随着锚框(anchor)在检测算法中的广泛应用,无论是从 R-CNN 系列演进来的两阶段(two-stage)检测器,还是以 YOLO 和 SSD 为代表的单阶段(one-stage)模型,其核心策略都是在图像上密集地铺设大量预设尺寸和长宽比的锚框,以期覆盖所有可能的目标。然而,这种 anchor-based 的范式虽然取得了巨大成功,却也存在着一些固有的、难以回避的弊端:
- 锚框数量冗余,计算与显存开销巨大:为了实现高召回率,通常需要在图像上设置数以万计的锚框。其中,绝大多数锚框与任何真实目标(Ground Truth, GT)都无法有效匹配,它们作为简单的负样本被舍弃,却消耗了大量的计算资源,并导致了训练过程中正负样本的极端不平衡。
- 引入过多超参数,训练部署流程复杂:锚框的尺度、长宽比、以及与 GT 匹配的 IoU 阈值等,都是需要精细调节的超参数。这使得训练过程变得敏感且繁琐,同时,复杂的后处理(如非极大值抑制 NMS)也增加了模型部署的难度并可能影响最终性能。
为了解决这些问题,学术界开始探索更为简洁高效的 anchor-free 方法,这股浪潮催生了如 FCOS、FoveaBox 等众多优秀工作。而 CornerNet 和 CenterNet 正是这一方向的开创性工作,它们通过新颖的视角重新定义了目标检测问题,对后续研究产生了深远影响。
CornerNet
CornerNet 的论文标题为 Detecting Objects as Paired Keypoints,其核心思想是“将物体检测视为成对关键点的检测与匹配问题”。本文将从以下几点展开,深入剖析其精髓:
- 如何用 anchor-free 的方式表示目标;
- 什么是 corner pooling;
- 网络结构与损失函数;
- 角点配对与后处理。
Locate the Object (目标定位)
在 CornerNet 中,一个目标边界框(bbox)由其左上角(top-left)和右下角(bottom-right)两个关键点来唯一确定。网络的目标就是去预测这两组角点的位置。但仅有位置信息是不够的,如何将图像中属于同一个物体的左上角和右下角正确配对,是 anchor-free 方法必须解决的核心问题。
为此,CornerNet 引入了 Embedding(嵌入) 的概念。网络会为每一个预测出的角点学习一个低维度的嵌入向量(embedding vector,又称 tag)。在训练过程中,通过特定的损失函数,使得属于同一个物体的角点对的 embedding 向量在特征空间中的距离(通常是 L1 或 L2 距离)更近,而属于不同物体的角点则相互疏远。这样,在推理阶段就可以通过计算 embedding 向量间的距离来完成角点的配对。
