当前的CV计算模式无论是早先的Machine Learning还是现在的Deep Learning解决方案,都是遵照着ML/DL expertise+Computation+Data的形式展开,其中ML/DL expertise代表着算法工程师们在特征工程、模型选择、模型设计、模型训练上的人为抉择,Computation是硬件承载这些方案的计算能力,而Data则是支撑所有解决方案进行的数据模块,包括参与训练的数据集和后续验证的数据集。但是在工业界,如果需要进行非常严谨的监督学习方法,针对Data而言,通常需要大量人力进行精细标注,成本高昂且周期较长。
而半监督学习的模式则是为弥补只有少数标注数据(labeled data)而有大量未标注数据的情况下,希望能和拥有全标注数据集的监督学习达到相同或类似学习效果的一类方法。当根据手头仅有的标注数据进行建模时,会对大量未标注但可被观测到的数据进行一些合理的利用与推测,这些做法通常基于以下经典假设:
聚类假设 cluster assumption:假设数据间具有相同的聚类结构,同一类数据会落入同一个聚类类别内。流形假设 manifold assumption:假设数据分布在低维流形上,相近的样本具有相似的预测结果。平滑性假设 smoothness assumption:若两个样本在高密度区域彼此接近,则其标签也应当一致或相近。
半监督学习有四种主要方法:
生成式方法 (generative methods):也称为自训练算法(self-training)。假设标注与未标注图片来源于同一个生成模型,将未标注数据看作模型参数的缺失,可用EM等方法进行估计。流程上,先用有标签数据训练一个分类器,然后用该分类器为无标签数据打伪标签(pseudo label)或软标签(soft label),再从中挑选高置信样本加入训练(需设定挑选准则,如阈值与类别均衡)。优点是实现简单;缺点是容易产生“确认偏差(confirmation bias)”。基于图的方法 (graph-based methods):构建出一个样本图,节点对应训练样本,边刻画样本相似性(如高斯核),根据“拉普拉斯平滑”等准则将标注信息在图上进行扩散(标签传播 Label Propagation / Label Spreading)。优点是充分利用几何结构;缺点是对大规模数据计算代价较高。低密度分割法 (low-density separation methods):强制分类边界穿过输入空间的低密度区域,如S3VMs / TSVMs。优点是符合“决策边界避开高密度”直觉;缺点是优化困难、对超参敏感。基于分歧的方法 (disagreement methods):自训练的扩展,训练多个学习器相互“教学”,如联合训练(co-training)(需多视图与条件独立性假设)与三重训练(tri-training)(弱化独立性假设)。优点是互补性强;缺点是实现复杂且易受错误传播影响。
