Brief
DDPM的本质作用,就是学习训练数据的分布,产出尽可能符合训练数据分布的真实图片。
当喂给模型一些赛博朋克风格图像,让它学会类似风格图像的信息,再喂给模型一个随机噪音,让根据先前学到的信息再生产一个赛博朋克风格的图像。同理,喂进去的图像可以是人脸,希望模型能从噪声中重建一张人脸图像。
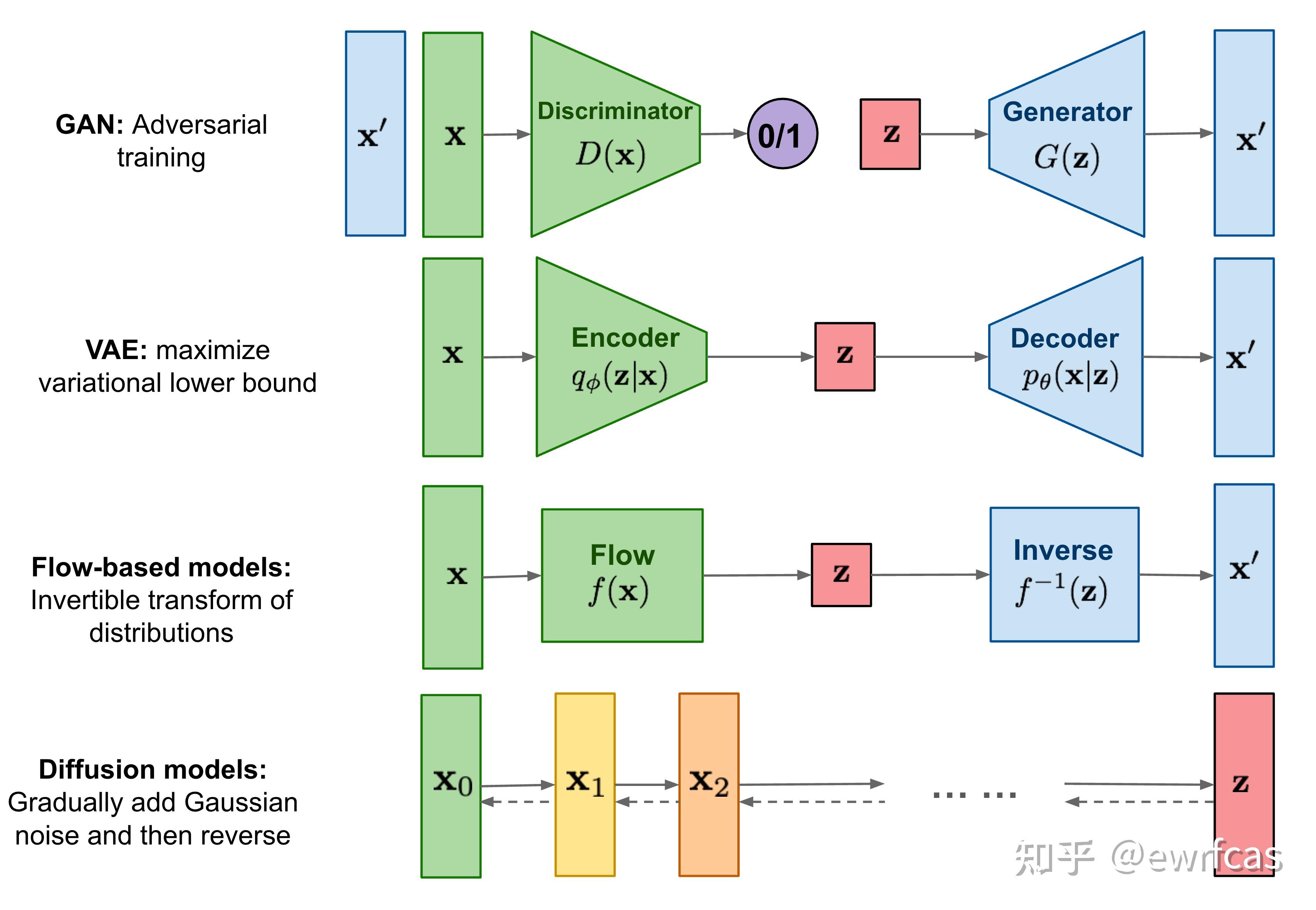
以下是各类生成模型的简单对比,其中diffusion model和GAN最大区别就是,虽然都是给定噪声$x_T$生成图片$x_0$,但是diffusion model中这二者是同纬度的。
VAE
变分自编码器是一种生成模型,它“提供潜在空间中观察结果的概率描述”。简单地说,这意味着VAE将潜在属性存储为概率分布。标准的自动编码器包括2个相似的网络,一个编码器和一个解码器。编码器接受输入并将其转换为更小的表示形式,解码器可以使用该表示形式将其转换回原始输入。变分自编码器具有连续的潜在空间,这样可以使随机采样和插值更加方便。为了实现这一点,编码器的隐藏节点不输出编码向量,而是输出两个大小相同的向量: 一个均值向量和一个标准差向量。每一个隐藏的节点都认为自己是高斯分布的。我们从编码器的输出向量中采样送入解码器, 这个过程就是随机生成。这意味着即使对于相同的输入,当平均值和标准差保持不变时,实际的编码在每一次传递中都会有所不同。
训练过程是最小化重构损失(输出与输入的相似程度)和潜在损失(隐藏节点与正态分布的接近程度)。潜在损失越小,可以编码的信息就越少,这样重构损失就会增加,所以在潜在损失和重建损失之间是需要进行进行权衡的。当潜在损耗较小时,生成的图像与训练的的图像会过于相似,效果较差。在重构损失小的情况下,训练时的重构图像效果较好,但生成的新图像与重构图像相差较大,所以需要找到一个好的平衡。
VAE的一个主要缺点是它们生成的输出模糊, 这是由数据分布恢复和损失函数计算的方式造成的。
Flow Model
基于流的生成模型是精确的对数似然模型,它将一堆可逆变换应用于来自先验的样本,以便可以计算观察的精确对数似然。与前两种算法不同,该模型显式地学习数据分布,因此损失函数是负对数似然。流模型$f$被构造为一个将高维随机变量$x$映射到标准高斯潜变量$z$的可逆变换, 它可以是任意的双射函数,并且可以通过叠加各个简单的可逆变换来形成。
流模型可逆但计算效率并不高,基于流的模型生成相同分辨率的图像所需时间是GAN的几倍。
Diffusion Model
Diffusion Model的灵感来自 non-equilibrium thermodynamics (非平衡热力学), 理论首先定义扩散步骤的马尔可夫链,缓慢地将随机噪声添加到数据中,然后学习逆向扩散过程以从噪声中构造所需的数据样本。与VAE或流模型不同,扩散模型是通过固定过程学习,并且隐空间具有比较高的维度。
扩散模型
扩散模型(Diffusion Model)用于生成与训练数据相似的数据。从根本上说,Diffusion Model的工作原理是通过连续添加高斯噪声来破坏训练数据,然后通过学习反转的去噪过程来恢复数据。训练后,我们可以使用 Diffusion Model将随机采样的噪声传入模型中,通过学到的去噪过程来生成数据。
更具体地说,扩散模型是一种隐变量模型(latent variable model),使用马尔可夫链(Markov Chain)映射到隐空间(latent space)。通过马尔科夫链,在每一个时间步$t$中逐渐将噪声添加到数据$x_i$中。Diffusion Model分为正向的扩散过程和反向的逆扩散过程。