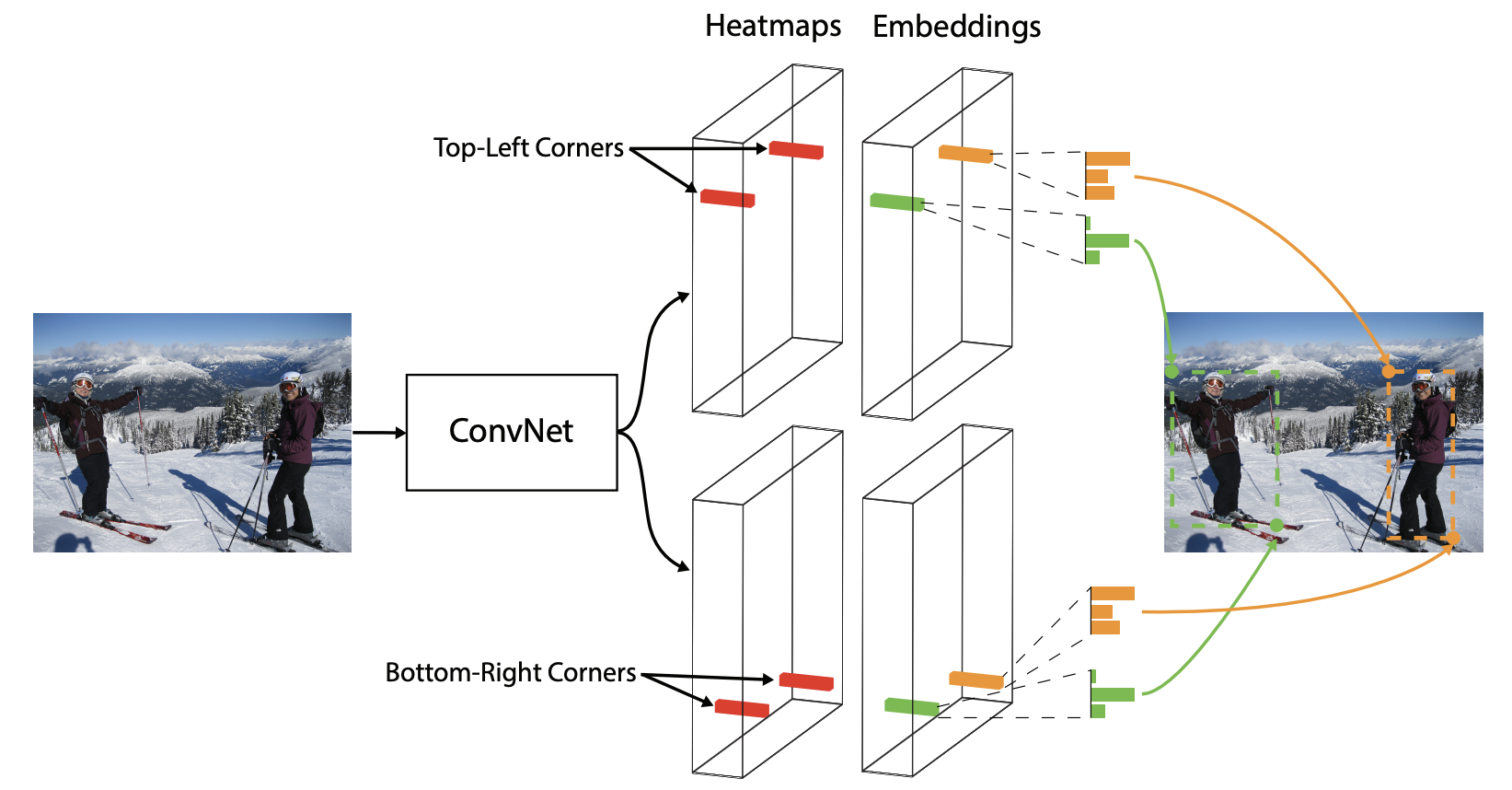
作者选择角点而非中心点(center)或 proposal,主要基于以下考量:物体的中心点位置难以直接从局部特征中判断,往往需要依赖物体的四条边;而角点则天然地位于物体的边界,仅需两条边的信息即可确定,这使得角点检测更符合“关键点检测”的范式,并且理论上角点对于物体部分遮挡的情况比中心点更具鲁棒性。
Corner Pooling (角点池化)
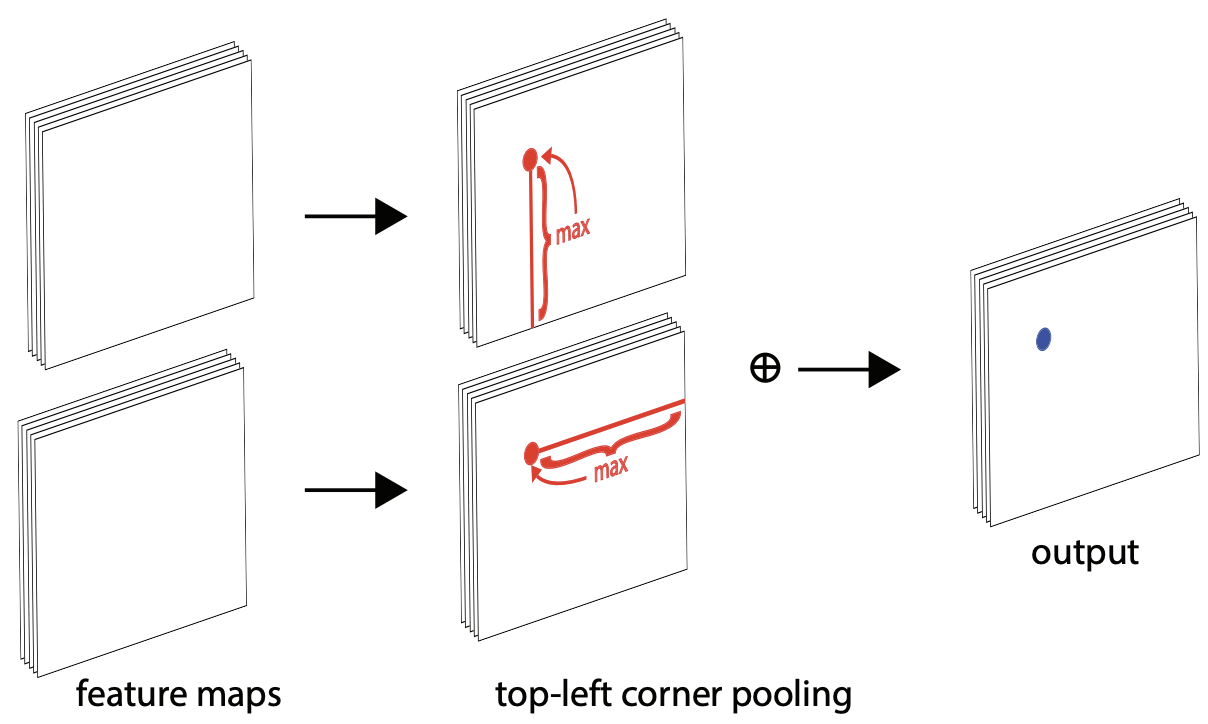
角点的一个显著特征是,它们通常位于物体的外部轮廓上,其自身局部区域可能并不包含足够的物体信息。为了让网络在预测角点位置时能“感知”到物体的全局结构,CornerNet 设计了一种新颖的池化层——Corner Pooling。
以左上角为例,其位置由物体的顶边和左边共同决定。因此,对于一个候选的左上角位置 (i,j),Corner Pooling 的具体操作如下:
- 水平扫描: 从位置
(i,j)到(i, W-1)(W为特征图宽度)的路径上所有特征向量进行逐元素最大化(element-wise maximum),得到一个聚合了右侧信息的特征向量t_ij。 - 垂直扫描: 从位置
(i,j)到(H-1, j)(H为特征图高度)的路径上所有特征向量进行逐元素最大化,得到一个聚合了下方信息的特征向量l_ij。 - 聚合: 将
t_ij和l_ij两个向量相加,作为该位置的最终输出。
这个操作能有效地将物体的边界信息聚合到角点的位置,从而帮助网络更准确地定位角点。右下角点的 Corner Pooling 则采用相反的方向(水平向左、垂直向上)。
CornerNet Detail (网络细节)
Network Architecture (网络架构)
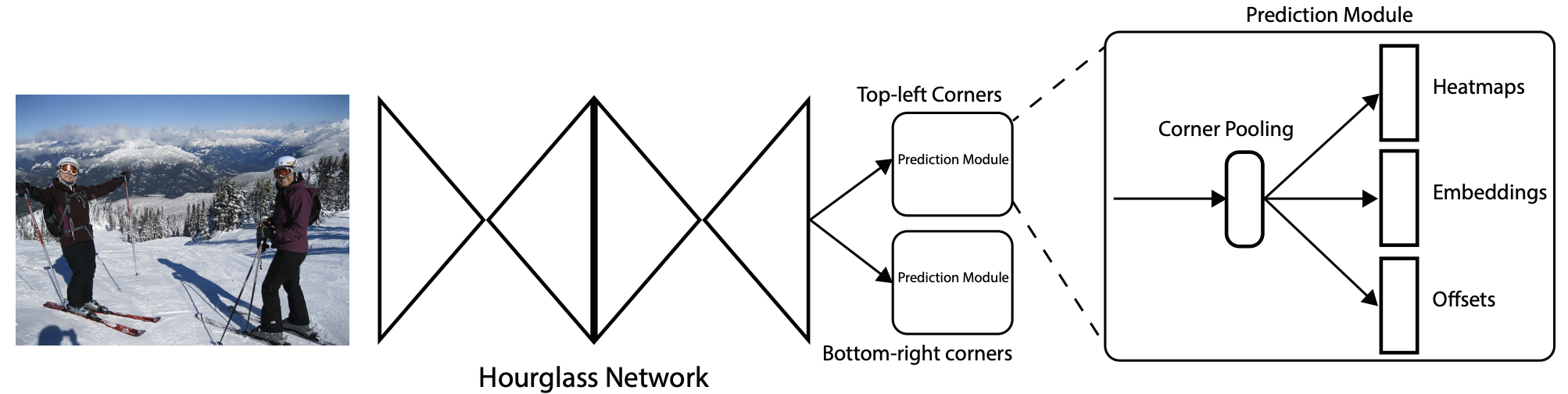
CornerNet 的骨干网络采用了在姿态估计领域大放异彩的 Hourglass Network(沙漏网络)。沙漏网络通过其对称的、重复的下采样和上采样结构以及密集的跳跃连接(skip connections),能够在一个统一的结构内高效地融合局部细节(来自上采样路径)和全局上下文信息(来自下采样路径)。这对于需要综合多尺度特征来精确定位的关键点检测任务来说至关重要。CornerNet 中堆叠了两个沙漏模块,以进一步增强网络的特征提取能力。
在骨干网络之后,模型分为两个独立的分支,分别用于预测左上角和右下角。每个分支都包含各自的 Corner Pooling 模块,并最终输出三组预测图:
- Heatmaps (热力图):预测角点出现的位置。
- Embeddings (嵌入向量):用于角点配对。
- Offsets (偏移量):用于修正下采样带来的位置误差。
Loss Function (损失函数)
CornerNet 的总损失由三部分构成,并通过加权和进行组合: (L = \alpha L_{det} + \beta L_{pull} + \gamma L_{push} + \delta L_{off})。其中 (\alpha, \beta, \gamma, \delta) 是各项损失的权重超参数。
Focal Loss(热力图损失,改进版)
网络输出的角点热力图维度为 (\tilde{M}\in\mathbb{R}^{\tfrac{W}{R}\times\tfrac{H}{R}\times C})。对于每个真实角点,其在 GT 热力图上的标签并非简单的 0/1 二值分布,而是以该点为中心的一个高斯分布。这种“软标签”设计可以鼓励网络预测出靠近真实角点的位置。损失函数采用了 Focal Loss 的一个改进版本,该思想源自 RetinaNet,旨在解决正样本(角点)与负样本(背景)间的极端不平衡问题。
\[L_{det}=\frac{-1}{N}\sum_{c=1}^{C}\sum_{i=1}^{H}\sum_{j=1}^{W}\left\{\begin{matrix} (1-p_{cij})^{\alpha} \log(p_{cij}) & \text{if } y_{cij}=1 \\ (1-y_{cij})^{\beta}(p_{cij})^{\alpha}\log(1-p_{cij}) & \text{Otherwise} \end{matrix}\right.\]其中,$y_{cij}=1$ 的位置是 GT 角点,而高斯半径内其他位置的 $y_{cij}$ 值则小于 1。$(1-y_{cij})^{\beta}$ 这一项是其核心改进,能够减小这些“次优位置”(即高斯核覆盖的、靠近真值的负样本)的惩罚权重,使网络更专注于学习那些远离真值的、困难的负样本。
Embedding Loss (嵌入损失)
嵌入损失分为 “pull” 和 “push” 两部分,用于训练角点配对的 embedding 向量 (\tilde{E}\in\mathbb{R}^{\tfrac{W}{R}\times\tfrac{H}{R}\times1})。
-
Pull Loss (类内拉近损失): 使属于同一个物体的角点对 $(e_{t_k}, e_{b_k})$ 的 embedding 向量向它们的均值 $e_k$ 靠近,目的是让同类更紧凑。 \(L_{pull}=\frac{1}{N}\sum_{k=1}^{N}[(e_{t_k}-e_k)^2+(e_{b_k}-e_k)^2]\)