半监督深度学习
整体上,半监督深度学习会以包含标注数据和未标注数据混合的数据作为训练集,其中后者在数量上通常远大于前者。整体思路有三类常见架构:
- 先用未标注数据预训练模型后,再用标注数据进行微调(fine-tuning),初始化方式可以:
- 无监督或自监督预训练:如自编码器、对比学习(SimCLR、MoCo 等)获取通用表征,再用标注数据微调;
- 伪有监督预训练:通过伪标签方法先把无标注数据打上标签再微调。
- 先用标注数据训练网络,再基于已有特征/预测做半监督:即伪标签式循环训练,从有标签数据中获得特征或分类器,再对无标签数据推断并筛选高置信样本加入训练。需注意阈值、类别分布对齐(distribution alignment)与去噪策略,避免错误累积。
- 让网络
work in semi-supervised fashion:在端到端训练中同时优化监督损失与无监督一致性损失(consistency regularization),常配合熵最小化、Ramp-up权重、EMA教师(Mean Teacher)等策略,以提升稳定性与样本效率。
伪标签
伪标签
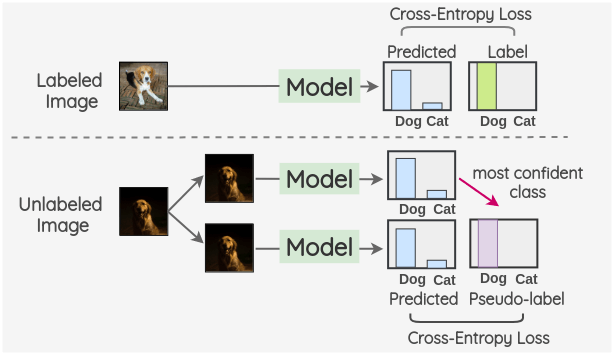
网络先对无标签数据进行预测,将预测结果作为该数据的伪标签使用。可使用如下总损失:
-
有标签部分:交叉熵损失 (L_{sup}=\frac{1}{ \mathcal{D}_L }\sum \operatorname{CE}(y, f_\theta(x))) - 无标签部分:对高置信的未标注样本 (x_u) 采用硬伪标签 (\hat{y}=\arg\max f_\theta(\text{weak}(x_u))), (L_{unsup}=\frac{1}{|\mathcal{D}U|}\sum{x_u: \max p>\tau} \operatorname{CE}(\hat{y}, f_\theta(\text{strong}(x_u))))
- 总损失:(L = L_{sup} + \alpha(t)\, L_{unsup}),其中 (\alpha(t)) 随时间
ramp-up从0增长,(\tau) 为置信度阈值(如 0.95)。
实务要点:控制类不平衡(可做分布对齐)、设定合理阈值与增广强度(weak/strong)、对伪标签stop-gradient,并配合EMA教师以缓解确认偏差。
Noisy Student
核心思想是训练两个不同的模型:teacher 和 student。Teacher 先在有标签数据上训练,然后为大规模无标签数据产生伪标签。将“标注数据 + 伪标注数据”合并训练 Student,并在 Student 端加入多种噪声(RandAugment、Dropout、Stochastic Depth 等),提升鲁棒性。训练完的 Student 作为新的 Teacher 重复该流程若干轮。该方法在 ImageNet 上验证有效,但需要足量无标签数据与较强的数据增强与正则化。
