1 - Intro
Meta的Llama2是当前开源状态最好又可以作为效果标杆的一个LLM模型,但它的官方口径好像也是个半开源,即只有inference而没有train,但是从它的模型结构和部分处理逻辑上,还是具有很高的参考价值。
2 - Process
关于通用的LLM对于文本的处理一般是以下流程:
输入数据:LLM的输入数据是一段文本,可以是一个句子或一段话。文本通常被表示成单词或字符的序列。
[君不见黄河之水天上来,奔流到海不复回。君不见高堂明镜悲白发,朝如青丝暮成雪。...五花马、千金裘,呼儿将出换美酒,与尔同销万古愁]
Tokenization:之后需要将文本进行Tokenization,将其切分成单词或字符,形成Token序列。之后再将文本映射成模型可理解的输入形式,将文本序列转换为整数索引序列(这个索引就是单词或字符在语料库中的index),这个过程通常由一些开源的文本Tokenzier工具,如sentencepiece等来处理
序列化->
['BOS','君','不','见','黄','河','之','水','天','上','来',',' ,'奔','流','到'...'与','尔','同','销','万','古','愁','EOS']
假设语料库索引化->
['BOS','10','3','67','89','21','45','55','61','4','324','565' ,'789','6567','786'...'7869','9','3452','563','56','66','77','EOS']
Embedding:文本信息经过Tokenization之后变成了token序列,而Embedding则继续将每个Token映射为一个实数向量,为Embeding Vector。
'BOS'-> [p_{00},p_{01},p_{02},...,p_{0d-1}]
'10' -> [p_{10},p_{11},p_{12},...,p_{1d-1}]
'3' -> [p_{20},p_{21},p_{22},...,p_{2d-1}]
...
'EOS'-> [p_{n0},p_{n1},p_{n2},...,p_{nd-1}]
位置编码:对于Token序列中的每个位置,添加位置编码(Positional Encoding)向量,以提供关于Token在序列中位置的信息。位置编码是为了区分不同位置的Token,并为模型提供上下文关系的信息。
[p_{00},p_{01},p_{02},...,p_{0d-1}] [pe_{00},pe_{01},pe_{02},...,pe_{0d-1}]
[p_{10},p_{11},p_{12},...,p_{1d-1}] [pe_{10},pe_{11},pe_{12},...,pe_{1d-1}]
[p_{20},p_{21},p_{22},...,p_{2d-1}] + [pe_{20},pe_{21},pe_{22},...,pe_{2d-1}]
... ...
[p_{n0},p_{n1},p_{n2},...,p_{nd-1}] [pe_{n0},pe_{n1},pe_{n2} ,...,pe_{nd-1}]
Transformer :在生成任务中,以llama为代表的类GPT结构的模型只需要用到Transformer 的decoder阶段,即Decoder-Only。
自回归生成:在生成任务中,使用自回归(Autoregressive)方式,即逐个生成输出序列中的每个Token。在解码过程中,每次生成一个Token时,使用前面已生成的内容作为上下文,来帮助预测下一个Token。
model = LLaMA2()
def generate(inputs, n_tokens_to_generate):
for _ in range(n_tokens_to_generate):
# auto-regressive decode loop
output = model(inputs)
# model forward pass
next = np.argmax(output[-1])
# greedy sampling
inputs.append(next)
# append prediction to input
return inputs[len(inputs) - n_tokens_to_generate :]
# only return generated tokens
input = [p0, p1,p2]
#对应['BOS','君','不']
output_ids = generate(input, 3)
# 假设生成 ['p3','p4','p5']
output_ids = decode(output_ids)