前向过程Diffusion
前向diffusion过程即向原始风格图片上增加噪声。给定真实图片$x_0\thicksim q(x)$,diffusion前向过程通过$T$次累计对其添加高斯噪声,得到$x_0, x_1,…,x_T$,然后给定一系列高斯分布方差的超参数${\beta_t \in (0, 1)}^T_{t=1}$,前向过程由于每个时刻$t$只与$t−1$时刻有关,所以也可以看做马尔科夫过程:
\[q(x_t|x_{t-1})=\mathcal{N}(x_t;\sqrt{1-\beta_t}x_{t-1}, \beta_tI)\\q(x_{1:T}|x_0)=\prod^T_{t=1}q(x_t|x_{t-1})\]其中实际上$\beta_t$随着$t$的增大递增,术语均值系数,当$t\rightarrow\infty$,$x_T$就是完全的高斯噪声。
重参数 Reparameterization Trick
重参数技术的出现是因为要从某个分布中随机采样样本的过程无法反向传递(如diffusion中通过高斯噪声采样得到$x_t$),因此需要重参数的手段使得这个过程可微,常用的方法是把随机性通过一个独立的随机变量$\epsilon$引导过去。如果要从高斯分布$z\thicksim\mathcal{N}(z;\mu_\theta,\sigma^2_\theta I)$采样一个$z$,我们可以写成:
\[z=\mu_\theta+\sigma_\theta\odot\epsilon\\\epsilon\thicksim\mathcal{N}(0, I)\]这里的$\mu_\theta$和$\sigma_\theta^2$是由参数$\theta$的网络推断得到,整个采样过程可导了,随机性转移到了$\epsilon$上了。
任意时刻$x_t$的表示
对于任意时刻$t$的生成图$x_t$,可以用初始图$x_0$和分布超参$\beta$表示,首先假设$\alpha_t=1-\beta_t$,并且$\bar{\alpha}t=\prod^T{i=1}\alpha_i$,展开$x_t$可得到:
\[\begin{align} x_t&=\sqrt{a_t}x_{t-1}+\sqrt{1-\alpha_t}z_{1} \quad \mathrm{where}\quad z_{1},z_{2},...\sim\mathcal{N}(0,\mathbf{I});\\ &=\sqrt{a_t}(\sqrt{a_{t-1}}x_{t-2}+\sqrt{1-\alpha_{t-1}}z_{2})+\sqrt{1-\alpha_t}z_{1}\\ &=\sqrt{a_t a_{t-1}}x_{t-2}+(\sqrt{a_t(1-\alpha_{t-1})}z_{2}+\sqrt{1-\alpha_t}z_{1})\\ &=\sqrt{a_t a_{t-1}}x_{t-2}+\sqrt{1-\alpha_{t}\alpha_{t-1}}\overline{z}_{2} \quad \mathrm{where}\quad\overline{z}_{2}\sim\mathcal{N}(0,\mathbf{I});\\ &=...\\ &=\sqrt{\overline{\alpha}_t}x_0+\sqrt{1-\overline{\alpha}_t}\overline{z}_t\end{align}\]由于独立高斯分布的可加性,即$\mathcal{N}(0, \sigma^2_1 I)+\mathcal{N}(0, \sigma^2_2 I)\thicksim\mathcal{N}(0, (\sigma^2_1+\sigma^2_2) I)$,所以:
\[\begin{align} &\sqrt{a_t(1-\alpha_{t-1})}z_{2}\sim\mathcal{N}(0,a_t(1-\alpha_{t-1})\mathbf{I})\\ &\sqrt{1-\alpha_t}z_{1}\sim\mathcal{N}(0,(1-\alpha_t)\mathbf{I})\\ &\sqrt{a_t(1-\alpha_{t-1})}z_{2}+\sqrt{1-\alpha_t}z_{1}\sim\mathcal{N}(0,[\alpha_t(1-\alpha_{t-1})+(1-\alpha_t)]\mathbf{I})\\ &=\mathcal{N}(0,(1-\alpha_t \alpha_{t-1})\mathbf{I}) \end{align}\]因此可以混合两个高斯分布得到标准差为$\sqrt{1-\alpha_t\alpha_{t-1}}$的混合高斯分布。任意时刻的$x_t$满足$q(x_t\vert x_0)=\mathcal{N}(x_t;\sqrt{\bar{\alpha}_t}x_0,(1-\bar{\alpha}_t)I)$。
对于每次diffusion过程中都乘以$\sqrt{1-\beta_t}$的行为,一来是作为权重保证其$< 1$,二来是为了当$T\rightarrow\infty,x_T\thicksim\mathcal{N}(0,I)$时,能保证$x_T$最后收敛到方差是1的标准高斯分布。
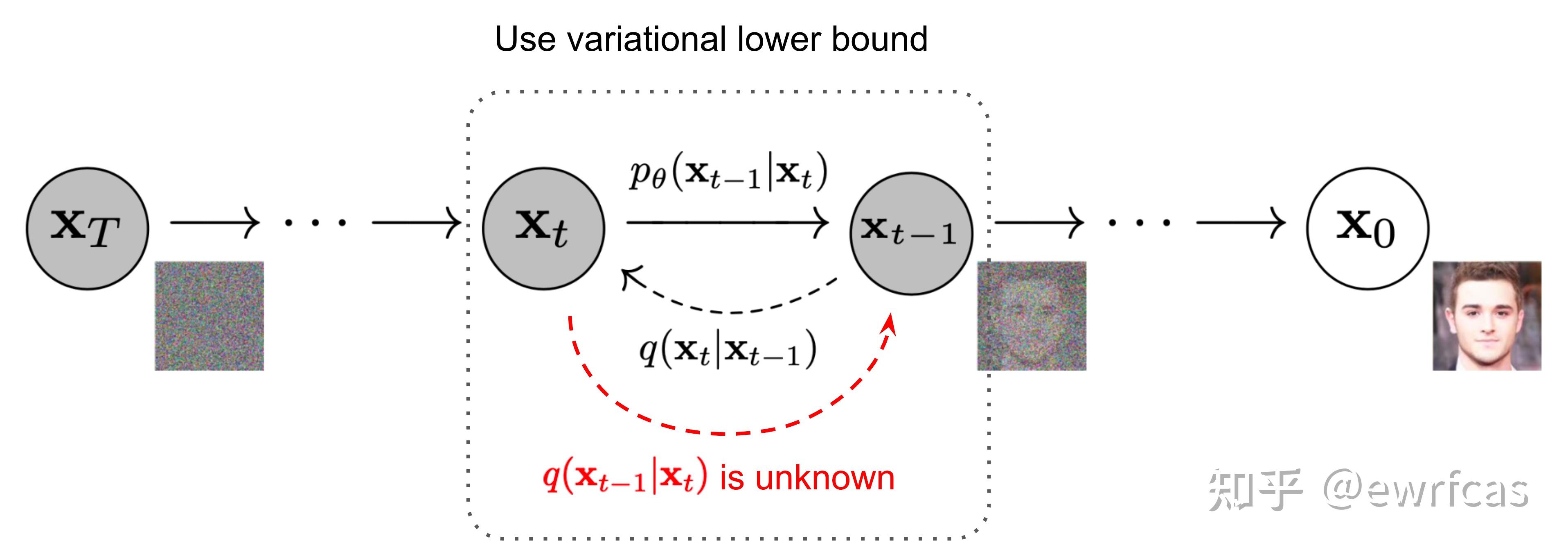
逆向过程Denoise
逆向过程denoise就是diffusion去噪推断的过程,如果逐步得到逆转后的分布$q(x_{t-1}\vert x_t)$,就可以从完全的标准高斯分布$x_T\thicksim\mathcal{N}(0,I)$还原出原图分布$x_0$。然而我们无法简单推断$q(x_{t-1}\vert x_t)$,因此使用深度学习模型(参数为$\theta$,目前主流是U-Net+attention的结构)去预测这样的一个逆向的分布$p_\theta$:
\[p_\theta(X_{0:T})=p(x_T)\prod^T_{t=1}p_\theta(x_{t-1}|x_t)\\p_\theta(x_{t-1}|x_t)=\mathcal{N}(x_{t-1};\mu_\theta(x_t,t),\sum_\theta(x_t,t))\]虽然无法得到逆转后的分布$q(x_{t-1}\vert x_t)$,但是如果知道$x_0$,可以通过贝叶斯公式得到$q(x_{t-1}\vert x_t,x_0)$为:
\[q(x_{t-1}|x_t,x_0)=\mathcal{N}(x_{t-1};\tilde{\mu}(x_t,x_0),\tilde{\beta}_tI)\]过程如下:
\[\begin{align} q(x_{t-1}|x_t,x_0)&=q(x_t|x_{t-1},x_0)\frac{q(x_{t-1}|x_0)}{q(x_t|x_0)}\\ &\propto \exp\Bigg(-\frac{1}{2}\Big(\frac{(x_t-\sqrt{\alpha_t}x_{t-1})^2}{\beta_t}+\frac{(x_{t-1}-\sqrt{\overline{\alpha}_{t-1}}x_{0})^2}{1-\overline{a}_{t-1}}-\frac{(x_t-\sqrt{\overline{\alpha}_t}x_{0})^2}{1-\overline{a}_t}\Big)\Bigg)\\ &=\exp\Bigg(-\frac{1}{2}\Big(\underbrace{(\frac{\alpha_t}{\beta_t}+\frac{1}{1-\overline{\alpha}_{t-1}})x^2_{t-1}}_{x_{t-1}方差}-\underbrace{(\frac{2\sqrt{\alpha_t}}{\beta_t}x_t+\frac{2\sqrt{\overline{a}_{t-1}}}{1-\overline{\alpha}_{t-1}}x_0)x_{t-1}}_{x_{t-1}均值}+\underbrace{C(x_t,x_0)}_{与x_{t-1}无关}\Big)\Bigg)\end{align}\]巧妙地把所有逆向都变回了前向计算。整理一下方差和均值有:
\[\begin{align} &\frac{1}{\sigma^2}=\frac{1}{\tilde{\beta}_t}=(\frac{\alpha_t}{\beta_t}+\frac{1}{1-\overline{\alpha}_{t-1}});\quad \tilde{\beta}_t=\frac{1-\overline{\alpha}_{t-1}}{1-\overline{\alpha}_t}\cdot\beta_t~\tag{8-1}\\ &\frac{2\mu}{\sigma^2}=\frac{2\tilde{\mu}_t(x_t,x_0)}{\tilde{\beta}_t}=(\frac{2\sqrt{\alpha_t}}{\beta_t}x_t+\frac{2\sqrt{\overline{a}_{t-1}}}{1-\overline{\alpha}_{t-1}}x_0);\\&\tilde{\mu}_t(x_t,x_0)=\frac{\sqrt{a}_t(1-\overline{\alpha}_{t-1})}{1-\overline{\alpha}_t}x_t+\frac{\sqrt{\overline{\alpha}_{t-1}}\beta_t}{1-\overline{\alpha}_t}x_0 \end{align}\]然后已知:$x_0=\frac{1}{\sqrt{\bar{\alpha}t}}(x_t-\sqrt{1-\bar{\alpha}_t}\bar{z}_t)$,带入后得到$\bar{\mu}_t=\frac{1}{\sqrt{\alpha_t}}(x_t-\frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}}\bar{z}_t)$,其中高斯分布$\bar{z}_t$为深度模型所预测的噪声(用于去噪),可看做为$z\theta(x_t,t)$,得到:
\[\mu_t(x_t,t)=\frac{1}{\sqrt{\alpha_t}}(x_t-\frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}}z_\theta(x_t, t))\]总结DDPM每一步的推断:
- 每个时间步time_step通过$x_t$和$t$来预测高斯噪声$z_\theta(x_t,t)$,随后得到均值$\mu_\theta(x_t,t)$;
- 得到方差$\sum_\theta(x_t,t)$,DDPM中使用untrained分布$\sum_\theta(x_t,t)=\tilde{\beta}t$,并且认为$\tilde{\beta}_t=\beta_t$和$\tilde{\beta}_t=\frac{1-\bar{\alpha}{t-1}}{1-\bar{\alpha}t}\beta_t$结果近似,在GLIDE中则是根据网络预测trainable方差$\sum\theta(x_t,t)$;
- 得到$q(x_{t-1}\vert x_t)$,利用重参数得到$x_t-1$
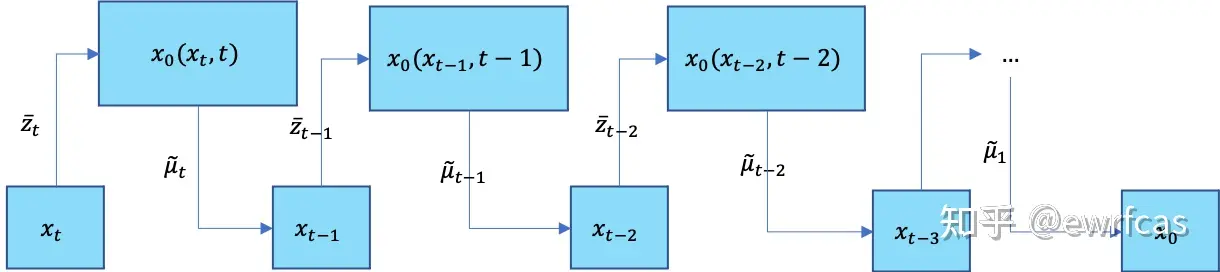
训练
由上述diffusion和denoise的过程,那么diffusion model的训练目的就是得到合适的高斯分布均值$\mu_\theta(x_t,t)$和方差$\sum_\theta(x_t, t)$,通过对真实数据分布下,最大化模型预测分布的对数似然,即优化在$x_0\thicksim q(x_0)$下的$p_\theta(x_0)$交叉熵:
\[\mathcal{L}=\mathbb{E}_q(x_0)[-\log p_\theta(x_0)]\]得到:
\[\small\begin{align} -\log p_\theta(x_0)&\leq-\log p_\theta(x_0)+D_{KL}(q(x_{1:T}|x_0)||p_\theta(x_{1:T}|x_0))\\ &=-\log p_\theta(x_0)+\mathbb{E}_{q(x_{1:T}|x_0)}\left[\log\frac{q(x_{1:T}|x_0)}{p_\theta(x_{0:T})/p_\theta(x_0)}\right];\quad\mathrm{where}\quad p_\theta(x_{1:T}|x_0)=\frac{p_\theta(x_{0:T})}{p_\theta(x_0)}\\ &=-\log p_\theta(x_0)+\mathbb{E}_{q(x_{1:T}|x_0)}\left[\log\frac{q(x_{1:T}|x_0)}{p_\theta(x_{0:T})}+\underbrace{\log p_\theta(x_0)}_{与q无关}\right]\\ &=\mathbb{E}_{q(x_{1:T}|x_0)}\left[\log\frac{q(x_{1:T}|x_0)}{p_\theta(x_{0:T})}\right] \end{align}\]对左右取期望,利用到重积分中的Fubini定理:
\[\small\mathcal{L}_{VLB}=\underbrace{\mathbb{E}_{q(x_0)}\left(\mathbb{E}_{q(x_{1:T}|x_0)}\left[\log\frac{q(x_{1:T}|x_0)}{p_\theta(x_{0:T})}\right]\right)=\mathbb{E}_{q(x_{0:T})}\left[\log\frac{q(x_{1:T}|x_0)}{p_\theta(x_{0:T})}\right]}_{Fubini定理}\geq\mathbb{E}_{q(x_0)}[-\log p_\theta(x_0)]\]能够最小化$\mathcal{L}_{VLB}$即可最小化目标损失$\mathcal{L}$,另一方面通过Jensen不等式也可以得到一样的目标:
\[\begin{align} \mathcal{L}&=\mathbb{E}_{q(x_0)}[-\log p_\theta(x_0)]\\ &=-\mathbb{E}_{q(x_0)}\log\left(p_\theta(x_0)\cdot\int p_\theta(x_{1:T})dx_{1:T}\right)\\ &=-\mathbb{E}_{q(x_0)}\log\left(\int p_\theta(x_{0:T})dx_{1:T}\right)\\ &=-\mathbb{E}_{q(x_0)}\log\left(\int q(x_{1:T}|x_0)\frac{p_\theta(x_{0:T})}{ q(x_{1:T}|x_0)}dx_{1:T}\right)\\ &=-\mathbb{E}_{q(x_0)}\log\left(\mathbb{E}_{q(x_{1:T}|x_0)}\frac{p_\theta(x_{0:T})}{ q(x_{1:T}|x_0)}\right)\\ &\leq-\mathbb{E}_{q(x_{0:T})}\log\frac{p_\theta(x_{0:T})}{ q(x_{1:T}|x_0)};\qquad\qquad Jensen不等式\\ &=\mathbb{E}_{q(x_{0:T})}\log\frac{q(x_{1:T}|x_0)}{p_\theta(x_{0:T})}=\mathcal{L}_{VLB} \end{align}\]进一步对$\mathcal{L}_{VLB}$推导,可以得到熵和多个KL散度的累加:
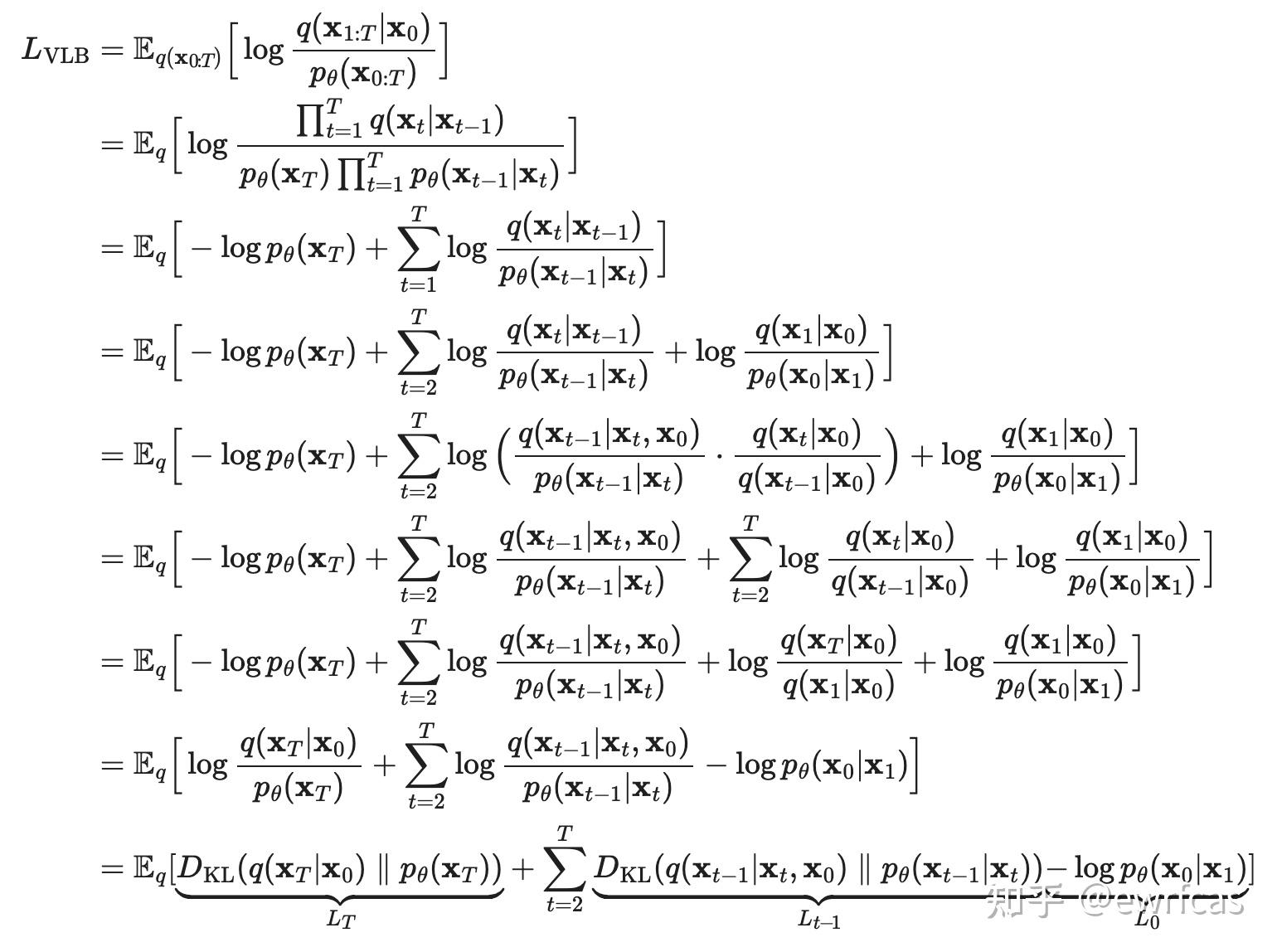
也可以写成:
\[\begin{align} &\mathcal{L}_{VLB}=L_T+L_{T-1}+...+L_0\\ &L_T=D_{KL}(q(x_T|x_0)||p_\theta(x_T))\\ &L_t=D_{KL}(q(x_t|x_{t+1},x_0)||p_\theta(x_t|x_{t+1}));\qquad 1\leq t \leq T-1\\ &L_0=-\log p_\theta(x_0|x_1)\\ \end{align}\]其中前向$q$没有可学习参数,而$x_T$是纯高斯噪声,$L_T$可以看做常量忽略,$L_t$则可以看做拉近两个高斯分布,根据多元高斯分布的KL散度求解:
\[L_t=E_q[\frac{1}{2||\sum_\theta(x_t,t)||^2_2}||\tilde{\mu}_t(x_t,x_0)-\mu_\theta(x_t,t)||^2]+C\]带入可有:
\[\begin{align} L_t&=\mathbb{E}_{x_0,\overline{z}_t}\left[\frac{1}{2||\Sigma_\theta(x_t,t)||_2^2}||\tilde{\mu}_t(x_t,x_0)-\mu_\theta(x_t,t)||^2\right]\\ &=\mathbb{E}_{x_0,\overline{z}_t}\left[\frac{1}{2||\Sigma_\theta(x_t,t)||_2^2}||\frac{1}{\sqrt{\overline{a}_t}}(x_t-\frac{\beta_t}{\sqrt{1-\overline{a}_t}}\overline{z}_t)-\frac{1}{\sqrt{\overline{a}_t}}(x_t-\frac{\beta_t}{\sqrt{1-\overline{a}_t}}z_\theta(x_t,t))||^2\right]\\ &=\mathbb{E}_{x_0,\overline{z}_t}\left[\frac{\beta_t^2}{2\alpha_t(1-\overline{\alpha}_t||\Sigma_\theta||_2^2)}||\overline{z}_t-z_\theta(x_t,t)||^2\right]\\ &=\mathbb{E}_{x_0,\overline{z}_t}\left[\frac{\beta_t^2}{2\alpha_t(141-\overline{\alpha}_t||\Sigma_\theta||_2^2)}||\overline{z}_t-z_\theta(\sqrt{\overline{\alpha}_t}x_0+\sqrt{1-\overline{\alpha}_t}\overline{z}_t,t)||^2\right] \end{align}\]因此diffusion训练的本质就是去学习高斯噪声$\overline{z}t$和$z\theta$之间的MSE,DDPM将loss进一步简化为:
\[L_t^{simple}=\mathbb{E}_{x_0,\overline{z}_t}\left[||\overline{z}_t-z_\theta(\sqrt{\overline{\alpha}_t}x_0+\sqrt{1-\overline{\alpha}_t}\overline{z}_t,t)||^2\right]\]总结训练过程为:
- 获取输入$x_0$,从$1…T$随机采样一个$t$;
- 从标准高斯分布采样一个噪声$\bar{z}_t\thicksim \mathcal{N}(0,I)$;
- 最小化$\vert\vert\overline{z}t-z\theta(\sqrt{\overline{\alpha}_t}x_0+\sqrt{1-\overline{\alpha}_t}\overline{z}_t,t)\vert\vert$
最后是简要流程图:

采样和方差的选择(DDIM)
DDPM的高质量生成依赖于较大的$T$(一般为1000或以上),这就导致diffusion的前向过程非常缓慢。在denoising diffusion implicit model (DDIM)中提出了一种牺牲多样性来换取更快推断的手段。
根据独立高斯分布可加性,可以得到$x_{t-1}$为:
\[\begin{align} x_{t-1}&=\sqrt{\overline{\alpha}_{t-1}}x_0+\sqrt{1-\overline{a}_{t-1}}\overline{z}_{t-1}\\ &=\sqrt{\overline{\alpha}_{t-1}}x_0+\sqrt{1-\overline{\alpha}_{t-1}-\sigma_t^2}\overline{z}_t+\sigma_t z_t\\ &=\sqrt{\overline{\alpha}_{t-1}}x_0+\sqrt{1-\overline{\alpha}_{t-1}-\sigma_t^2}(\frac{x_t-\sqrt{\overline{a}_t}x_0}{\sqrt{1-\overline{\alpha}_t}})+\sigma_t z_t\\ q_\sigma(x_{t-1}|x_t,x_0)&=\mathcal{N}(x_{t-1};\sqrt{\overline{a}_{t-1}}x_0+\sqrt{1-\overline{\alpha}_{t-1}-\sigma^2_t}(\frac{x_t-\sqrt{\overline{a}_t}x_0}{\sqrt{1-\overline{\alpha}_t}}), \sigma_t^2\mathbf{I}) \end{align}\]这里将方差$\sigma^2t$引入均值汇总,当$\sigma^2_t=\tilde{\beta}_t=\frac{1-\bar{\alpha}{t-1}}{1-\bar{\alpha}t}\beta_t$时,等价于最初的$q(x{t-1}\vert x_t,x_0)$。这种经过贝叶斯的到$q_\theta(x_t\vert x_{t-1},x_0)$称为非马尔科夫过程,因为$x_t$的概率同时依赖于$x_{t-1}$和$x_0$。DDIM进一步定义了$\sigma_t(\eta)^2=\eta\cdot\tilde{\beta}_t$,当$\eta=0$时,diffusion的sample过程会丧失所有随机性从而得到一个deterministic的结果,当$\eta=1$时,则DDIM等价于DDPM。
对于方差$\sigma^2_t$的选择:
- DDPM
- $\sigma_{t,\theta}^2=\sum_\theta(x_t,t)$相当于模型学习的方差,DDPM没有实际使用但是GLIDE使用了;
- $\sigma_{t,s}^2=\tilde{\beta}t=\frac{1-\bar{\alpha}{t-1}}{1-\bar{\alpha}_t}\beta_t$,DDPM称为fixedsmall,用于celebahq和lsun;
- $\sigma^2{t,l}=\beta_t$,DDPM称为fixedlarge,用于cifar10,注意$\sigma{t,l}>\sigma_{t,s}$,fixedlarge的方差大于fixedsmall的。
- DDIM
$\sigma_t(\eta)^2=\eta\cdot \tilde{\beta}_t$,DDIM所选择的是基于fixedsmall版本上再乘以一个$\eta$。
假设总的采样步$T=1000$,间隔是$Q$,DDIM采样的步数为$S=T/Q$,$S$和$\eta$的实验结果如下:
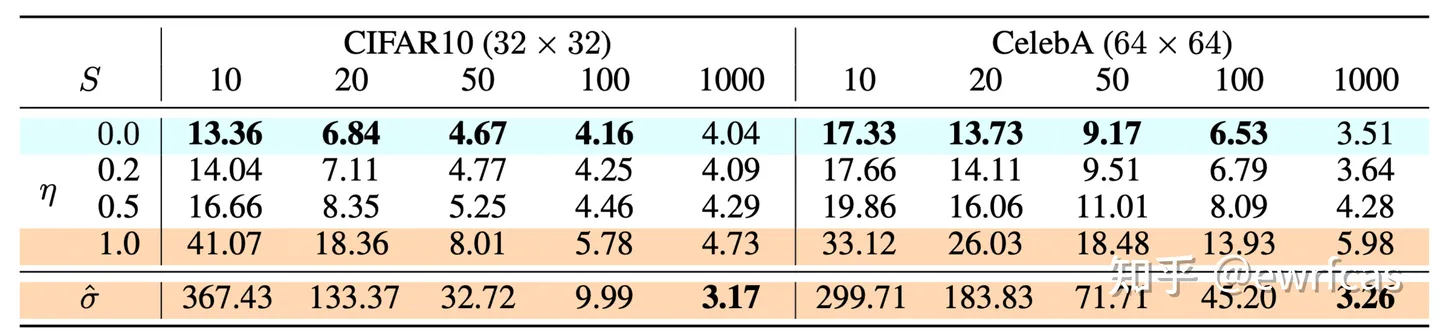
可以发现在$S$很小的时候$\eta=0$取得了最好的结果。值得一提的是,$\eta=1$是等价于DDPM的fixedsmall版本。而$\hat{\sigma}=\sqrt{\beta_t}$表示的是DDPM的fixedlarge版本。因此当$T$足够大的时候使用更大的方差$\sigma^2_t$能取得更好的结果。