-
Push Loss (类间推远损失): 使不同物体的角点对的 embedding 均值 $(e_k, e_j)$ 相互疏远,目的是让异类更分离。此处的距离通常用 L1 距离。 \(L_{push}=\frac{1}{N(N-1)}\sum_{k=1}^{N}\sum_{j=1,j\neq k}^{N}\max(0, \triangle -|e_k-e_j|)\) 其中 (\triangle) 是一个超参数,定义了不同物体 embedding 之间的最小间隔(margin)。
Offsets Loss (偏移量损失)
由于骨干网络进行了下采样(stride > 1),将预测结果从低分辨率热力图映射回原始图像时,会因取整操作产生量化误差,这对小物体尤其致命。因此,网络引入一个 offset 分支 (\tilde{O}\in\mathbb{R}^{\tfrac{W}{R}\times\tfrac{H}{R}\times2}) 来学习这个误差并进行补偿。该损失仅对存在真实角点的位置计算,并采用对离群点更鲁棒的 Smooth L1 Loss。
\[L_{off}=\frac{1}{N}\sum_{k=1}^{N}{\text{SmoothL1Loss}}(o_k, \hat{o_k})\]CenterNet
CornerNet 在推理时需要对角点进行分组配对,这个过程不仅计算复杂,也存在配对失败的风险。CenterNet 在此基础上提出了一个更为简洁优雅的方案——“将物体视为点”(Objects as Points),显著简化了检测流程,使其成为一个几乎完全端到端(end-to-end)的检测器。
CenterNet 直接预测目标的中心点,并从此中心点回归该目标的宽高、偏移量等其他属性。该思想也可以方便地扩展到 3D 检测、人体姿态估计等任务。其本质是一个纯粹的关键点检测问题:用一个全卷积网络(FCN)生成热力图,图上的局部峰值点即为预测的物体中心。
总之,CenterNet 结构极为简洁,是真正意义上彻底的 anchor-free 和 NMS-free 检测器。
Network Architecture (网络架构)
论文中 CenterNet 提及了三种可用的骨干网络,它们都是编码器-解码器(encoder-decoder)结构,以在速度和精度间进行权衡:
- ResNet‑18 with up-conv:28.1% COCO AP,142 FPS
- DLA‑34 (Deep Layer Aggregation):37.4% COCO AP,52 FPS