一致性正则化
这种模式使用的理念是:即使在添加了噪声之后,模型对未标记样本的预测也应保持一致。输入噪声可为图像增强、高斯噪声、Cutout/ColorJitter 等,结构噪声可为 Dropout/BN 抖动。无监督一致性损失常见为 (\operatorname{MSE}) 或 (\operatorname{KL}) 散度,并配合权重 ramp-up 控制训练早期的稳定性。
Ladder Networks For Semi-Supervised Learning
使用 Ladder Networks 的半监督学习。无监督预训练一般用重构样本进行训练,其编码(学习特征)倾向保留信息,而有监督学习希望聚焦判别信息。LadderNet 通过在各层引入“噪声编码—去噪解码”的重构支路与 skip connection,将“逐层去噪重构损失”与“顶层分类损失”联合优化,从而在特征学习与判别任务间取得平衡。
πmodel
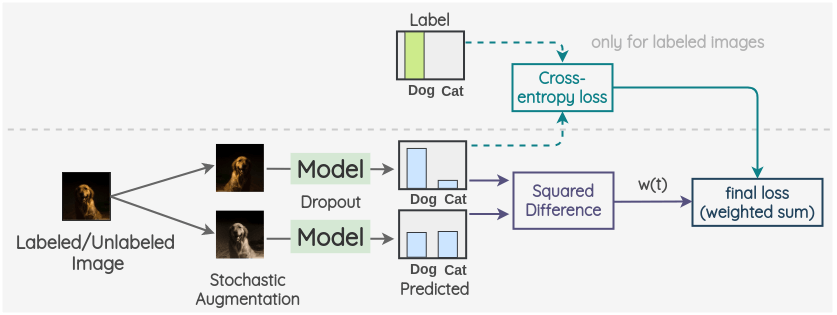
关键思想是为标记数据和未标记数据创建两个随机增强,并使用带有 dropout 的模型分别预测两份增强的输出。两者的平方差作为一致性损失;对有标签样本再加上交叉熵监督损失。总损失为两者加权和,权重 (w(t)) 常随时间增长。
Temporal Ensembling For Semi-Supervised Learning
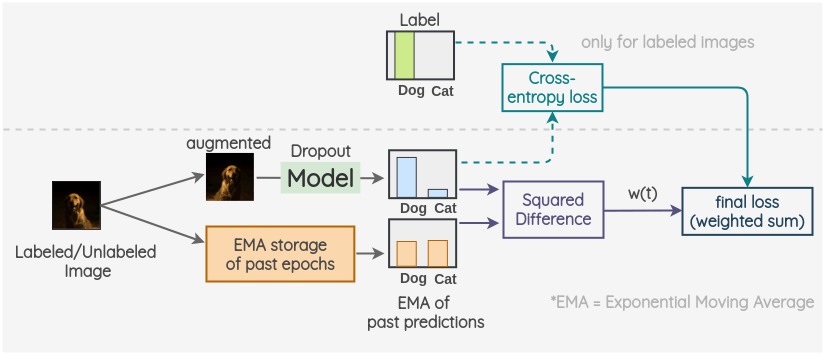
Temporal Ensembling 的目的是构造更稳定的目标值。πmodel 与 Temporal Ensembling 的代价函数与伪标签类似,但后者对“历史预测”取指数移动平均(EMA)作为目标,减少随机增广引入的抖动与噪声。
关键思想是对过去的预测使用 EMA 作为一个观测值;再对当前增强样本的预测与 EMA 目标最小化一致性损失(如 MSE/CE/KL)。对有标签样本同时优化交叉熵。最终损失是两者加权和,(w(t)) 控制一致性损失权重。
Mean teachers
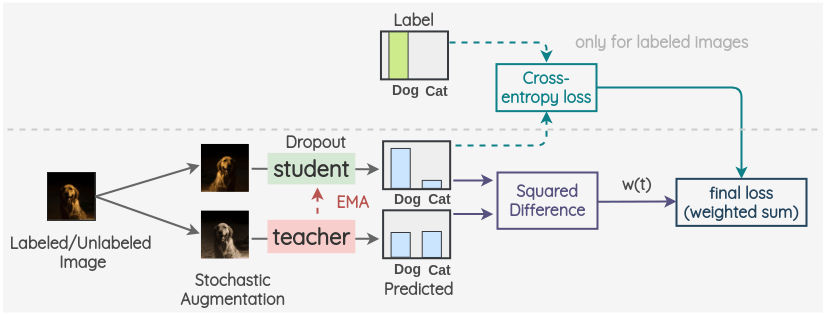
Mean Teacher 的核心在于教师权重 = 学生权重的 EMA。相比直接固定教师(如 Noisy Student 的迭代式 Teacher),Mean Teacher 在每步迭代都更新教师,能提供更平滑、更稳定的目标。对已标记/未标记图像分别做两种增广,最小化学生输出与教师输出之间的一致性损失(常用 MSE/CE/KL)。EMA 衰减系数(如 0.99~0.999)是关键超参。