# 通过Tokenization解码
output_tokens = [vocab[i] for i in output_ids]
# "见" "黄" "河"
输出处理:生成的Token序列通过一个输出层,通常是线性变换加上Softmax函数,将每个位置的概率分布转换为对应Token的概率。根据概率,选择概率最高的Token或者作为模型的预测结果。或者其他的的方法生成next token ,比如:
def sample_top_p(probs, p):
# 从给定的概率分布中采样一个token,
# 采样的方式是先对概率进行排序,然后计算累积概率,
# 然后选择累积概率小于p的部分,
# 最后在这部分中随机选择一个token。
probs_sort, probs_idx = torch.sort(probs, dim=-1, descending=True)
# 给定的概率降序排序
probs_sum = torch.cumsum(probs_sort, dim=-1)
# 从第一个元素开始,依次将序列中的每个元素与前面所有元素的和相加得到的
mask = probs_sum - probs_sort > p
probs_sort[mask] = 0.0
# 将累计和减去当前值>p的地方全部置0,留下来的就是概率较大的
probs_sort.div_(probs_sort.sum(dim=-1, keepdim=True))
# 归一化下
next_token = torch.multinomial(probs_sort, num_samples=1)
# 从归一化之后的样本抽取一个样本
next_token = torch.gather(probs_idx, -1, next_token)
# 从原始probs_idx找到next_token所对应的index
return next_token
3 - Architcture
Llama3这样的主流LLM模型尝尝是沿用gpt结构,基于transformer来构建,LLM这种生成式的任务是根据给定输入文本序列的上下文信息预测下一个单词或token,所以LLM模型通常只需要使用到Transformer Decoder部分,而所谓Decoder相对于Encoder就是在计算Q*K时引入了Mask以确保当前位置只能关注前面已经生成的内容。
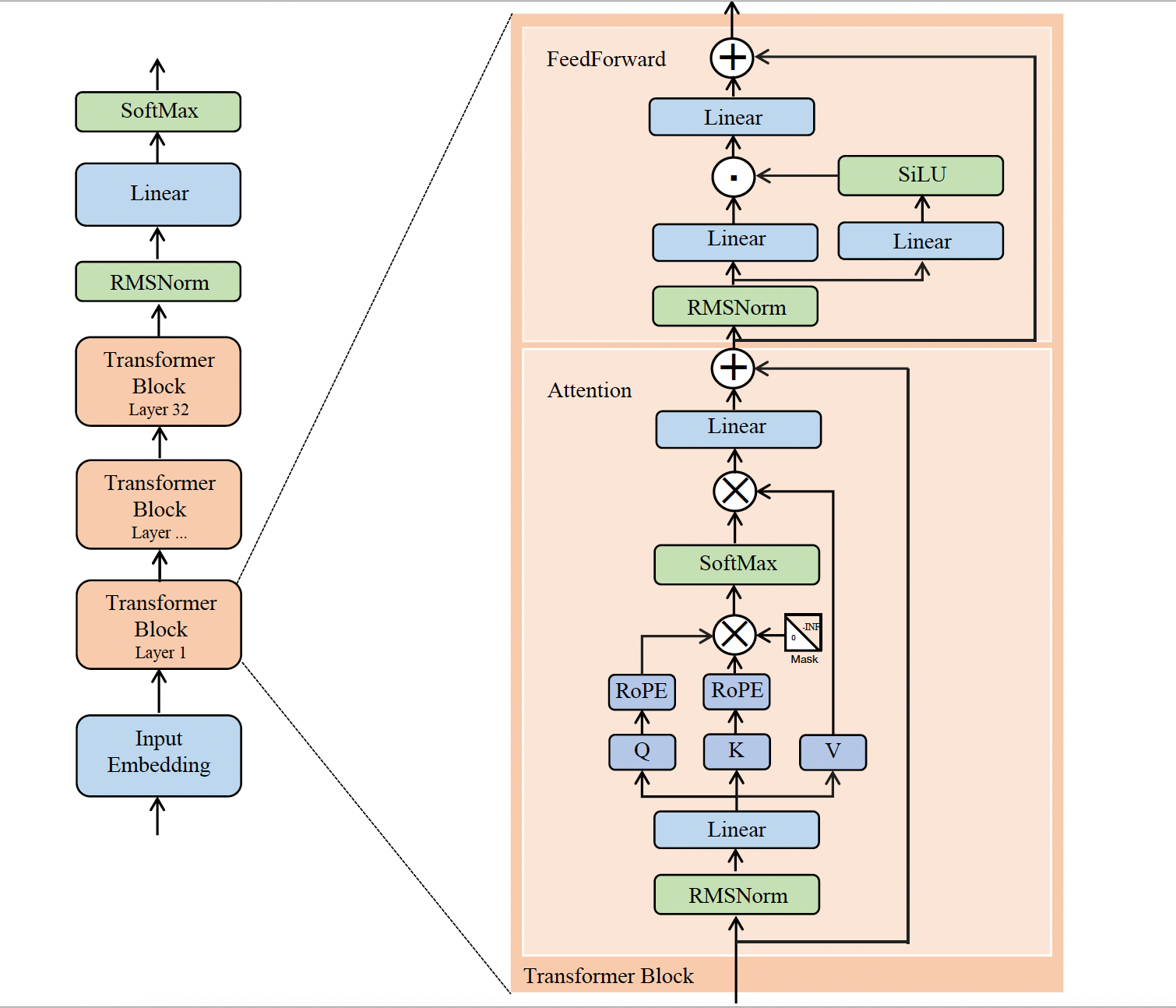
Llama2主要由32个 Transformer Block 组成,不同之处主要包括以下几点:
- 前置的RMSNorm层;
- Q在与K相乘之前,先使用RoPE进行位置编码;
- K V Cache,并采用Group Query Attention;
- FeedForward层。
3.1 - RMSNorm
Transformer中的Normalization层一般都是采用LayerNorm来对Tensor进行归一化,LayerNorm可以被表达成: \(\begin{align} & LayerNorm: \nonumber \\ & y=\frac{x-E[x]}{\sqrt}*\gamma+\beta \nonumber \\ & E[x]=\frac{1}{N}\sum^N_{i=1}x_i \nonumber \\ & Var[x]=\frac{1}{N}\sum^N_{i=1}(x_i-E[x])^2 \nonumber \end{align}\) 而RMSNorm则是LayerNorm的变体,省去了求均值过程,也没有了求偏置$\beta$,即: \(\begin{align} & RMSNorm: \nonumber \\ & y=\frac{x}{\sqrt{Mean(x^2)+\epsilon}}*\gamma \nonumber \\ & Mean(x^2)=\frac{1}{N}\sum^N_{i=1}x^2_i \nonumber \end{align}\) 其中$\beta$和$\gamma$为可学习参数
# RMSNorm
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
self.eps = eps # ε
self.weight = nn.Parameter(torch.ones(dim)) #可学习参数γ
def _norm(self, x):
# RMSNorm
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
output = self._norm(x.float()).type_as(x)
return output * self.weight