- Hourglass‑104:45.1% COCO AP,1.4 FPS
无论骨干网络如何,其预测头部的结构是统一的,通常由一个 3x3 卷积进行特征整合,后接三个并行的 1x1 卷积分支,分别输出:类别热力图(heatmap)、中心点偏移量(offset)和物体尺寸(wh)。
训练时,每个 GT 框的中心点被投影到下采样后的特征图上 (\tilde{p}=\left\lfloor p/R\right\rfloor),并围绕 (\tilde{p}) 渲染一个高斯核。高斯核的半径 (\sigma_p) 是一个与物体尺寸自适应的参数,其确定原则是:如果一个与 GT 框有特定 IoU(如0.7)的预测框,其中心点落在高斯半径内,那么这个点就被视为正样本。这个巧妙的设计保证了不同尺寸的物体都能有合适范围的正样本区域。
\[Y_{xyc}=\exp(-\frac{(x-\tilde{p}_x)^2+(y-\tilde{p}_y)^2}{2\sigma ^2_p})\]Loss Function (损失函数)
CenterNet 的总损失由三个部分构成,同样通过加权和进行组合:(L_{det} = L_k + \lambda_{size}L_{size} + \lambda_{off}L_{off}),其中 (\lambda_{size}) 和 (\lambda_{off}) 是平衡各项任务的权重。
Center Points Loss Function(中心点热力图损失)
同样是 Focal Loss 的改进版,用于监督中心点热力图的生成。其形式与 CornerNet 的热力图损失非常相似。
\[L_k=\frac{-1}{N}\sum_{xyc}\left\{\begin{matrix} (1-\hat{Y}_{xyc})^\alpha \log(\hat{Y}_{xyc}) & \text{if } Y_{xyc}=1 \\ (1-Y_{xyc})^{\beta}(\hat{Y}_{xyc})^{\alpha}\log(1-\hat{Y}_{xyc}) & \text{Otherwise} \end{matrix}\right.\]其中 $\alpha=2$ 和 $\beta=4$ 是论文中使用的超参数,$N$ 是图像中关键点的总数,用于归一化。
Offset Loss (偏移量损失)
与 CornerNet 完全一致,用于补偿下采样带来的量化误差,采用 L1 损失。
\[L_{off}=\frac{1}{N}\sum_p |\hat{O}_{\tilde{p}}-(\frac{p}{R}-\tilde{p})|\]Size Loss (尺寸损失)