Virtual Adversarial Training
这是一种基于“最坏方向扰动”的一致性正则。其核心是:在不改变标签的前提下,寻找能最大改变模型预测的微小扰动 (r_{adv})(受 (|r|\le \epsilon) 约束),并最小化扰动前后预测的 (\operatorname{KL}) 散度:
| [ r_{adv} = \arg\max_{|r|\le \epsilon} \operatorname{KL}(p(y | x,\theta)\,|\,p(y | x+r,\theta)), \quad L_{vat}=\operatorname{KL}(p(y | x,\theta)\,|\,p(y | x+r_{adv},\theta)). ] |
优点是无需标签即可沿“最敏感方向”平滑决策边界,常与其他一致性方法叠加使用。
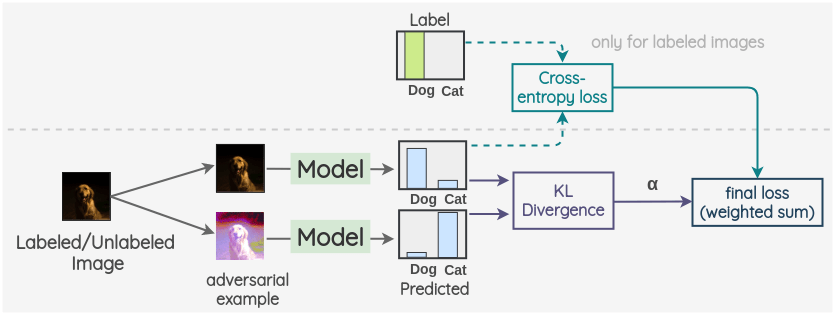
Unsupervised Data Augmentation
该方法结合“强增广 + 一致性”思想。对未标注样本,使用弱增广生成“目标分布”,再对强增广样本输出与其做 (\operatorname{KL}) 一致性;对有标注样本仍用交叉熵。实践中常配合RandAugment等策略,并使用Training Signal Annealing (TSA)抑制早期对易样本的过拟合,从而更好利用未标注数据。
混合方法
混合方法结合伪标签与一致性正则,以及其它辅助技巧来实现更高效的半监督性能。
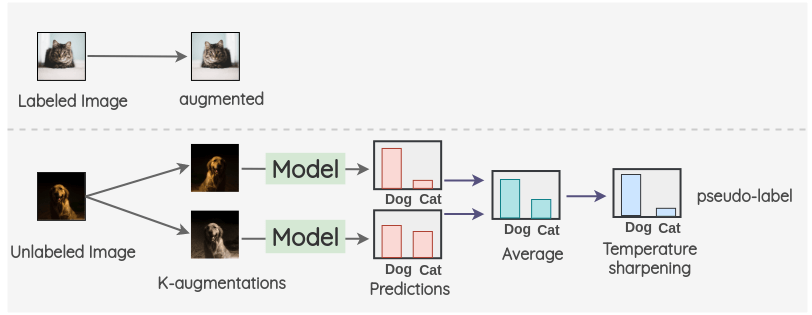
MixMatch
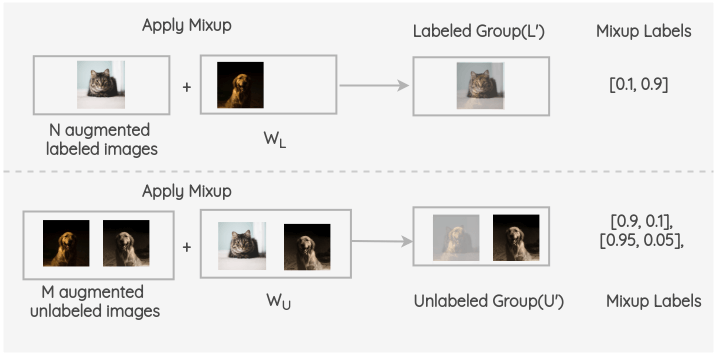
对于标记了的图像,我们创建一个增强图像。对于未标记的图像,我们创建 K 个增强图像,并对所有的 K 个图像进行模型预测。然后,对预测进行平均 + 温度缩放(sharpen)得到最终的伪标签(降低熵、避免过于平坦)。这个伪标签用于所有 K 个增强。
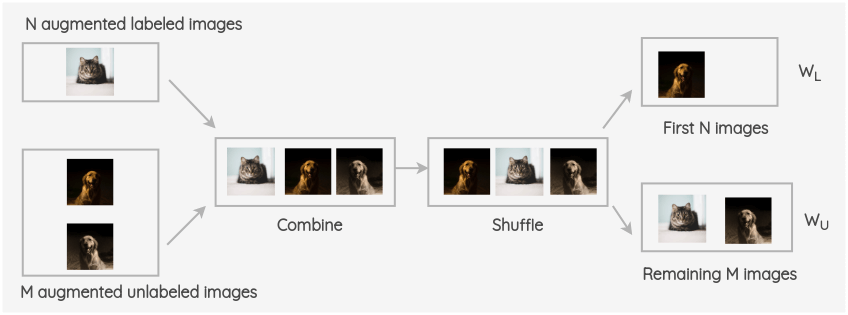
将增强的标记了的图像和未标记图像进行合并,并对整组图像进行打乱。然后取该组的前 N 幅图像为 W~L~,其余 M 幅图像为 W~U~。
现在,在增强了的有标签的 batch 和 W~L~之间进行 Mixup;同样,对 M 个增强过的未标记组和 W~U~中的图像进行 Mixup。由此得到最终的有标签组与无标签组。
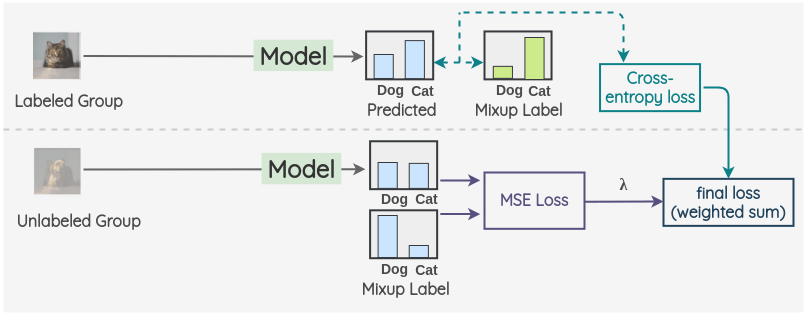
对于有标签的组,使用 ground truth 混合标签进行模型预测并计算交叉熵损失;对于无标签组,计算模型预测与混合伪标签的 MSE 或 CE 损失。两项取加权和,用 (\lambda) 加权无监督项。超参包括K、温度 T、\lambda 等。
