如果将光学字符识别(OCR)技术应用于一些自然场景的图片,从而达到识别图片中文本文字的目的,通常会是一个two-stage的过程:
- 文字检测:找到文字在图像中的位置,返回对应位置信息(Bounding Box);
- 文字识别:对于对应Bounding Box区域内的文字进行识别,认出其中每个文字字符代表什么,最终将图像中的文字区域转化为字符信息。
DBNet
目前文字检测普遍的做法有两种:
- 基于回归:Textboxes++、R2CNN,FEN等
- 基于分割:Pixel-Link,PSENet,PMTD,LOMO,DBNet等
DBNet名字中的DB指Differentiable Binarization,即微分二值化的模块。传统的分割方法会预设一个阈值,将分割网络生成的概率图转换为二值图像;然后,采用像素聚类等启发式技术将像素分组为文本实例。而DBNet中将二值化操作插入到分割网络中进行联合优化,这样网络可以自适应的预测图像中每一个像素点的阈值(区别去传统方法的固定阈值),从而可完全区分前景和背景的像素。
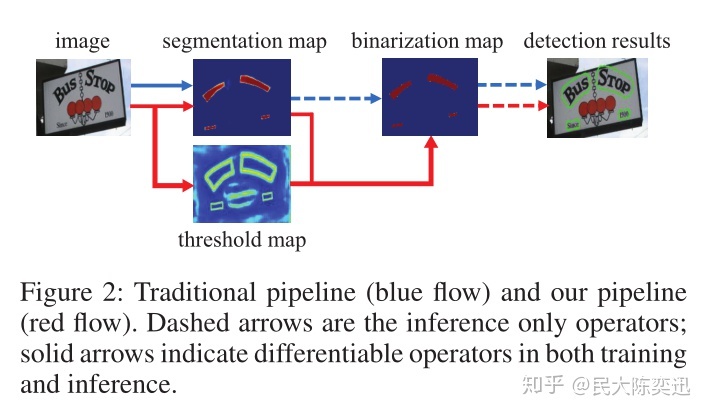
DBNet整个流程如下:
- 图像经过FPN网络结构,得到四个特征图,分别为$\frac{1}{4}$、$\frac{1}{8}$、$\frac{1}{16}$、$\frac{1}{32}$大小;
- 将四个特征图分别上采样为$\frac{1}{4}$大小,再concat,得到特征图F;
- 由F得到 probability map (P) 和 threshold map (T);
- 通过P、T计算approximate binary map( 近似binary map $\hat B$ )。
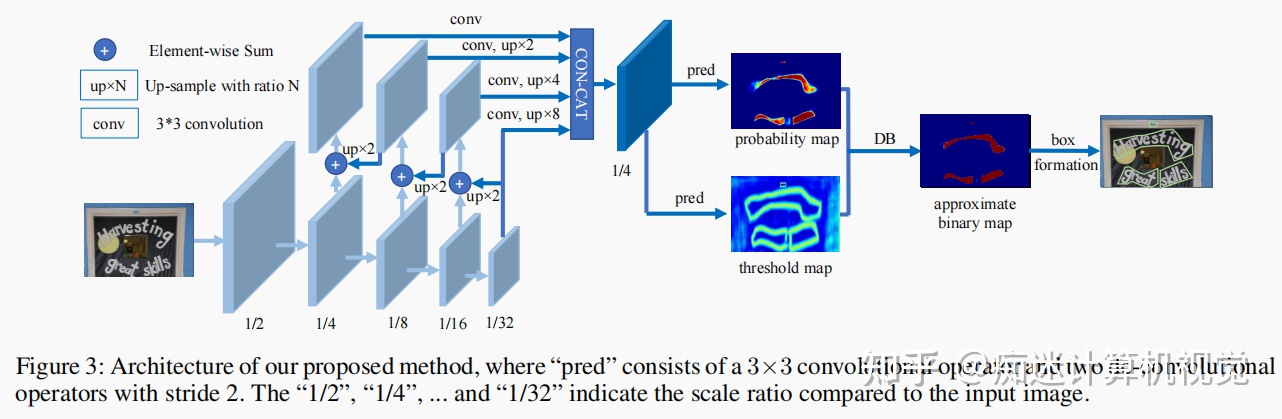
由F计算得到P和T可以表示为:
1 binary = self.binarize(fuse) #由F得到P,fuse为特征图F
2 if self.training:
3 result = OrderedDict(binary=binary)
4 else:
5 return binary
6 if self.adaptive and self.training:
7 if self.serial:
9 fuse = torch.cat(
10 (fuse, nn.functional.interpolate(
11 binary, fuse.shape[2:])), 1)
12 thresh = self.thresh(fuse)
其中第一行通过fuse得到了binary即P,具体实现在self.binarize函数:
1 self.binarize = nn.Sequential(
2 nn.Conv2d(inner_channels, inner_channels //
3 4, 3, padding=1, bias=bias), #shape:(batch,256,1/4W,1/4H)
4 BatchNorm2d(inner_channels//4),
5 nn.ReLU(inplace=True),
6 nn.ConvTranspose2d(inner_channels//4, inner_channels//4, 2, 2), #shape:(batch,256,1/2W,1/2H)
7 BatchNorm2d(inner_channels//4),
8 nn.ReLU(inplace=True),
9 nn.ConvTranspose2d(inner_channels//4, 1, 2, 2), #shape:(batch, W, H)
10 nn.Sigmoid())
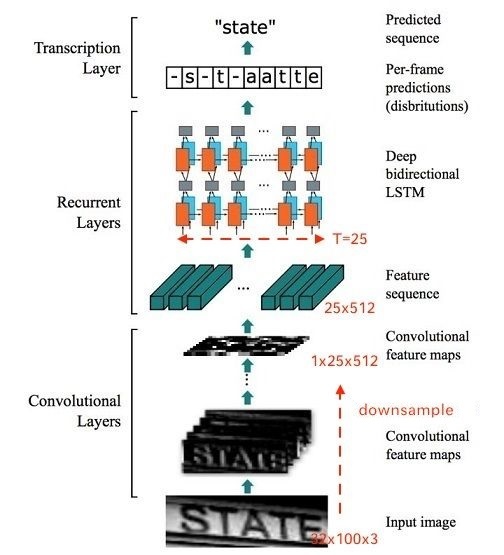
CRNN
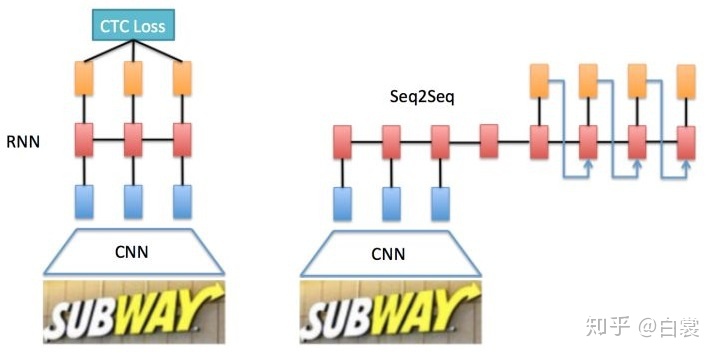
基于CNN和RNN的文字识别结构主要有两种形式:
1. CNN+RNN+CTC(CRNN+CTC)
1. CNN+Seq2Seq+Attention
其中CRNN的应用最为广泛。整个CRNN网络可以分为三个部分:
- Conv Layers:即普通CNN网络用于提取图像Conv Feature Maps;
- Recurrent Layers:一个深层双向LSTM网络,在卷积特征的基础上继续提取文字序列特征;
- Transcription Layers:将RNN输出做softmax后,为字符输出。