网络在预测的中心点位置上,直接回归该物体的长和宽 $s_k=(x_2^{(k)}-x_1^{(k)}, y_2^{(k)}-y_1^{(k)})$。这假设了中心点的特征已经包含了推断物体尺寸所需的全部信息。同样采用 L1 损失。为增加训练稳定性,一些实现会回归尺寸的对数 log(size)。
Process (推理过程)
CenterNet 的推理过程非常简洁:
- 对网络输出的热力图进行 3×3 的最大池化操作。这个操作的意义在于,如果一个像素的值不是其 3x3 邻域内的最大值,它就会被抑制。这等价于一个高效的、非参数化的 NMS,用于提取热力图上的局部峰值点。
- 对每个类别,提取前 K 个(如 100 个)置信度最高的峰值点作为候选中心点。
- 根据每个中心点位置上回归出的 offset 和 wh 值,计算出最终的边界框坐标。
其中 $(\delta \hat{x}_i, \delta \hat{y}_i)$ 是预测的偏移量, $(\hat{w}_i, \hat{h}_i)$ 是回归的宽高。

Conclusion & Comparison (总结与对比)
| 特性 | CornerNet | CenterNet (Objects as Points) |
|---|---|---|
| 物体表征 | 一对角点 (左上角, 右下角) | 单个中心点 |
| 核心机制 | 检测 + Embedding 配对 | 检测 + 直接回归属性 |
| 后处理 | 复杂的角点配对 + 传统 NMS | 无需配对,用 3x3 MaxPool 代替 NMS |
| 主要挑战 | 角点配对的效率和准确性,后处理复杂 | 同类物体的中心点在下采样后重叠,导致漏检 |
CornerNet 开创性地将目标检测转化为关键点检测问题,但其复杂的角点配对步骤成为了性能瓶颈。
CenterNet 则将这一思想推向了极致的简洁。通过将物体表征为单个中心点,它彻底摒弃了复杂的后处理,构建了一个更为优雅、高效的检测框架。虽然它存在中心点碰撞的问题,但在许多场景下,其在速度和简洁性上的优势是革命性的。这两项工作共同开启了 anchor-free 检测的新纪元,并深刻影响了后续如 TTFNet、FCOS 等一系列检测器的设计哲学。
Disadvantage (CenterNet 局限性)
- 在训练中,如果两个同类物体的 GT 中心点在下采样后重叠或挤在一起,CenterNet 会将它们视为一个物体来训练(因为只有一个中心点),这天然地造成了漏检。
- 同理,在推理时,如果两个同类物体的中心点在预测的热力图上重叠,网络也只能检测出一个。尽管论文指出其处理这种情况的能力优于 Faster R-CNN,但这仍是一个固有的设计局限。