包 launch 参数并提交到驱动命令队列;默认流保证在该流上的顺序语义。
- PTDS 下默认流仅对本线程序;可用 高优先级流 抢占调度;CUDA Graphs 可将多次 launch 合并降低开销。
7) 硬件执行(设备侧)
- 调度:命令由前端送入 GPU,调度到 GPC/SM。每个 SM 依据可用寄存器/共享内存决定 CTA(Block)驻留数(占用度)。
- 执行:Warp 调度器以 SIMT 模式发射指令;访存经 L1/L2/显存(HBM),示例 Kernel 为简单逐元素加法,受内存带宽影响更大。
- 完成:所有 CTA 结束后,内核在该流上标记完成。
- 分支发散与非合并访问会显著拉低 IPC 与带宽;Warp Scheduler 采用 round-robin/oldest-first 隐藏延迟;TLB 与 L2 命中率影响有效带宽。
8) 同步与计时
cudaEventRecord(stop)→cudaEventSynchronize(stop),通过cudaEventElapsedTime计算 Kernel 纯执行时间。- Event 计时不含 Host↔Device 拷贝(除非在拷贝前后记录事件);跨设备/跨流要注意事件记录所在流上下文。
9) 结果回传与校验
- D2H 拷贝:
cudaMemcpy(h_y, d_y, bytes, cudaMemcpyDeviceToHost)。 - 校验:遍历
h_y,应得到3.0f。 - 若数据量巨大,可分批回传并流水化;用设备端
thrust::reduce校验可减少 D2H。
10) 资源释放与退出
- 释放:
cudaFree(d_x/d_y)、delete[] h_x/h_y、销毁事件。 - 进程结束:Primary Context 引用计数归零后可被驱动回收;JIT 缓存可复用;设备回到低功耗/空闲态。
- 长生命周期服务建议复用上下文与内存池(
cudaMemPool),避免频繁创建/销毁导致抖动。
11) 性能可视化与系统级优化
- 使用 Nsight Systems 观察时间线,验证拷贝/计算重叠效果与流并发;用 Nsight Compute 分析内核级指标(占用度、访存、发散)。
- 拓扑放置:NUMA 绑定、PCIe 插槽亲和、NVLink 拓扑对实际带宽影响巨大;容器/编排需拓扑感知。
- 多 GPU:通过 NCCL(环/树/分层)做 AllReduce;合理划分 DP/TP/PP/EP,减少跨节点通信热斑。
四、 结语:从架构到实践
本文从 CPU 与 GPU 的设计分野出发,说明了 GPU 如何以 SIMT 和海量并行单元换取吞吐,其中 SM 是任务执行与资源调度的基本单位。要把并行算力变成可见的应用性能,内存层次与带宽是第一性约束:HBM + 宽接口 缓解“内存墙”,共享 L2 与 SM 侧的 L1/Shared Memory 共同决定算子的效率上限。异构协同方面,CPU 负责组织与 I/O,GPU 承担矩阵/向量主力,互联从 PCIe 演进到 NVLink/NVSwitch,并在封装内通过 NVLink‑C2C/UMA 进一步降低延迟。
在编程实践中,应通过 Streams/Events 重叠搬运与计算,用 CUDA Graphs 降低小内核的启动开销,依赖 NCCL 完成多 GPU 集体通信,并按需组合 DP/TP/PP/EP 等并行策略来支撑超大模型。结合文中的示例可以看到,端到端耗时常由数据“搬运”主导,因此优化顺序应优先打通数据路径与拓扑放置,再到核内算子与网格配置。展望未来,更强的专用单元(如 Tensor/Transformer Core)、更紧耦合的 CPU‑GPU 形态以及更开放的内存互联(如 CXL)将继续抬升系统级带宽与利用率。
一句话总结:要让 GPU 真正“跑快”,既要并行算得动,更要数据喂得上。