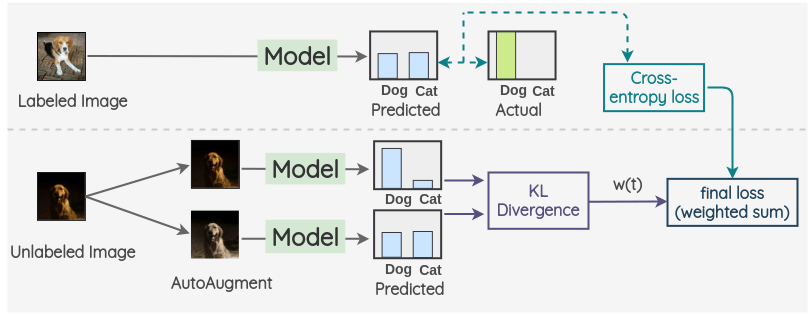
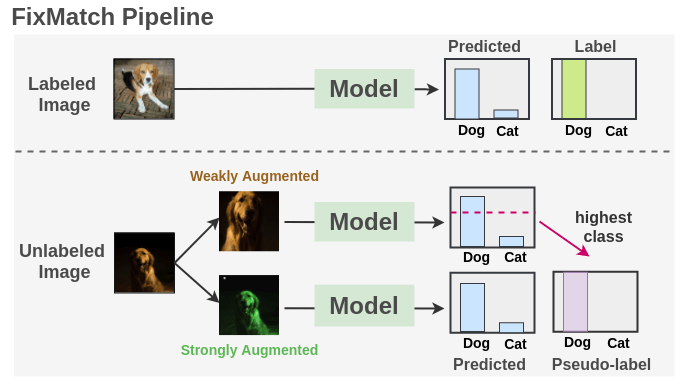
FixMatch
结合了伪标签与一致性正则,极大地简化了整个方法,并在多项基准上取得 SOTA:
- 对未标注样本先做
弱增广获得预测,若最大类概率大于阈值 (\tau)(如 0.95),则取其硬伪标签; - 再对同一图像做
强增广(如 RandAugment/CTAugment/Cutout),用交叉熵使强增广预测对齐弱增广的伪标签; - 总损失:(L=L_{sup}+\lambda_u L_{unsup}),其中
\lambda_u为无监督权重;常配合EMA Teacher、类别分布对齐与置信度校准进一步提升稳定性。
任务扩展与实践建议(简要)
- 目标检测/实例分割:
STAC、Unbiased Teacher、SoftTeacher等方法将 FixMatch/Teacher-Student 思想迁移到检测,核心在于高置信伪标签、强增广与教师-学生一致; - 语义分割:
Cross Pseudo Supervision (CPS)通过双分支互为教师生成伪标签,提升边界与结构一致性; - 实践要点:确保未标注数据“域一致”,设定合适的
弱/强增广组合,使用阈值+分布对齐抑制伪标签偏差,ramp-up无监督权重,采用EMA teacher平滑目标,关注类别不平衡与长尾问题。
Reference
- Semi-Supervised Learning, Oliver Chapelle, et al
- Phrase-Based & Neural Unsupervised Machine Translation, Guillaume Lample, Myle Ott, Alexis Conneau, Ludovic Denoyer, Marc’Aurelio Ranzato
- Introduction to Semi-Supervised Learning Synthesis Lectures on Artificial Intelligence and Machine Learning, Xiaojin Zhu, Andrew B.Goldberg
- 计算机视觉中的半监督学习
- Mean Teachers (Tarvainen & Valpola, 2017)
- VAT (Miyato et al., 2018)
- MixMatch (Berthelot et al., 2019)
- UDA (Xie et al., 2019)
- FixMatch (Sohn et al., 2020)